由于最近在学习语音识别和语音合成方面的内容,整理了一些东西,本文为论文tacotron的笔记。
tacotron主要是将文本转化为语音,采用的结构为基于encoder-decoder的Seq2Seq的结构。其中还引入了注意机制(attention mechanism)。在对模型的结构进行介绍之前,先对encoder-decoder架构和attention mechanism进行简单的介绍。其中纯属个人理解,如有错误,请多多包含。
1.基于encoder-decoder的seq2seq的架构
由于在机器翻译中,我们输入的句子长度不是固定的。而对于一般的模型而言,输入的特征通常是一个固定大小的矩阵,这样就限制了我们输入的长度必须是一致的。但是这在翻译中很难保证,而Seq2Seq的结构正是为了解决这个问题。它的输入序列和输出序列的长度是不固定的。通常我们把RNN的输入称为“上下文”(context),我们希望通过encoder来产生此上下文的表示C。C有可能是一个概括了输入序列
其网络结构如下图所示:
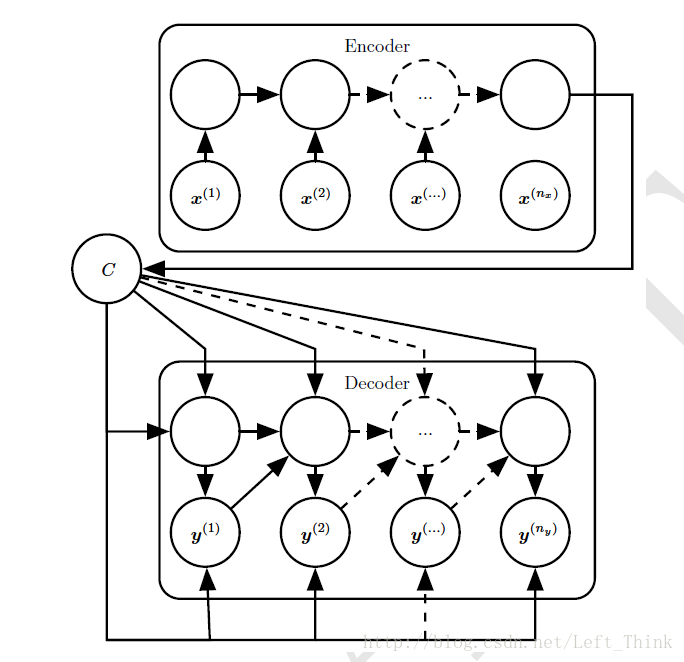
在Seq2Seq网络中通常分为两个部分:
编码器(encoder):它主要是处理RNN的输入序列,将最后一个RNN的单元状态来作为最终的输出的上下文C。
解码器(decoder):它以编码器的输出C作为输入,以固定长度的向量作为条件,产生输出序列
Y={y(1),y(2)...y(ny)} 。
这种encoder-decoder的架构的好处在于,它的输入序列的长度不需要和输出序列的长度保持一致。而这个架构也有一个不足之处就是encoder的输出上下文C的维度太小,因此它很难去概括一个长序列的所有语义细节信息。一个解决办法就是让C成为一个可变长度的序列,并引入注意机制(attention mechanism)。
2.注意机制(attention mechanism)
上文中提及到的Seq2Seq模型中,模型每次将encoder的输出作为上下文向量(概括了文本的所有信息的向量)输入到decoder中。这样我们在每次生成语音的时候,所使用的上下文向量是相同的,这样就不太好。
为什么会说这样不太好呢,举一个简单的例子:
- 如果输入的文本为:he had read this book. 那么模型在生成“he”这个单词中h的发音时,重点关注的应该是h、e以及空格。而在发read这个单词的ea部分的时候,则需要关注到之前的had 以及 read本身这两个单词。因为read的现在时和过去式长一样,但发音不相同。所以我们模型在每次生成语音时所关注的重点是不一样的,因此需要引入到attention机制。
还有一个问题就是使用固定长度大小的向量来概括一个较长句子的所有语义细节是十分困难的。一种高效的方法就是先读取完整个句子,来获得正在表达的上下文与其相关的焦点词,然后再每一次翻译一个词,在翻译单个词语的时候聚焦于句子的不同部分,来收集产生本次输出所需要的语义细节。
注意机制主要包括三个部分:
编码器:它用于读取原始数据(句子中的单词),并将其转化成分布式的表示,其中一个特征向量与一个单词相互对应,一般使用的结构有RNN,LSTM,GRU,bi-RNN等等;
存储器:主要用于存储编码器输出的特征向量列表;
解码器:利用存储器的内容,顺序的执行任务,每次任务聚焦于某个or几个(具有不同权重)的内容;
注意机制的结构如下图所示:
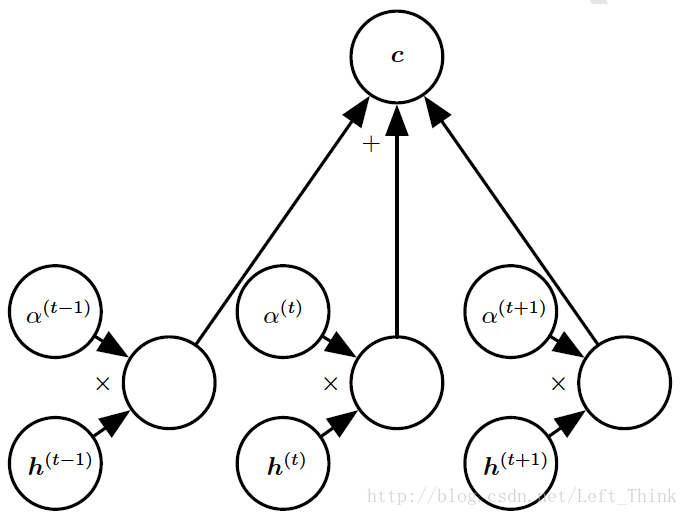
上下文向量
其中
需要在对这个权重向量做一些解释,这个权重向量在decoder每次进行预测时都不一样,计算方法如下:
