##问题
目前hbase 总是出现压缩队列和刷新队列过大的告警,导致数据的读写变慢。
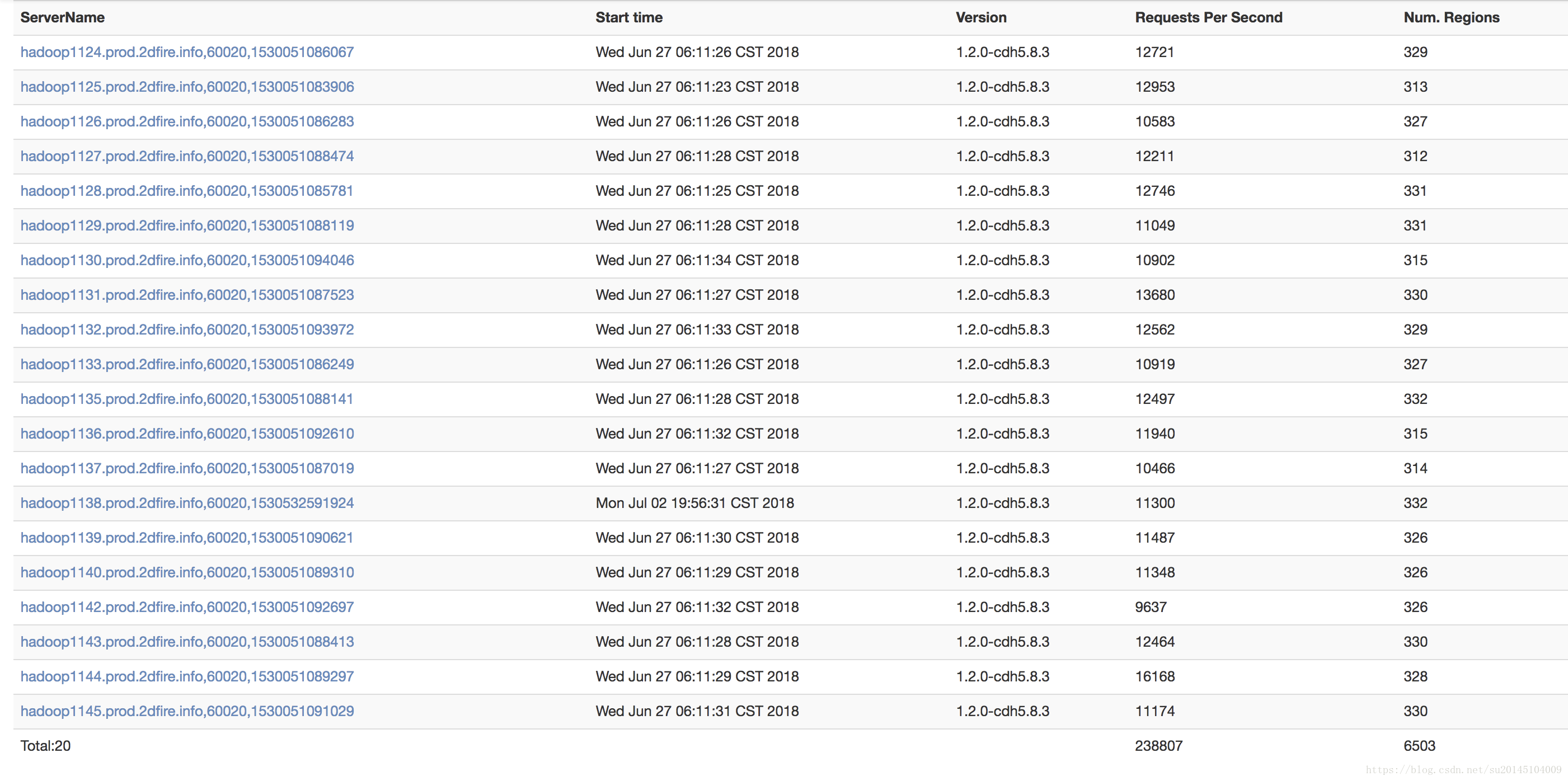
首先说明一下目前集群的状况
regionServer数量:20
region 数量:6503
regionServer配置:-Xms10g -Xmx10g -Xmn3g
##原因
找到一些可能的原因。
- region 数量过多
- regionServer 堆大小为10G,有些小
- regionServer 太少
###根据hbase官网配置(http://hbase.apache.org/book.html#ops.capacity.regions.count)
regionServer数量的计算公式为:
在我们公司中
Xmx=10*1024=10240M
hbase.regionserver.global.memstore.upperLimit=0.4
hbase.hregion.memstore.flush.size=128M
column families = 1
经过计算得到单个regionServer最适合管理的region数量为:regionNum = 32个 。可以适当超出2~3倍。
而在实际中,我们的单个regionServer已经达到了300多个,是官方推荐的近10倍。
##解决方案
###调整堆大小(http://hbase.apache.org/book.html#ops.capacity.nodes.gc)
根据官方推荐(20-24),可以适当调整regionserver的堆大小,受限与gc与zk的关系,我们可以设置为20G.
###调整memstore百分比
根据官方推荐,在写工作量较大的regionServer,可以适当调大memstore的百分比,降低block cache的百分比。可以支持更多的region。
hbase.regionserver.global.memstore.upperLimit 调整为0.6
hfile.block.cache.size:调整为0 (关闭读缓存,在cloudera manager上看,hbase的读除了(H+1任务)几乎为0.所以我们几乎不需要缓存,不使用缓存对于葱白的链路监控,影响不大)
###增加阻塞倍率
属性hbase.hregion.memstore.block.multiplier的默认值为2,它是用来阻塞来自客户端更新数据请求的安全阈值,当memstore达到multiplier*flush的大小限制,会阻止进一步的更新。
当有足够的存储空间,我们增加这个值来平滑地处理写入突发流量。
对于我们公司,这个值还是默认。原因是:region数量太多,堆空间不足。
###减少最大日志文件限制
设置hbase.regionserver.maxlogs属性来控制刷写频率,默认32,
对于写压力较大的应用,这个值过大。降低这个值会强迫服务器更频繁地将数据刷写到磁盘上,这样已经刷写到磁盘上的数据所对应的日志就删除了。
尽管我们的应用没有使用wal,但是觉得还是应该设置一下。
增加hbase.hstore.blockingStoreFiles的个数
默认参数为10
当storefile的个数达到10个时,就会阻塞hbase的写入,强烈建议调大。比如3000.
##究极方案
#增加机器
由于增加机器,是无能的表现。。所以尽量先优化 ,在不能优化的情况下,再增加机器。
##结论
综上所述,我们需要增加的配置有
参数
-Xmx 20g -Xms20G
hbase.regionserver.global.memstore.upperLimit=0.6
hbase.regionserver.global.memstore.size=0.6
hfile.block.cache.size=0
hbase.regionserver.maxlogs=16
此时支持的region数量为:2010240.6/128=96 96*3=288 基本达到要求