常规O(nlogn)就不谈了。
基数排序
O(n*maxLen),maxLen为所有字符串里的最长长度。
思路
代码中的 beginCh 为 输入的字符串里ascii最小的可能字符 的上一个字符。
为方便说明,这里先假设输入的字符都是大写字母,此时输入里的最小字符是A(ASCII为65), beginCh 是 @ (ASCII为64)。
排序规则像排整数一样从最低位开始,不够的部分用 beginCh 补全,如
ACM
AC
排序时是使用 ACM 和 AC@ 来计数,从 M 和@ 开始排一次,然后 C 和C ,再 A 和A。
小坑
beginCh要用@而非A的原因:用A的话就不能确保ABCA
AB
ABC这种数据的顺序,因为排的时候
ABCA和ABC都被当作ABCA来看待了,由于基数排序调用了稳定排序,会出现排序结果跟输入的字符串顺序有关的情况。- 千万小心
str.length()和k的比较,如果是直接str.length() - k的话会导致结果错误,因为str.length()是unsigned long而非signed long,无符号数和有无符号运算时会将结果转为无符号数。
实现
#include <stdio.h>
#include <string>
#include <cmath>
#include <cstring>
#include <iostream>
using namespace std;
const int maxCh = 100; //空格起为可打印字符
const char beginCh = ' ' - 1; //-1是因为数据有空格的情况下 ac和ac空格 的排序结果是无法确保的
void rSort(string s1[], int n) {
string *tmp = new string [n];
int *cnt = new int [maxCh];
int maxLen = 0;
for (int i = 0; i < n; ++i) {
maxLen = max(maxLen, (int)s1[i].length());
}
for (int k = maxLen - 1; k >= 0; --k) {
memset(cnt, 0, sizeof(int)*maxCh);
for (int i = 0; i < n; ++i) {
char ch = (int)s1[i].length() > k ? s1[i][k] : beginCh;
cnt[ ch - beginCh] ++;
}
for (int i = 1; i < maxCh; ++i) {
cnt[i] += cnt[i - 1];
}
for (int i = n - 1; i >= 0; --i) {
char ch = (int)s1[i].length() > k ? s1[i][k] : beginCh;
tmp[ cnt[ch - beginCh] - 1] = s1[i];
cnt[ch - beginCh]--;
}
for (int i = 0; i < n; ++i) {
s1[i] = tmp[i];
}
}
delete[] tmp; delete[] cnt;
}
int main() {
freopen("in.txt","r",stdin);
// freopen("out.txt","w",stdout);
string s1[1234];
int n = 0;
while (cin >> s1[n])n++;
rSort(s1, n);
for (int i = 0; i < n; ++i) {
cout << s1[i] << endl;
}
return 0;
}Trie树排序
优点还是Trie树的优点:省空间~~,不过新建结点时new操作不少,速度稍慢。
插入建树时O(n*len),排序时需要深搜一次O(m):m为树的结点数。
Trie树 稍作修改即可实现排序,每个结点存根结点到当前所组成的字符串,并且加个标记位表示是不是字符串结尾,这样的话深搜一次即可按顺序访问所有结点。
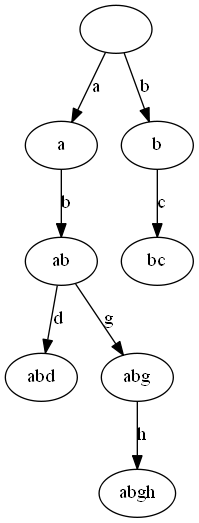
因为挺简单的,直接上代码
//图片的Graphviz代码
digraph G{
" "->"a"[label = "a"]
"a"->"ab"[label = "b"]
"ab"->"abd"[label = "d"]
"ab"->"abg"[label = "g"]
"abg"->"abgh"[label = "h"]
" "->"b"[label = "b"]
"b"->"bc"[label = "c"]
}
实现
#include <cstdio>
#include <cstring>
#include <string>
#include <iostream>
#include <algorithm>
using namespace std;
class TrieSort {
public:
void init() {
rt = new node();
}
void insert(string str) {
insert(rt, str);
}
void sort(string strArray[]) {
int sCnt = 0;
sort(rt, strArray, sCnt);
}
//按序输出,不改变原数据
void printSorted() {
printSorted(rt);
}
private:
enum {charestNum = 100,beginCh = ' '};
struct node
{
node *next[charestNum + 1];
string cur;
int cnt;
node() {
cur = "";
memset(next,0,sizeof(next));
cnt = 0;
}
};
node *rt;
void insert(node *p, string s1) {
for (int i = 0; i < s1.length(); ++i) {
int k = s1[i] - beginCh;
if (!p->next[k])
p->next[k] = new node();
p->next[k]->cur = p->cur + s1[i];
p = p->next[k];
}
p->cnt ++;
}
void printSorted(node *p) {
while (p->cnt > 0) {cout << p->cur << endl; p->cnt--;}
for (int i = 0; i < charestNum; ++i) {
if (p->next[i]) {
printSorted(p->next[i]);
}
}
}
void sort(node *p, string ans[], int& sCnt) {
while (p->cnt > 0) {ans[sCnt++] = p->cur ; p->cnt--;}
for (int i = 0; i < charestNum; ++i) {
if (p->next[i]) {
sort(p->next[i], ans, sCnt);
}
}
}
} trie;
int main()
{
freopen("in.txt", "r", stdin);
// freopen("out.txt","w",stdout);
string s1[200];
int n = 0;
trie.init();
while (cin >> s1[n]) {trie.insert(s1[n]); n++;}
// trie.printSorted();
trie.sort(s1);
for (int i = 0; i < n; ++i) {
cout << s1[i] << endl;
}
return 0;
}
用来对拍的库排序
#include <cstdio>
#include <cstring>
#include <string>
#include <iostream>
#include <algorithm>
using namespace std;
#define RE freopen("in.txt","r",stdin);
#define WE freopen("out.txt","w",stdout);
int main() {
freopen("in.txt", "r", stdin);
freopen("out.txt", "w", stdout);
string s1[100];
int n = 0;
while (cin >> s1[n])n++;
sort(s1, s1 + n);
for (int i = 0; i < n; ++i) {
cout << s1[i] << endl;
}
return 0;
}数据生成
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//生成n行可打印字符
int main() {
int i, a, b, n, k;
freopen("in.txt", "w", stdout);
srand((int)time(NULL));
a = 1;
b = 60;
for (i = 0; i < 20; i++) { //数据组数
n = a + rand() % (b - a); //长度
// printf("%d\n", n);
for (int j = 0; j < n; ++j) {
printf("%c", 33 + rand() % 92);
}
printf("\n");
}
return 0;
}