其中的
说了这么多,个人对注意机制的理解就是在encoder-decoder结构中,在encoder把输入单词转化成向量的表示之后,每次对一个单词进行预测时,对encoder的输出赋予不同的权重,进行加权求和,再把其输入到编码器中。权重为0的位置,在此次预测时,我们便不关注,而对于那些权重值较大的位置,则是此次预测所关注的重点。这样也间接使C成为了可变长度的一个序列。
注意机制有一个缺点:计算起来较为复杂,假设翻译的句子长度为50,那么你的权重矩阵的的参数个数应该为50*50=2500,这还不算太糟,但是当你如果按照字符来进行操作,此时你的权重矩阵就要处理数以百计的序列,此时注意机制的代价就十分昂贵。
3.tacotron结构分析
讲完encoder-decoder结构和注意机制之后,再来看看tacotron网络的结构,如下图所示:
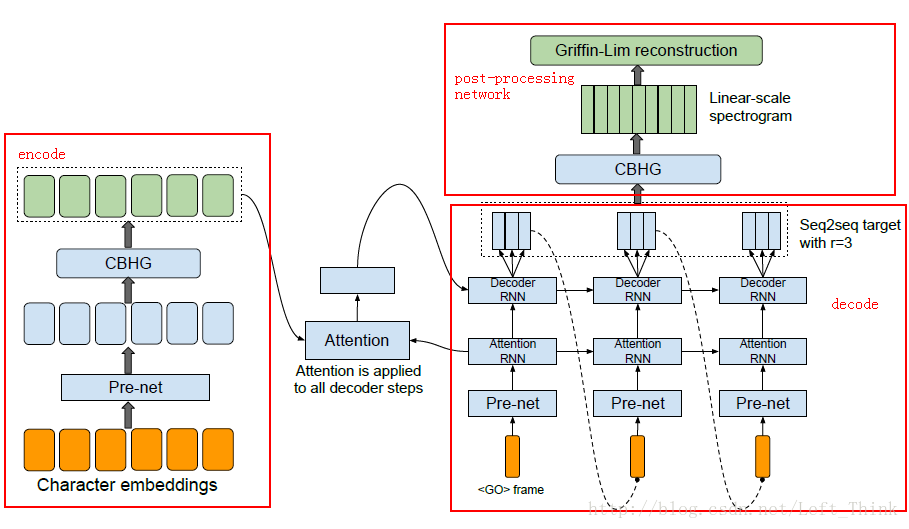
左边的红框标记的是encoder模块,右边下半部分的红框是decoder模块,连接encoder模块和decoder模块的就是attention machanism,最后右边的上半部分是模型的post-processing net(后处理网络模块)。
3.1 encoder模块
encoder模块主要是为了得到输入文本的一个很好的表示,encode的输入是将文本转换为one-hot向量,然后经过一个pre-net的网络结构,接着讲pre-net网络的输出输入到CBHG模块中,最后从CBHG中输出的就是输入的text的一个健壮的表示序列。
下面分别对pre-net和CBHG的结构进行介绍。
3.1.1 pre-net结构
pre-net是一个3层的网络结构,其主要功能是对输入进行一系列的非线性的变换,这样有助于模型收敛和泛化。
它有两个隐藏层,层与层之间的连接均是全连接;第一层的隐藏单元数目与输入单元数目一致,第二层的隐藏单元数目为第一层的一半;两个隐藏层采用的激活函数均为ReLu,并保持0.5的dropout来提高泛化能力。
基于tensorflow实现prenet的代码:
'''
inputs: 输入的tensor, 形状为[N, T, 256], 其中N为batch_size, T为输入文本的长度;
is_training: 布尔值, 表示是否为训练过程;
layer_size: 表示prenet一共有两层隐藏层,第一层有256个隐藏单元,第二层有128个隐藏单元
'''
def prenet(inputs, is_training, layer_sizes=[256, 128], scope=None):
x = inputs
# 定义dropout大小(只有在训练时才会dropout)
drop_rate = 0.5 if is_training else 0.0
with tf.variable_scope(scope or 'prenet'):
# 循环两次,经过两个全连接层
for i, size in enumerate(layer_sizes):
# 定义全连接层
dense = tf.layers.dense(x, units=size, activation=tf.nn.relu, name='dense_%d' % (i+1))
# dropout
x = tf.layers.dropout(dense, rate=drop_rate, name='dropout_%d' % (i+1))
# 输出x的形状为[N, T, 128]
return x3.1.2 CBHG结构
