这一周开始接触RCNN相关的技术,希望用它来进行物体定位方面的研究。现记录一些学习心得,以备查询。——jeremy@gz
关于Fast-RCNN的解析,我们将主要分为两个部分来介绍,其中一个是训练部分,这个部分非常重要,是我们需要重点讲解的;另一个是测试部分,这个部分关系到具体的应用,所以也是必须要了解的。本篇博文中,我们先从训练部分讲起。
训练阶段流程
在官方文档中,训练阶段的启动脚本如下所示:
./tools/train_net.py --gpu 0 --solver models/VGG16/solver.prototxt \
--weights data/imagenet_models/VGG16.v2.caffemodel从这段脚本中,我们可以知道,训练的入口函数就在train_net.py中,其位于fast-rcnn/tools/文件夹内,我们先来看看这个文件。
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
if args.cfg_file is not None:
cfg_from_file(args.cfg_file)
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)
print('Using config:')
pprint.pprint(cfg)
if not args.randomize:
# fix the random seeds (numpy and caffe) for reproducibility
np.random.seed(cfg.RNG_SEED)
caffe.set_random_seed(cfg.RNG_SEED)
# set up caffe
caffe.set_mode_gpu()
if args.gpu_id is not None:
caffe.set_device(args.gpu_id)
imdb = get_imdb(args.imdb_name)
print 'Loaded dataset `{:s}` for training'.format(imdb.name)
roidb = get_training_roidb(imdb)
output_dir = get_output_dir(imdb, None)
print 'Output will be saved to `{:s}`'.format(output_dir)
train_net(args.solver, roidb, output_dir,
pretrained_model=args.pretrained_model,
max_iters=args.max_iters)从以上的code,我们可以看到,train_net.py的主要处理过程包括以下三个部分:
(1) 首先对启动脚本的输入参数进行处理,是通过如下这个函数parse_args()进行处理的。
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument('--gpu', dest='gpu_id',
help='GPU device id to use [0]', default=0, type=int)
parser.add_argument('--solver', dest='solver',
help='solver prototxt', default=None, type=str)
parser.add_argument('--iters', dest='max_iters',
help='number of iterations to train',default=40000, type=int)
parser.add_argument('--weights', dest='pretrained_model',
help='initialize with pretrained model weights', default=None, type=str)
parser.add_argument('--cfg', dest='cfg_file',
help='optional config file',default=None, type=str)
parser.add_argument('--imdb', dest='imdb_name',
help='dataset to train on',default='voc_2007_trainval', type=str)
parser.add_argument('--rand', dest='randomize',
help='randomize (do not use a fixed seed)',action='store_true')
parser.add_argument('--set', dest='set_cfgs',
help='set config keys', default=None,nargs=argparse.REMAINDER)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args从这个函数中,我们可以了解到,训练脚本的可选输入参数包括:
- –gpu: 这个参数指定训练使用的GPU设备,我的电脑只有一枚GPU,默认情况下自动开启,其gpu_id为0;
- –solver: 这个参数指定网络的优化方法,并在其solver的prototxt指向了定义网络结构的文件(train.prototxt);
- –weights: 这个参数指定了finetune的初始参数,我的电脑GPU不怎么高端,只能使用caffenet进行finetune;
- –imdb: 这个参数指定了训练所需要的训练数据,如果你需要训练自己的数据,那么这个参数是必须要指定的;
(2) 然后是根据输入的参数(–imdb 参数后面指定的数据)来准备训练样本,这个步骤涉及到两个函数:一个 imdb=get_imdb(args.imdb_name) , 另一个是roidb=get_training_roidb(imdb)。关于这两个函数我们下部分会花大时间来解析,这里先不谈。
(3) 最后就是训练函数:train_net(args.solver,roidb, output_dir, pretrained_model= args.pretrained_model, max_iters= args.max_iters)
而这个 train_net() 函数是从 fast_rcnn/lib/fast_rcnn 文件夹中的 train.py 中 import 进来的。那么接下来,我们来看看这个train.py
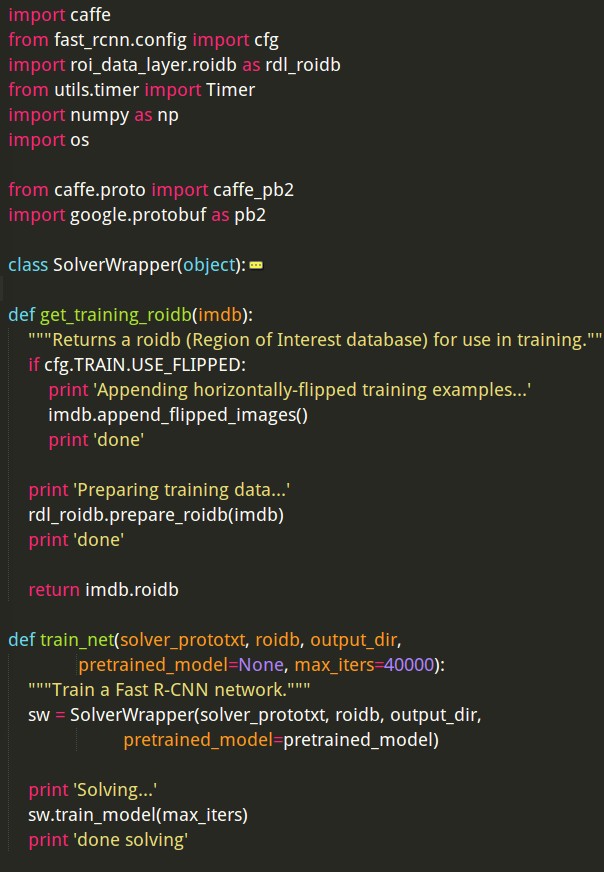
这个函数主要由一个类SolverWrapper和两个函数get_training_roidb()和train_net()组成。
首先,我们来看看train_net()函数:
def train_net(solver_prototxt, roidb, output_dir,
pretrained_model=None, max_iters=40000):
"""Train a Fast R-CNN network."""
