关于R-CNN请见enginelong的博客
文章目录
**FAST-RCNN无疑是在基于R-CNN的缺点进行改进得到的模型。摘要作者提到,FAST-RCNN在R-CNN工作的基础上使用深度神经网络更高效的分类建议区域,并且在用了几项重要的革新技术提高了模型的速度和准确率。FAST-RCNN使用VGG16在训练阶段比R-CNN快9倍,测试阶段更是快了213倍,基于PASCAL VOC2012 数据集实现了更高的mAP。然后与SPPnet进行了比较,结论是FAST-RCNN使用VGG16训练阶段比SPPnet快3倍,测试阶段快9倍并且正确率更高。**看到这样的效果,不得不佩服rbg大神,而且FAST-RCNN还是在5年前就已经提出来的。今天就来学习一下rbg大神的经典创作…
SPPnet与R-CNN
R-CNN缺点
- 训练分成多个阶段
- 预训练一个大型分类网络;
- 基于小数据集微调网络;
- 使用微调之后的网络训练SVMs;
- 训练回归器精调检测框位置
- 时间和空间成本都很高
为了SVMs和检测框精调回归器的训练,需要提取每一个候选区的特征向量然后存入磁盘。以VGG16主干网搭配VOC07训练数据集的5000张图片,进行这个训练过程在使用GPU环境下需要2.5days,需要数百GB的存储空间。 - 目标检测速度较慢
R-CNN测试阶段,需要从每一张图片的每一个候选区分别提取特征向量,经过测试,基于VGG16作为主干网的目标检测速度为47s/image(GPU)。
R-CNN主要慢在需要为每一张图片的每一个候选区进行前向计算,每一个候选区的计算过程都是独立的,没有共享计算过程即使相当一部分计算过程对于每一个候选区都是相同的。
R-CNN训练过程如下:

SPPnet改进
基于R-CNN没有共享权重的缺点,SPPnet进行了改进,并取到了较好的效果。
- SPPnet对整张图片进行整体的一次卷积操作,然后从整张图片的特征图上提取每一个候选区的特征向量,而不是像R-CNN那样,为了得到每一个候选区的特征向量分别进行单独的卷积操作。由于更快的候选区特征提取,训练时间也减少了3倍,测试时间相对于R-CNN加速了10到100倍。
SPPnet缺点
- 如R-CNN一样,SPPnet也需要多阶段训练;
- 微调网络时,微调策略不可以更新空间金字塔池化之前的卷积层的权重,固定的卷积层也直接限制了SPPnet准确率的提升
SPPnet训练过程如下:

OK,看过R-CNN和SPPnet的分析,将目光转到FAST-RCNN。论文提到,基于R-CNN与SPPnet的缺点从而提出了FAST-RCNN模型,因此FAST-RCNN具有以下优点: - 更高的检测质量(mAP);
- 训练是一阶段模式,因为采用了多任务损失函数;
- 训练阶段可以更新之前全部的网络层;
- 不需要磁盘存储特征向量
【注意】
- 实际上,FAST-RCNN本质上并非单阶段模型,至少候选区的产生仍然依靠选择性搜索算法
FAST-RCNN
FAST-RCNN模型架构
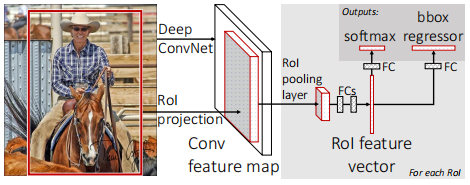
- FAST-RCNN将整张图片和一系列的候选区(选择性搜索提前产生)作为模型输入,经过一系列的卷积层、最大池化层得到整张图片的特征图。然后,将每个候选区映射到对应的特征图,经过RoI最大池化层得到每一个ROI(候选区)的特征向量。最后喂入全连接层产生两路输出分别用于分类和定位。
- 每一个特征图经过一个ROI池化层进而归一化到统一大小(固定大小以适应全连接层固定的输入维度);
- 将每一个特征向量喂入按照固定序列连接的的全连接层;
- 最后通过两个并列的全连接层分别输出分类信息(背景算作单独的一类)和具有检测目标的候选区(只含有背景的候选区被忽略)的位置偏移量(用来精调候选框位置)。
【注意】
- 经过选择性搜索产生候选区的过程,就已经粗略得到了每一个候选区的位置,只不过此时的定位信息是十分粗糙的。

