2021_VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
1.论文总结
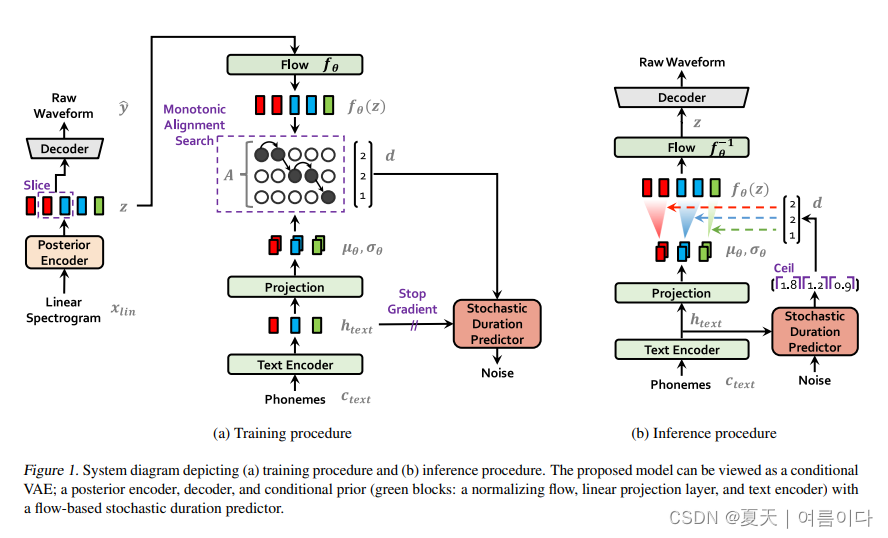
提出一种TTS模型框架VITS,用到normalizing flow和对抗训练方法,提高合成语音自然度,其中论文结果上显示已经和GT相当。是结合了VAE和FLOW的新架构。
在俩各数据集中的实验结果
论文的主要贡献:
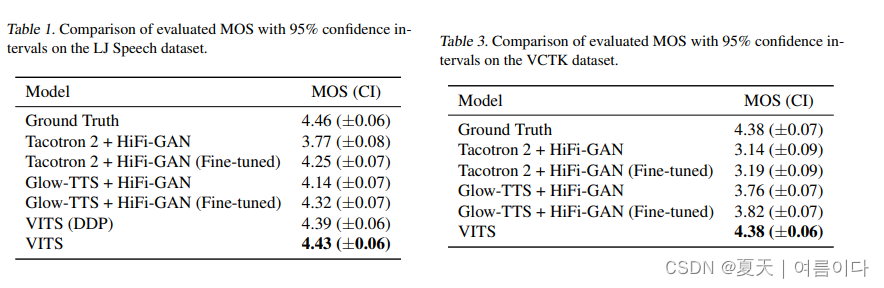
- 首个自然度超过2-stage架构SOTA的完全E2E模型。MOS4.43, 仅低于GT录音0.03。
- 得益于图像领域中把Flow引入VAE提升生成效果的研究,成功把Flow-VAE应用到了完全E2E的TTS任务中。
- 训练非常简便,完全E2E。不需要像Fastspeech系列模型需要额外提pitch, energy等特征,也不像多数2-stage架构需要根据声学模型的输出来finetune声码器以达到最佳效果。
- 摆脱了预设的声学谱作为链接声学模型和声码器的特征,成功的应用来VAE去E2E的学习隐性表示来链接两个模块。
- 多人模型自然度不下降,不像其他模型趋于持平GT录音MOS分。
2.论文项目实现
2.0.环境设置
git clone https://github.com/jaywalnut310/vits
cd vits
# 建议3.7
conda create -n vits python==3.7
apt-get install espeak
pip install -r requirements.txt
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplace2.1.数据集准备
原论文中实验了俩个数据集
- LJSpeech(单人,英语)
- VCTK(多人,英语)
本文只实现多人语音合成,下载VCTK数据集【下载网址】
数据集1:LJSpeech-1.1
如果使用LJ语音数据集,下载并提取 LJ 语音数据集,然后重命名或创建指向数据集文件夹的链接:
ln -s /path/to/LJSpeech-1.1/wavs DUMMY1数据集2:VCTK
点击下载所有文件【Download all files】后,(下载大约5h)
上传到服务器,放到项目路径下:自己新建的data,然后解压缩后如图
再将数据进行处理
# 方法 2 :把flac结尾的,替换为wav文件,然后对wav文件进行重采样(48000->22050),运行后保存为新的地址,所有文件都在同一文件夹下
import os
import librosa
import tqdm
import soundfile as sf
if __name__ == '__main__':
audioExt = 'flac'
outputExt = 'wav'
input_sample = 48000
output_sample = 22050
audioDirectory = ['/workspace/tts/vits/data/wav48_silence_trimmed']
outputDirectory = [ '/workspace/tts/vits/DUMMY2']
for i, dire in enumerate(audioDirectory):
# 寻找"directory"文件夹中,格式为“ext”的音频文件,返回值为绝对路径的列表类型
clean_speech_paths = librosa.util.find_files(
directory=dire,
ext=audioExt,
recurse=True,
)
for file in tqdm.tqdm(clean_speech_paths, desc='No.{} dataset resampling'.format(i)):
fileName = os.path.basename(file)
print(fileName)
if audioExt in fileName:
fileName=fileName.replace(audioExt,outputExt)
y, sr = librosa.load(file, sr=input_sample)
y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)