CBHG结构最初源于机器翻译中,主要用于提高模型的泛化能力。它的结构如下图所示:
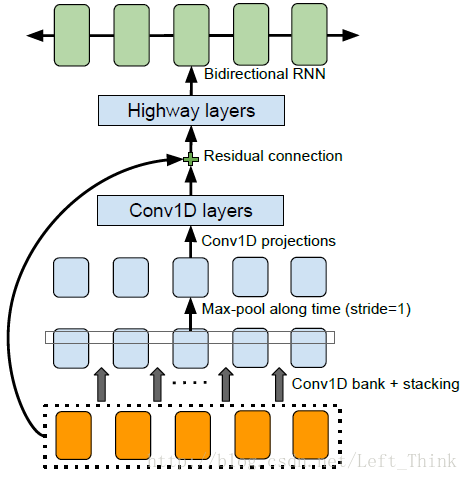
输入序列首先会经过一个卷积层,注意这个卷积层,它有K个大小不同的1维的filter,其中filter的大小为1,2,3…K。这些大小不同的卷积核提取了长度不同的上下文信息。然后,将经过不同大小的k个卷积核的输出堆积在一起(注意:在做卷积时,运用了padding,因此这k个卷积核输出的大小均是相同的)。下一层为最大池化层,stride为1,width为2。
经过池化之后,会再经过两层一维的卷积层。第一个卷积层的filter大小为3,stride为1,采用的激活函数为ReLu;第二个卷积层的filter大小为3,stride为1,没有采用激活函数(在这两个一维的卷积层之间都会进行batch normalization)。
经过卷积层之后,会进行一个residual connection。也就是把卷积层输出的和embeding之后的序列相加起来。然后输入到highway layers,highway nets的每一层结构为:把输入同时放入到两个一层的全连接网络中,这两个网络的激活函数分别采用了ReLu和sigmoid函数,假定输入为input,ReLu的输出为output1,sigmoid的输出为output2,那么highway layer的输出为:
highway layer的实现代码:
def highwaynet(inputs, scope):
with tf.variable_scope(scope):
# 定义一个使用 ReLu 为激活函数的全连接层,包含128个隐藏单元
H = tf.layers.dense(
inputs,
units=128,
activation=tf.nn.relu,
name='H')
# 定义一个使用 sigmoid 为激活函数的全连接层,包含128个隐藏单元
T = tf.layers.dense(
inputs,
units=128,
activation=tf.nn.sigmoid,
name='T',
bias_initializer=tf.constant_initializer(-1.0))
# 返回 highway layer 的输出
return H * T + inputs * (1.0 - T)最后将highway net的输出输入到双向RNN当中,从RNN中输出的结果就是encoder的输出。
基于tensorflow实现CBHG的代码:
'''
inputs: 输入的tensor(也是prenet的输出), 形状为[N, T, 128], 其中N为batch_size, T为输入文本的长度;
input_lengths: 输入的文本的长度;形状为[N], 代表一个batch中每一条文本的长度组成的向量, N代表batch_size;
is_training: 布尔值, 表示是否为训练过程;
K: int型, 表示第一层卷积里卷积核的个数;
projections: 代表第二个卷积层中每次卷积之后输出的长度
'''
def cbhg(inputs, input_lengths, is_training, scope, K, projections):
with tf.variable_scope(scope):
with tf.variable_scope('conv_bank'):