一定要明白候选区映射和RoI 最大池化并不是一回。将候选区根据坐标直接映射到卷积特征图上可以直接快速提取特征图;RoI最大池化用于统一不同大小的特征图以适应全连接层的输入。
一系列卷积层后的输出:

根据ROI的坐标信息直接从卷积特征图上提取每一个ROI的特征图,只不过由于映射会有坐标的近似化处理,因此过程中会丢失和加入一些信息,不过一般是可以忍受的:

ROI 池化层
ROI池化层使用最大池化操作,将候选区中的特征图映射为固定大小的空间尺度HxW(H&W为超参数)。这里使用了空间金字塔池化技术,用于将不同大小的特征图统一输出为规定大小,然而这里FAST-RCNN仅仅是采用了SPPnet种空间池化金字塔的最后一层,实际上就是通过设计自适应尺寸的池化核使得可以接收不同大小的输入特征图并产生相同大小的输出。关于空间金字塔池化技术详见空间金字塔池化

FAST-RCNN训练过程
预训练模型初始化FAST-RCNN主干网
论文使用了基于ImageNet预训练完成的网络对主干网进行初始化,初始化步骤如下:
- 将预训练网络中最后一个最大池化层替代为ROI池化层;
- 将预训练网络中最后的全连接层替代为两个子层,分别为:
- 用于产生分类概率的softmax层;
- 用于产生检测框微调偏移量的回归层;
- 修改预训练网络的输入层使得可以接受图片列表、候选区列表两种输入数据
微调网络
简单来说就是根据特定的数据集训练FAST-RCNN主干网,法向传播更新所有的网络层的权重,最终就得到了目标检测网络。
然而,这里更重要的是要搞明白为什么FAST-RCNN可以更新所有网络层,但是SPPnet却不可以更新空间金字塔池化层之前的网络层???

