sql中我们经常会用到聚合函数,聚合之后它会减少数据量,但是如果我们想把聚合之后的数据和原始数据同时展示出来,那么我们需要用到窗口函数。
lag窗口函数通过条件把数据划分成子类,在子类中进行排序
窗口函数的通用写法
select name ,orderdate, cost, sum(cost) over(partition by extract(month from orderdate) order by orderdate)
from order1;
over():将聚合函数添加到查询结果中
partition by:分成子类的条件
order by:将划分子类之后的数据进行排序(一般只有排序之后串口函数lag才能发挥他的作用)
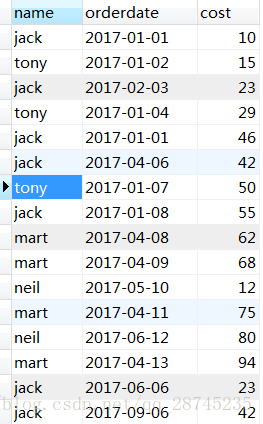
原始数据:
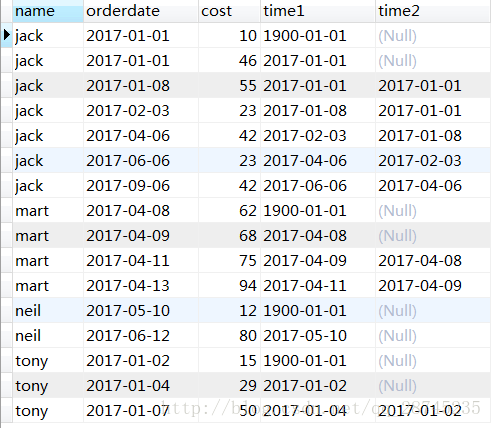
select name,orderdate,cost,
lag(orderdate,1,‘1900-01-01’) over(partition by name order by orderdate ) as time1,
lag(orderdate,2) over (partition by name order by orderdate) as time2
这是通过lag函数生成的两个聚合字段
lag中的参数
orderdate:代表以orderdate进行分组,默认组内升序(降序desc)
1:代表默认取上一个数据值(就是排序之后的上一个orderdate)
'1900-01-01':因为组内起始值肯定是没有前面的值的,也就是没办法取自己前面的值,默认为'1900-01-01',不写则为null
聚合之后的结果:
至于Lead函数则与lag函数相反
lag取前面的值
lead则是取后面的值
相信大家看了之后还是不明白他有什么用处,精髓就在于take以将聚合的数据和原始数据一同查询出来。
举个例子:
我们数据库中有一张百万级别的表,现在我们要查询,但是,需要A数据中的m字段于B数据中的字段进行运算,又恰好你的数据是有一定的规律进行运算的,当然通过表的自关联可以解决,但是对于一张数据量大的表来说,自关联可想而知,效率极低。我们就可以利用窗口函数,在表中直接进行分组排序,运算了。
本次创作借鉴
可以查看详情
链接:关于窗口函数的其他用法