# Convolution bank: concatenate on the last axis to stack channels from all convolutions
# 通过concat把k个卷积的feature map堆起来,输出形状为[N, T, k*128]
conv_outputs = tf.concat(
[conv1d(inputs, k, 128, tf.nn.relu, is_training, 'conv1d_%d' % k) for k in range(1, K+1)],
axis=-1
)
# Maxpooling: 输出形状为[N, T, k*128]
maxpool_output = tf.layers.max_pooling1d(
conv_outputs,
pool_size=2,
strides=1,
padding='same')
# 两个卷积层, 3代表卷积核的大小, 这里projections为[128, 128], 输出形状为[N, T, 128]
proj1_output = conv1d(maxpool_output, 3, projections[0], tf.nn.relu, is_training, 'proj_1')
proj2_output = conv1d(proj1_output, 3, projections[1], None, is_training, 'proj_2')
# Residual connection: 将经过卷积层的输出和prenet的输出求和
highway_input = proj2_output + inputs
# 处理highway net输出不匹配的情况,通过一个全连接层把输出变成[N, T, 128]
if highway_input.shape[2] != 128:
highway_input = tf.layers.dense(highway_input, 128)
# 4-layer HighwayNet:
for i in range(4):
highway_input = highwaynet(highway_input, 'highway_%d' % (i+1))
rnn_input = highway_input
# Bidirectional RNN
outputs, states = tf.nn.bidirectional_dynamic_rnn(
GRUCell(128),
GRUCell(128),
rnn_input,
sequence_length=input_lengths,
dtype=tf.float32)
return tf.concat(outputs, axis=2) # Concat forward and backward3.2 decoder模块
decoder模块主要分为三部分:pre-net、Attention-RNN、Decoder-RNN。
pre-net的结构与encoder中的pre-net相同,主要是对输入做一些非线性变换。
Attention-RNN的结构为一层包含256个GRU的RNN,它将pre-net的输出和attention的输出作为输入,经过GRU单元后输出到decoder-RNN中。
decode-RNN为两层residual GRU,它的输出为输入与经过GRU单元输出之和。每层同样包含了256个GRU单元。第一步decoder的输入为0矩阵,之后都会把第t步的输出作为第t+1步的输入。
注意:由于每个字符在发音的时候,可能对应了多个帧,因此每个GRU单元输出为多个帧的音频文件,paper上说在decoder的每一步时,不仅仅预测1帧的数据,而是预测多个费重叠的帧。