- 论文解释道:
- 这种现象的主要原因是通过SPPnet反向传播的过程在每个ROI来自于不同图片时是非常低效的。低效的根源在于每一个ROI通常具有很大的感受野,并且感受野经常跨越整张图片。然而前向传播过程必须处理整个感受野,因此反向传播效率非常低。
- 同时FAST-RCNN改善了这种情况,论文基于随机梯度下降过程进行了改进。用于SGD的batches来自于分层采样,以N代表参与训练图片的数目,R代表参与训练的ROI的数目,论文在训练时从N张图片采集R/N个ROI。实验证明此种采样策略比从R-CNN/SPPnet使用的采样策略快大约64倍。然而FAST-RCNN的采样策略由于ROI之间较大的相关性可能导致网络训练收敛较慢的问题,不过很幸运这种现象在实验中并没出现,并且论文中说明了实验中使用N=2、R=128取得了很好的效果,即每一张图片采样64个ROI,同时训练2张图片。
FAST-RCNN几个细节
多任务损失函数
FAST-RCNN进行采用单个神经网络同时对目标进行分类与定位,核心在于损失函数的设计。经过ROI层输出一系列相同大小的特征图,将维度转换为MxN输入全连阶层,最后分别经过两个子层输出。子层之一为softmax层输出每一个ROI(候选区)类别概率 ( p = ( p 0 , . . . , p u (p=(p_0,...,p_u (p=(p0,...,pu),包括K个前景类和一个背景类),子层之二输出目标定位信息的偏移量( t u = ( t x u , t y u , t w u , t h u ) t^u = (t^u_x,t^u_y,t^u_w,t^u_h) tu=(txu,tyu,twu,thu),背景类被忽略)。由此FAST-RCNN设计了多任务损失函数,共同对分类和边界偏移回归进行优化:
L ( p , u , t u . v ) = L c ∗ ( p , u ) + λ [ u > = 1 ] L r ( t u , v ) L(p,u,t^u.v) = L_c*(p,u) + \lambda[u>=1]L_r(t^u,v) L(p,u,tu.v)=Lc∗(p,u)+λ[u>=1]Lr(tu,v)
「注意」
- Lc表示分类损失部分,Lr表示偏移回归损失部分,λ用于调整偏移回归的权重,u>=1表示仅对包含有前景目标的类别进行定位信息微调,因此自然将背景类排除在外。
L c ( p , u ) = − l o g p u L_c(p,u) = -logp_u Lc(p,u)=−logpu
L r ( t u , v ) = ∑ i ∈ ( x , y , w , h ) s m o o t h ( t i u − v i ) L_r(t^u,v) = \sum_{i\in{(x,y,w,h)}}smooth(t^u_i - v_i) Lr(tu,v)=i∈(x,y,w,h)∑smooth(tiu−vi)
s m o o t h ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e smooth(x) = \begin{cases} 0.5x^2 & if |x|<1 \\|x|-0.5 & otherwise \end{cases} smooth(x)={
0.5x2∣x∣−0.5if∣x∣<1otherwise
- v = ( v x , v y , v w , v h ) v = (v_x,v_y,v_w,v_h) v=(vx,vy,vw,vh)是第u(1<=u<=K)个类别偏移量目标值,论文对 v i v_i vi进行了标准化,使得其均值、方差均为0。smooth(x)使用了 L 1 L_1 L1损失, L 1 L_1 L1损失相对于 L 2 L_2 L2损失处理异常值更加鲁棒,此外对于边界无限定的目标检测任务,使用 L 2 L_2 L2损失需要慎重地调节学习率,以避免梯度爆炸的现象。
- 注意损失函数中的 λ \lambda λ,用来平衡分类与偏移回归两项任务的权重,论文中的策略是将 λ \lambda λ置为1。
Mini-batch采样
如前文所述,微调网络时,为了更高效地利用反向传播算法更新全部的网络层权重,每个SGD mini-batch以每次采样两张图片、每张图片采样64个ROI的策略获取。对于训练集中ROI的组成,25%的ROI来自于与图片目标标记区域的的IOU在0.5以上的ROI,以此组成批训练集中带有标记的前景目标样本。其余75%的样本来自于与图片目标标记区域的的IOU ∈ [ 0.1 , 0.5 ) \in[0.1,0.5) ∈[0.1,0.5)以上的ROI以此组成用于训练的背景类即u=0的类。与图片目标标记区域的的IOU低于0.1的样本用于启发式负例采样。在训练期间,图片以50%的概率进行水平翻转,并不采用其他数据增强的方式。
RoI池化层的反向传播
想要搞明白如何通过RoI pooling layers反向传播,我们可以假设在每一个mini-bacth中仅含有N=1张图片,之所以可以这样设,是因为我们可以很方便的将N=1扩展到N=n,因为前向传播过程中每张图片的处理是独立的。现在,以 x i ∈ R x_i\in R xi∈R表示输入RoI pooling layer的第i个激活输入,以 y r j y_{rj} yrj表示第r个ROI(候选区)到本层的第j个输出。