outputFileName = os.path.join(outputDirectory[i], fileName)
sf.write(outputFileName, y_16k, output_sample)
将 wav 文件缩减采样至 22050 Hz。然后重命名或创建指向数据集文件夹:
ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2在克隆的项目中,已经有对齐好的数据文件。
此时

需要将数据变为wav文件并采样到22050Hz
所需训练数据
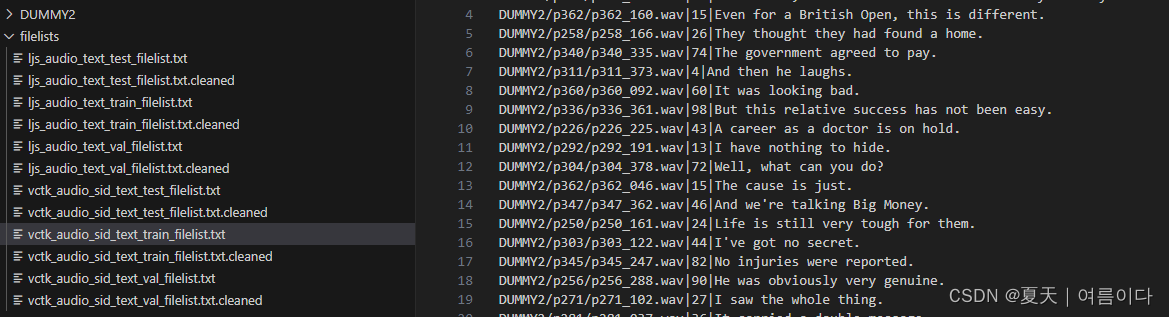
数据处理后的,投入训练的数据
数据集3:自己的数据集
构建单调对齐搜索并运行预处理(如果使用自己的数据集)。
vits数据集需要指定的格式才能识别,如下图是多人训练中日混合模型的格式,本教程也是针对下载的数据集,如何整理成需要的格式,做一个简单入门教程。
数据预处理
# Cython-version Monotonoic Alignment Search
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt 
2.2.训练
# LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_base2.3.推理
自己稍微修改后的推理文件 inference.py
import matplotlib.pyplot as plt
import IPython.display as ipd
import os
import json
import math
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
import commons
import utils
from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate
from models import SynthesizerTrn
from text.symbols import symbols
from text import text_to_sequence
from scipy.io.wavfile import write
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
####################### LJSpeech ###########################
hps = utils.get_hparams_from_file("./configs/ljs_base.json")
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
**hps.model).cuda()
_ = net_g.eval()
stn_tst = get_text("VITS is Awesome!", hps)
with torch.no_grad():
x_tst = stn_tst.cuda().unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()
audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()
ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))
_ = utils.load_checkpoint("/path/to/pretrained_ljs.pth", net_g, None)
####################### VCTK ###########################
hps = utils.get_hparams_from_file("./configs/vctk_base.json")
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model).cuda()
_ = net_g.eval()
_ = utils.load_checkpoint("/path/to/pretrained_vctk.pth", net_g, None)
stn_tst = get_text("VITS is Awesome!", hps)
with torch.no_grad():