sw = SolverWrapper(solver_prototxt, roidb, output_dir,
pretrained_model=pretrained_model)
print 'Solving...'
sw.train_model(max_iters)
print 'done solving'可以发现,该函数是通过调用类SolverWrapper来实现其主要功能的,因此,我们跟进到类SolverWrapper的类构造函数中去:
def __init__(self, solver_prototxt, roidb, output_dir,
pretrained_model=None):
"""Initialize the SolverWrapper."""
self.output_dir = output_dir
print 'Computing bounding-box regression targets...'
self.bbox_means, self.bbox_stds = \
rdl_roidb.add_bbox_regression_targets(roidb)
print 'done'
self.solver = caffe.SGDSolver(solver_prototxt)
if pretrained_model is not None:
print ('Loading pretrained model '
'weights from {:s}').format(pretrained_model)
self.solver.net.copy_from(pretrained_model)
self.solver_param = caffe_pb2.SolverParameter()
with open(solver_prototxt, 'rt') as f:
pb2.text_format.Merge(f.read(), self.solver_param)
self.solver.net.layers[0].set_roidb(roidb)初始化完成后,就是要调用train_model函数来进行网络训练,我们来看一下它的主体部分:
def train_model(self, max_iters):
"""Network training loop."""
last_snapshot_iter = -1
timer = Timer()
while self.solver.iter < max_iters:
# Make one SGD update
timer.tic()
self.solver.step(1)
timer.toc()
if self.solver.iter % (10 * self.solver_param.display) == 0:
print 'speed: {:.3f}s / iter'.format(timer.average_time)
if self.solver.iter % cfg.TRAIN.SNAPSHOT_ITERS == 0:
last_snapshot_iter = self.solver.iter
self.snapshot()
if last_snapshot_iter != self.solver.iter:
self.snapshot()到此为止,网络就可以开始训练了。
训练数据处理
不过,关于Fast-RCNN的重头戏我们其实还没开始——那就是如何准备训练数据。
在上面介绍训练的流程中,与此相关的函数是:imdb= get_imdb(args.imdb_name)
这个函数是从从lib/datasets/文件夹中的factory.py中import进来的,我们来看一下这个函数:
def get_imdb(name):
"""Get an imdb (image database) by name."""
if not __sets.has_key(name):
raise KeyError('Unknown dataset: {}'.format(name))
return __sets[name]()这个函数很简单,其实就是根据字典的key来取得训练数据。
那么这个字典是怎么形成的呢?看下面:
inria_devkit_path = '/home/jeremy/jWork/frcn/fast-rcnn/data/INRIA/'
for split in ['train', 'test']:
name = '{}_{}'.format('inria', split)
__sets[name] = (lambda split=split: datasets.inria(split, inria_devkit_path))它本质上是通过lib/datasets/文件夹下面的inria.py引入的。
所以,现在我们就得开始进入inria.py(这个函数需要我们自己编写,可以参考pascal_voc.py编写)。
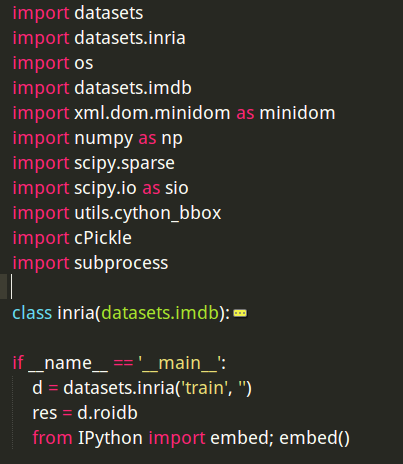
首先,我们来看看类inria的构造函数:
def __init__(self, image_set, devkit_path):
datasets.imdb.__init__(self, image_set)
self._image_set = image_set
self._devkit_path = devkit_path
self._data_path = os.path.join(self._devkit_path, 'data')
self._classes = ('__background__', # always index 0
'1001')
self._class_to_ind = dict(zip(self.classes, xrange(self.num_classes)))
self._image_ext = ['.jpg', '.png']
self._image_index = self._load_image_set_index()
# Default to roidb handler
self._roidb_handler = self.selective_search_roidb
# Specific config options
self.config = {'cleanup' : True,
'use_salt' : True,
'top_k' : 2000}
assert os.path.exists(self._devkit_path), \
'Devkit path does not exist: {}'.format(self._devkit_path)
assert os.path.exists(self._data_path), \
'Path does not exist: {}'.format(self._data_path)这里面最要注意的是要根据自己训练的类别同步修改self._classes,我这里面只有两类。
类 inria 构造完成后,会调用函数 roidb,这个函数是从类 imdb 中继承过来的,这个函数会调用 _roidb_handler 来处理,其中 _roidb_handler=self.selective_search_roidb,下面我们来看看这个函数:
def selective_search_roidb(self):
"""
Return the database of selective search regions of interest.