这样的好处有:
减少了训练模型的大小;
减少了训练的时间;
可以提高收敛的速度。
3.3 post-processing模块
在decoder-RNN输出之后并没有直接将输出转化为音频文件,而是又添加了后处理的网络。后处理的网络可以在一个线性频率范围内预测幅度谱(spectral magnitude),并且后处理网络能看到整个解码的序列,而不像seq2seq那样,只能从左至右的运行。后处理网络可以通过反向传播来修正每一帧的错误。paper中使用了CBHG的结构来作为post-processing net。
最后使用Griffin-Lim算法来将post-processing net的输出合成为语音。
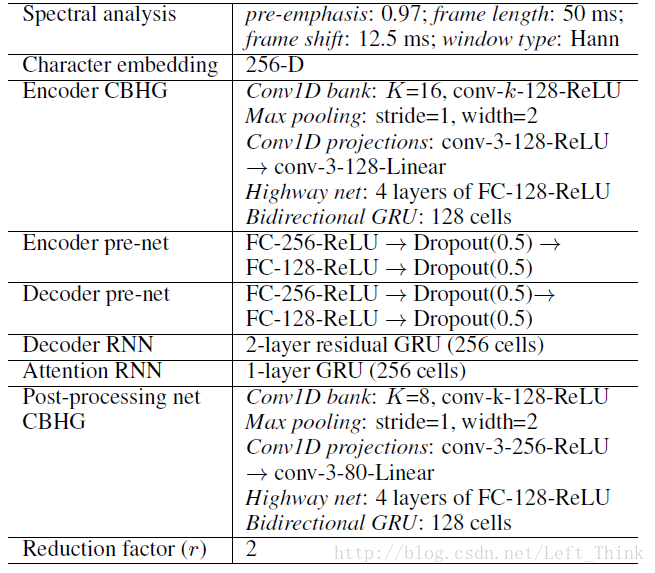
文章的部分超参数和网络结构如下图所示:
关于tacotron的介绍就到这里啦,欢迎各位指点~~
附上使用tensorflow实现的tacotron的地址。
附录
在这里记录一下我训练tacotron模型的一些坑,希望能对大家有所帮助吧!
- 训练速度:在开始的时候,人很傻,直接拿音频文件来进行训练。因为模型训练不是直接拿音频作为输入进行训练,而在之前还对音频进行了一些计算过程。因此在训练时,每次一次输入音频都要做一次计算才输入到我们的网络中。后来参考github上的一些人的建议,提前将音频处理好,输出为.npy文件。然后再在训练时将.npy文件,然后采用队列的形式,一次读入一个batch的数据传给GPU。这样训练速度相比之前拿音频进行训练提升了20%左右;
- 数据的预处理:在训练英文的tacotron时,会发现有一些英文的缩写,但是发音还是按照完整的单词来读的,比如:Mr,Dc等等。因此在训练之前要将一些常用的英文缩写还原成对应的单词;还有就是对于阿拉伯数字和一些符号比如”$”、”.”,我们也要将其还原成对应的单词;
- 静音的处理:在训练之前,需要对音频文件去除其开头与结尾部分的静音。这样做对模型训练的收敛速度有很大的提升;
- 输入文本中的符号的处理:tacotron模型时可以学习出标点符号的停顿和发音的,因此我们保留了几个常用的标点符号,将其与单词一样embedding我词向量输入到网络中;
- 使用音素进行训练:在训练完tacotron后,我还尝试了使用英文的音素进行训练,也就是将英文单词转化为英文的音素。发现训练同样的轮数,使用英文的音素训练处的模型的效果要比英文单词要好;
- 在训练过程中会产生梯度爆炸的现象:不知道是attention机制的弊端还是怎么地的,在训练过程中偶尔会出现梯度爆炸的现象,虽然在之后loss还是会降下来,但是这样浪费了大量的训练时间,因此在优化的时候采用clipped_gradient,这样可以有效的避免梯度爆炸或者梯度消失的现象;
- 对于合成较长的音频,模型效果并不是太好:这是因为我们训练集的音频长度都是在1s-10s之间。所以在对于较长的文本,末尾部分的发音可能不太好。有两种方法解决这个问题,第一种就是在数据集中添加较长的文本和音频进行训练;第二种方法你可以在测试的时候对文本进行判断,但文本长度较长时,可以按照符号进行切割,分成好几个部分进行预测,最后再拼接起来。第二种方法在拼接处可能听起来会不太自然。
- 最近去jd面试,他们也在使用这个模型做语音合成。对于语音合成,他们想要做实时合成。而使用的Griffin-Lim是基于CPU实现的,进行合成还没有到达实时的地步。一个想法是使用百度DeepVoice里的使用wavenet代替Griffin-Lim算法合成语音。另一个是写一个基于GPU的Griffin-Lim合成算法。