x_tst = stn_tst.cuda().unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()
sid = torch.LongTensor([4]).cuda()
audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()
ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))
####################### Voice Conversion ###########################
dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)
collate_fn = TextAudioSpeakerCollate()
loader = DataLoader(dataset, num_workers=8, shuffle=False,
batch_size=1, pin_memory=True,
drop_last=True, collate_fn=collate_fn)
data_list = list(loader)
with torch.no_grad():
x, x_lengths, spec, spec_lengths, y, y_lengths, sid_src = [x.cuda() for x in data_list[0]]
sid_tgt1 = torch.LongTensor([1]).cuda()
sid_tgt2 = torch.LongTensor([2]).cuda()
sid_tgt3 = torch.LongTensor([4]).cuda()
audio1 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt1)[0][0,0].data.cpu().float().numpy()
audio2 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt2)[0][0,0].data.cpu().float().numpy()
audio3 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt3)[0][0,0].data.cpu().float().numpy()
print("Original SID: %d" % sid_src.item())
ipd.display(ipd.Audio(y[0].cpu().numpy(), rate=hps.data.sampling_rate, normalize=False))
print("Converted SID: %d" % sid_tgt1.item())
ipd.display(ipd.Audio(audio1, rate=hps.data.sampling_rate, normalize=False))
print("Converted SID: %d" % sid_tgt2.item())
ipd.display(ipd.Audio(audio2, rate=hps.data.sampling_rate, normalize=False))
print("Converted SID: %d" % sid_tgt3.item())
ipd.display(ipd.Audio(audio3, rate=hps.data.sampling_rate, normalize=False))如果处理自己的数据集:
# Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
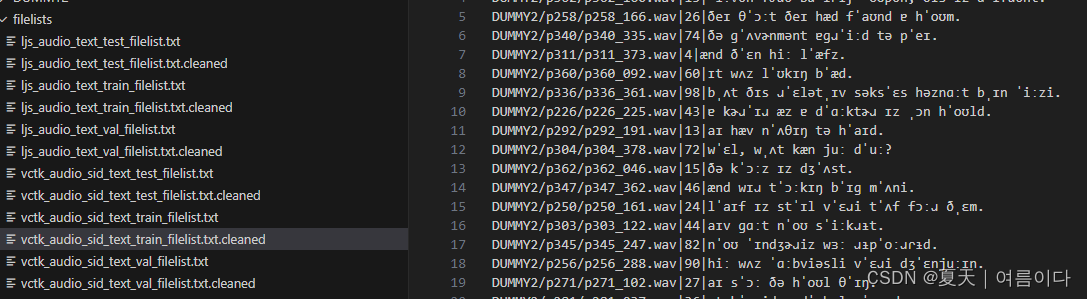
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt在本文中已经对数据集VCTK处理完了,如图

分别是语音路径,人员编号,预处理后的文本文件。
3.代码详解
VITS由于采用对抗训练的模式,模型主要包括生成器net_g和判别器net_d两大块,判别器仅在训练时使用。具体实现上,生成器net_g由SynthesizerTrn实现,包括先验编码器、随机时长预测器、解码器和后验编码器;判别器net_d由MultiPeriodDiscriminator实现,即HiFiGAN中的多周期判别器。
