函数式API简介
使用函数式API,可以直接对张量进行操作,也可以把层当做函数来使用,接收张量并返回张量。
下面举一个简单的示例,并展示一个简单的Sequential模型以及对应的函数式API实现。
from keras.models import Sequential, Model
from keras.layers import Dense
from keras import Input
seq_model = Sequential() # Sequential模型
seq_model.add(Dense(32, activation = 'relu', input_shape = (64, )))
seq_model.add(Dense(32, activation = 'relu'))
seq_model.add(Dense(10, activation = 'softmax'))
input_tensor = Input(shape = (64,)) #一个张量
x = Dense(32, activation = 'relu')(input_tensor) #一个层是一个函数
x = Dense(32, activation = 'relu')(x)
output_tensor = Dense(10, activation = 'softmax')(x)
model = Model(input_tensor, output_tensor)
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 64) 0
_________________________________________________________________
dense_4 (Dense) (None, 32) 2080
_________________________________________________________________
dense_5 (Dense) (None, 32) 1056
_________________________________________________________________
dense_6 (Dense) (None, 10) 330
=================================================================
Total params: 3,466
Trainable params: 3,466
Non-trainable params: 0
model.compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy')
import numpy as np #生成用于训练的虚构Numpy数据
x_train = np.random.random((1000, 64))
y_train = np.random.random((1000, 10))
model.fit(x_train, y_train, epochs = 10, batch_size = 128)
score = model.evaluate(x_train, y_train) #评估模型
多输入模型
这里展示一个简单的多输入示例:问答模型。
典型的问答模型有两个输入:一个自然语言描述的问题和一个文本片段(比如新闻文章),后者提供用于回答的问题信息。然后模型要生成一个回答,在最简单的情况下,这个回答值包含一个词,可以通过对某个预定的词表做softmax得到。
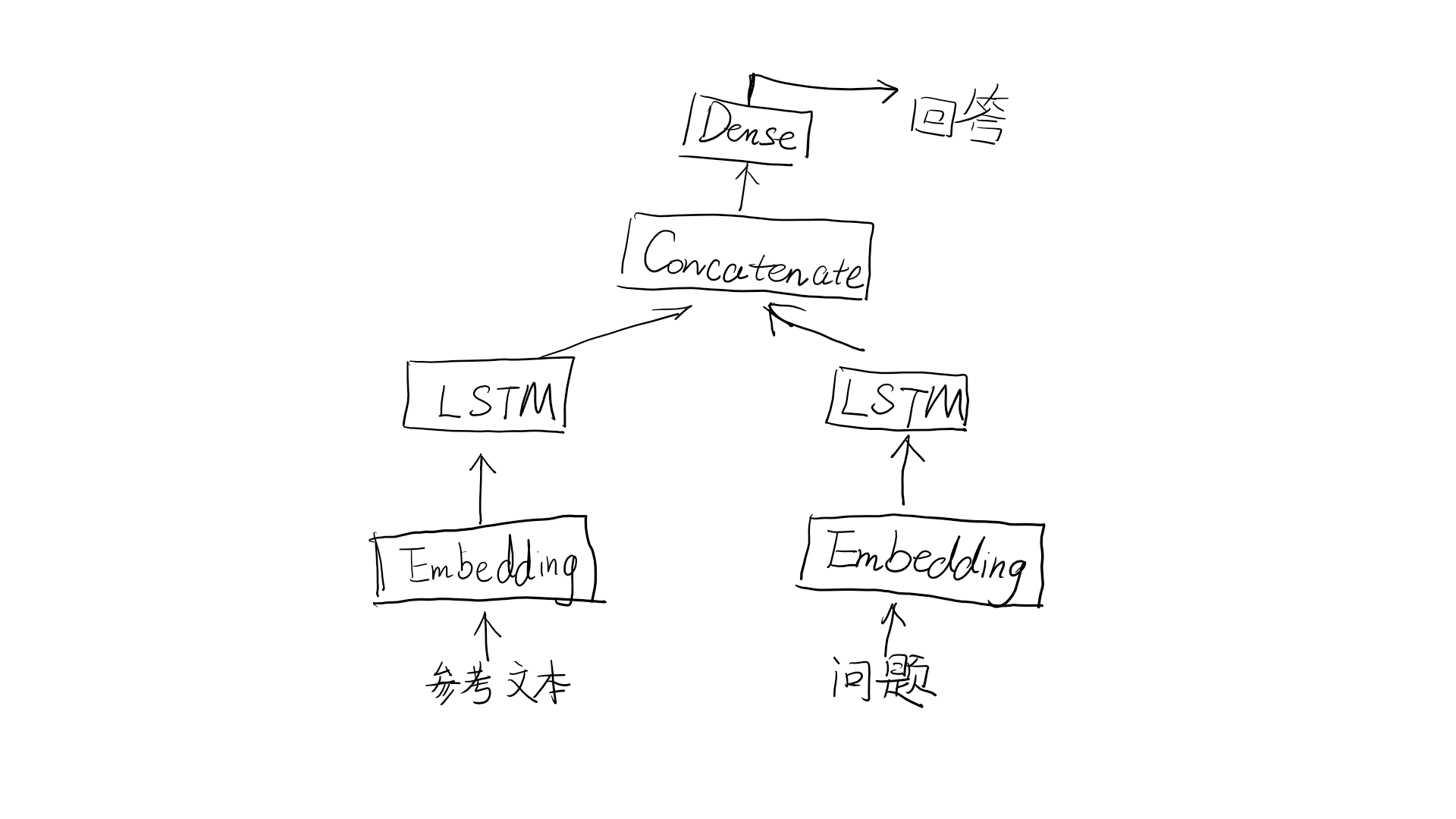
from keras.models import Model
form keras import layers
from keras import Input
text_vocabbulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