Ground-truth ROIs are also included.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path,
self.name + '_selective_search_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
roidb = cPickle.load(fid)
print '{} ss roidb loaded from {}'.format(self.name, cache_file)
return roidb
if self._image_set != 'test':
gt_roidb = self.gt_roidb()
ss_roidb = self._load_selective_search_roidb(gt_roidb)
roidb = datasets.imdb.merge_roidbs(gt_roidb, ss_roidb)
else:
roidb = self._load_selective_search_roidb(None)
print len(roidb)
with open(cache_file, 'wb') as fid:
cPickle.dump(roidb, fid, cPickle.HIGHEST_PROTOCOL)
print 'wrote ss roidb to {}'.format(cache_file)
return roidb这个函数在训练阶段会首先调用get_roidb() 函数:
def gt_roidb(self):
"""
Return the database of ground-truth regions of interest.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
roidb = cPickle.load(fid)
print '{} gt roidb loaded from {}'.format(self.name, cache_file)
return roidb
gt_roidb = [self._load_inria_annotation(index)
for index in self.image_index]
with open(cache_file, 'wb') as fid:
cPickle.dump(gt_roidb, fid, cPickle.HIGHEST_PROTOCOL)
print 'wrote gt roidb to {}'.format(cache_file)
return gt_roidb如果存在cache_file,那么get_roidb()就会直接从cache_file中读取信息;如果不存在cache_file,那么会调用_load_inria_annotation()来取得标注信息。_load_inria_annotation函数如下所示:
def _load_inria_annotation(self, index):
"""
Load image and bounding boxes info from txt files of INRIA Person.
"""
filename = os.path.join(self._data_path, 'Annotations', index + '.xml')
print 'Loading: {}'.format(filename)
def get_data_from_tag(node, tag):
return node.getElementsByTagName(tag)[0].childNodes[0].data
with open(filename) as f:
data = minidom.parseString(f.read())
objs = data.getElementsByTagName('object')
num_objs = len(objs)
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
# Load object bounding boxes into a data frame.
for ix, obj in enumerate(objs):
# Make pixel indexes 0-based
x1 = float(get_data_from_tag(obj, 'xmin')) - 1
y1 = float(get_data_from_tag(obj, 'ymin')) - 1
x2 = float(get_data_from_tag(obj, 'xmax')) - 1
y2 = float(get_data_from_tag(obj, 'ymax')) - 1
# ---------------------------------------------
# add these lines to avoid the accertion error
if x1 < 0:
x1 = 0
if y1 < 0:
y1 = 0
# ----------------------------------------------
cls = self._class_to_ind[
str(get_data_from_tag(obj, "name")).lower().strip()]
boxes[ix, :] = [x1, y1, x2, y2]
gt_classes[ix] = cls
overlaps[ix, cls] = 1.0
overlaps = scipy.sparse.csr_matrix(overlaps)
return {'boxes' : boxes,
'gt_classes': gt_classes,
'gt_overlaps' : overlaps,
'flipped' : False}当处理完标注的数据后,接下来就要载入SS阶段获得的数据,通过如下函数完成:
def _load_selective_search_roidb(self, gt_roidb):
filename = os.path.abspath(os.path.join(self._devkit_path,
self.name + '.mat'))
assert os.path.exists(filename), \
'Selective search data not found at: {}'.format(filename)
raw_data = sio.loadmat(filename)['boxes'].ravel()
box_list = []
for i in xrange(raw_data.shape[0]):
#这个地方需要注意,如果在SS中你已经变换了box的值,那么就不需要再改变box值的位置了
#box_list.append(raw_data[i][:, (1, 0, 3, 2)] - 1)
box_list.append(raw_data[i][:, (1, 0, 3, 2)])
return self.create_roidb_from_box_list(box_list, gt_roidb)有一点需要注意的是,ss中获得的box的值,和fast-rcnn中认为的box值有点差别,那就是你需要交换box的x和y坐标。
未完待续……
本文地址:http://blog.csdn.net/linj_m/article/details/48930179
更多资源请关注 博客:LinJM-机器视觉 微博:林建民-机器视觉