y r j = x i ∗ ( r , j ) y_{rj} = x_{i*(r,j)} yrj=xi∗(r,j)
i ∗ ( r , j ) = a r g m a x i ′ ∈ R ( r , j ) x i ′ i*(r,j) = argmax_{i'\in R{(r,j)}}x_{i'} i∗(r,j)=argmaxi′∈R(r,j)xi′
其中,R(r,j)是 y r j y_{rj} yrj所在的子窗口对应的一组输入, x i x_i xi也许会被分配到几个不同的输出
这样以来,RoI pooling layer的后向函数就可以计算损失函数关于输入变量 x i x_i xi的偏导数:
∂ L ∂ x i = ∑ r ∑ j [ i = i ∗ ( r , j ) ] ∂ L ∂ y r j \frac {\partial L}{\partial x_i} = \sum_r \sum_j {[i=i*(r,j)]} \frac {\partial L}{\partial y_{rj}} ∂xi∂L=r∑j∑[i=i∗(r,j)]∂yrj∂L
SGD超参数
根据论文所述:
- 用于分类和检测框回归的全连接层使用均值为0、标准差分别为0.01和0.001的高斯分布进行初始化。偏置统一被初始化为0;
- 每一层的权重学习率为1,偏置学习率为2,所有层的全局学习率为0.001;
当
作者使用VOC07/VOC12基于随机梯度下降法SGD进行了30k个mini-batch迭代,然后降低学习率至0.0001再迭代10k次,动量0.9、参数(权重、偏置)衰减率为0.0005。当使用更大数据集时,可以进行更多的迭代训练。
######尺度不变性
论文中提到了两种尺度不变性的目标检测方式:
- 暴力学习((brute force learning);
- 图像金字塔
- brute force learning中,图像以预先定义好的像素大小进行处理,网络必须直接从训练数据中学习尺度不变的目标检测;
- 多尺度检测通过使用图像金字塔技术近似为网络提供了尺度不变性,测试阶段使用图像金字塔对每一个对象建议近似尺度归一化。多尺度训练时,我们每一次对图像进行采样时都会随机抽取一个金字塔比例的样本,以此作为数据增强的一种形式。
FAST-RCNN检测
微调完成后,网络以图像列表与候选区列表作为输入,每一张图像提取大约2000个候选区,假设ROI提前计算完成,每次执行检测就是一次前向计算的过程。通过计算,网络输出一组关于类别的后验概率和一系列的检测框偏移量。然后,我们就可以为每一个目标检测框赋予一个分类置信度:
P r ( c l a s s = u ∣ r ) = p u Pr(class=u | r) = p_u Pr(class=u∣r)=pu
最后,通过为每个类别执行非极大值抑制(non-maximum suppression)就可以相当准确地对目标进行检测。
使用SVD加速全连接层
对于整张图像进行分类时,在全连接层上花费的时间比卷积层要少。然而对图像进行目标检测时,由于需要处理大量的ROIs,则前向计算的时间近一半花费在全连接层计算。通过截断SVD压缩可以很简单地加速全连接层地计算,理论基础是:
W ≈ U Σ t V T W \approx U \Sigma_tV^T W≈UΣtVT
其中:
- U 是一个 u ∗ t u \ast t u∗t矩阵,包含W的t个左奇异向量;
- Σ t \Sigma_t Σt是一个t ∗ t \ast t ∗t的对角阵,包含W的t个右奇异向量
因此,对于通过矩阵W( u ∗ v u \ast v u∗v)参数化的全连接层,使用截断SVD可以将参数从uv转化为t(u+v),当t<<min(u,v)时,截断SVD压缩效果更大。据此,我们就可以将以W参数化的全连接层替代为两个没有线性关系的全连接层。对于这两个全连接层,其中一个使用权重矩阵 Σ t V t \Sigma_tV^t ΣtVt,没有偏置;另外一个使用U作为权重矩阵,使用原W参数化的全连接层的偏置作为本层的偏置。
FAST-RCNN主要结果
- 在VOC07、2010、2012数据集上取得了最优的结果(mAP);
- 训练于测试的速度超越了R-CNN、SPPnet;
- 基于VGG16微调网络提高了mAP

FAST-RCNN后探讨简述
论文后面部分探究了一些其他的问题:
- 我们需要更多的数据吗 ?
实验证明,在增加训练数据的基础上,FAST-RCNN可以得到少许提高。
2)SVMs会优于softmax吗?
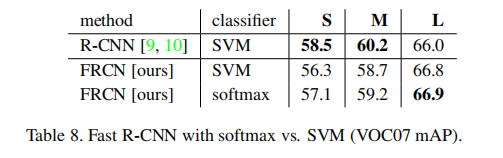
经实验数据可以看出,softmax在大、中、小三种网络上均略胜于SVMs。 - 候选区越多越好吗?

实际上,候选区增加对模型的影响结果是很难预测的,不过一般来说,稀疏的候选区建议可以提高检测器的质量。然而,正如rbg大神所述,也许存在一种未发现的技术允许可以像检测稀疏的区域建议一样也可以很好地检测稠密的区域建议。