text_input = Input(shape = (None,), dtype = 'int32', name = 'text') #文本输入是一个长度可变的序列,可以命别的名字
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input) #将输入嵌入为长度64的向量
encoded_text = layers.LSTM(32)(embedded_text) #利用LSTM将向量编码为单个向量
question_input = Input(shape = (None,), dtype = 'int32', name = 'question') #对问题进行相同的处理(使用不同的层实例)
embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
concatenated = layers.concatenate([encoded_text, encoded_question], axis = -1) #将编码后的问题和文本连在一起,axis = 0,横着合并。1或-1按列竖着合并
answer = layers.Dense(answer_vocabulary_size, activation = 'softmax')(concatenated) #在上面添加一个softmax分类器
model = Model([text_input, question_input], answer) #在模型实例化的时候,指定两个输入和输出
model.compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy', metrics = ['acc'])
接下来如何训练这个双输入模型呢?有两个可用的API:我们可以向模型输入一个由Numpy数组组成的列表,或者也可以输入一个将输入名称映射为Numpy数组的字典。当然,只有输入具有名称的时候才可以使用后一种方法。我们这里两种都展示一下。
另外,我们这里输入进行训练的answers标签是以one-hot编码形式输入的。这一点需要留意一下。
import numpy as np
import keras
num_samples = 1000
max_length = 100
text = np.random.randint(1, text_vocabulary_size, size = (num_samples, max_length))
question = np.random.randint(answer_vocabulary_size, size = (num_samples, max_length))
answers = np.random.randint(answer_vocabulary_size, size = (num_samples))
# to_categorical方法用来将标签转换为onehot编码
answers = keras.utils.to_categorical(answers, answer_vocabulary_size)
model.fit([text, question], answers, epochs = 10, batch_size = 128) #使用输入组成的列表来拟合
#fit也可以写成这样的类型(这两种都行)
# 使用输入组成的字典来拟合(只有对输入进行命名之后才能用这种方法)
model.fit({'text' : text, 'question' : question}, answers, epochs = 10, batch_size = 128)
多输出模型
使用相同的办法,我们还可以用函数式API来构建多输出模型。一个简单的例子就是网络试图同时预测数据额不同性质,比如一个网络,输入某个匿名人士的一系列社交媒体发帖,然后尝试预测那个人的属性,比如年龄、性别和收入水平。
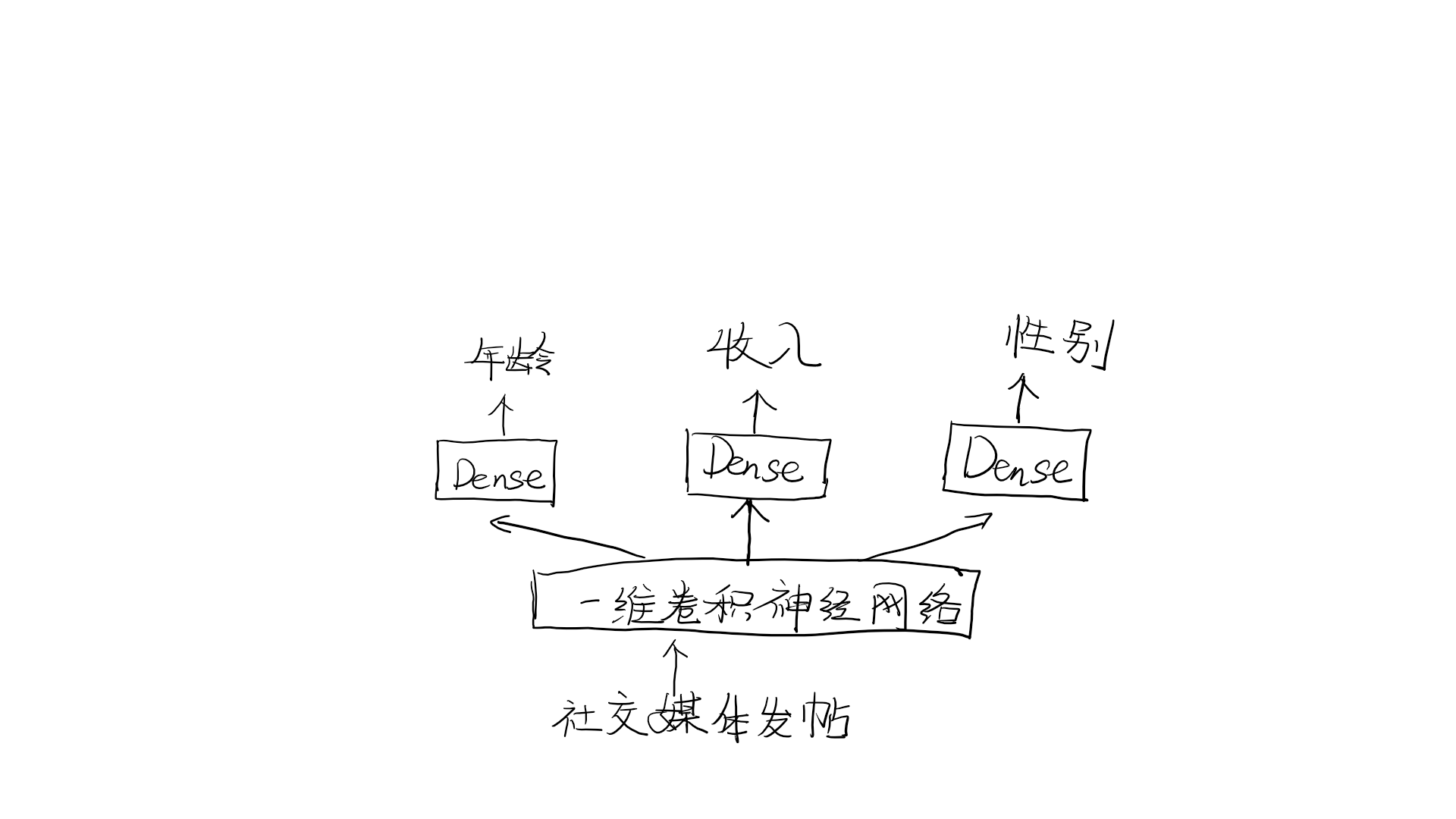