config.json
train训练部分
eval_interval为全权重保存间隔,这里按照默认的1000即可以满足保存的需求,设置过小会训练过程会耗费大量时间在保存上;设置过大如果训练出现问题无法满足及时保存最近的模型的需求。 epochs迭代次数,一般来说比较好的数据集质量不到一千合成也基本比较自然,作者建议一万,有时间还是建议一万。
data数据部分
是经过预处理的数据集文件
text_cleaners 是对文本的处理方法,中文chinese_cleaners,英文english_cleaners等等(处理方法不同,有声学和音素方法)
n_speakers说话人数,单人为0,多人按人物个数。
train_ms.py
VITS训练时,使用了混合精度训练,并且设置了对抗训练模式;其中判别器使用了多周期判别器,由多个子判别器组成,并且生成过程损失中还加上了feature_map损失。训练过程中,不是对完整的音频文件进行训练,而是提取一部分音频数据进行训练,进而在计算损失时,也要从ground truth中提取对应部分的数值进行计算。
losses.py
模型训练过程中涉及很多的损失,对抗训练过程中,判别器是常规的判别器损失结构,但是使用的是多周期判别器,由多个子判别器组成;生成器的损失,包括mel重建损失、KL散度、时长预测器损失、对抗训练生成损失以及特征图损失,其中时长预测器损失在模型forward函数中直接计算、mel重建损失是直接计算L1损失,剩下的四种损失在losses.py文件中定义,
过程中遇到的错误及改正【PS】
【PS1】ModuleNotFoundError: No module named 'monotonic_align.monotonic_align'
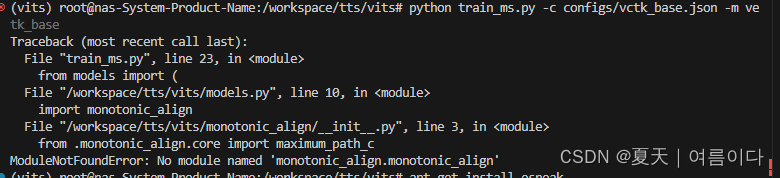
pip install monotonic_align
cd monotonic_align/
python setup.py build_ext --inplace
使用
python setup.py install

再次运行后,出现
error: could not create 'monotonic_align/core.cpython-38-x86_64-linux-gnu.so': No such file or directory
重新新建了一个环境

运行后出现
Segmentation fault (core dumped)

参考文献
【1】VITS 语音合成完全端到端TTS的里程碑_Terry_ZzZzZz的博客-CSDN博客
【2】细读经典:VITS,用于语音合成带有对抗学习的条件变分自编码器 - 知乎
请遵守相关法律
第一千零一十八条 自然人享有肖像权,有权依法制作、使用、公开或者许可他人使用自己的肖像。
肖像是通过影像、雕塑、绘画等方式在一定载体上所反映的特定自然人可以被识别的外部形象。
第一千零一十九条 任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。
未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。
第一千零二十条 合理实施下列行为的,可以不经肖像权人同意:
(一)为个人学习、艺术欣赏、课堂教学或者科学研究,在必要范围内使用肖像权人已经公开的肖像;
(二)为实施新闻报道,不可避免地制作、使用、公开肖像权人的肖像;
(三)为依法履行职责,国家机关在必要范围内制作、使用、公开肖像权人的肖像;
(四)为展示特定公共环境,不可避免地制作、使用、公开肖像权人的肖像;
(五)为维护公共利益或者肖像权人合法权益,制作、使用、公开肖像权人的肖像的其他行为。
第一千零二十一条 当事人对肖像许可使用合同中关于肖像使用条款的理解有争议的,应当作出有利于肖像权人的解释。
第一千零二十二条 当事人对肖像许可使用期限没有约定或者约定不明确的,任何一方当事人可以随时解除肖像许可使用合同,但是应当在合理期限之前通知对方。
当事人对肖像许可使用期限有明确约定,肖像权人有正当理由的,可以解除肖像许可使用合同,但是应当在合理期限之前通知对方。因解除合同造成对方损失的,除不可归责于肖像权人的事由外,应当赔偿损失。
第一千零二十三条 对姓名等的许可使用,参照适用肖像许可使用的有关规定。
对自然人声音的保护,参照适用肖像权保护的有关规定。