重要的是,训练这种模型需要对网络的各个头指定不同的损失函数,例如,年龄预测是标量回归任务,而性别预测是二分类任务,二者需要不同的训练过程。但是,梯度下降要求将一个标量最小化,所以为了能够训练模型,我们必须将这些损失合并为单个标量。合并不同损失函数最简单的办法是对所有损失求和。在Keras中,你可以在编译时使用损失组成的列表或字典来为不同的输出指定不同的损失,然后将得到的损失值相加得到一个全局损失,并在训练过程中将这个损失最小化。
from keras import layers
from keras import Input
from keras.models import Model
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape = (None,), dtype = 'int32', name = 'posts')
embedded_posts = layers.Embedding(vocabulary_size, 256)(posts_input)
x = layers.Conv1D(128, 5, activation = 'relu')(embedded_posts) # 128是卷积核的数目,即输出的维度
x = layers.MaxPooling1D(5)(x) # 5是池化窗口大小
x = layers.Conv1D(256, 5, activation = 'relu')(x)
x = layers.Conv1D(256, 5, activation = 'relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation = 'relu')(x)
x = layers.Conv1D(256, 5, activation = 'relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation = 'relu')(x)
age_prediction = layers.Dense(1, name = 'age')(x) #注意,输出层都应该写上名称,这样看代码也容易识别
income_prediction = layers.Dense(num_income_groups, activation = 'softmax', name = 'income')(x)
gender_prediction = layers.Dense(1, activation = 'sigmoid', name = 'gender')(x)
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
model.summary()
model.compile(optimizer = 'rmsprop',
loss = ['mse', 'categorical_crossentropy', 'binary_crossentropy'],
loss_weigths = [0.25, 1., 10.])
# 两种complile方法等效,但是只有输出层具有名称的时候才能使用第二种方法
model.compile(optimizer = 'rmsprop',
loss = {'age':'mse',
'income':'categorical_crossentropy',
'gender':'binary_crossentropy'},
loss_weigths = {'age':0.25,
'income':1.,
'gender':10.})
model.fit(posts, [age_targets, income_targets, gender_targets],
epochs = 10, batch_size = 64)
# 两种fit方法等效,但是只有输出层具有名称的时候才能使用第二种方法
model.fit(posts, {'age':age_targets,
'income':income_targets,
'gender':gender_targets},
epochs = 10, batch_size = 64)
注意,严重不平衡的损失贡献会导致模型表示针对单个损失最大的任务优先进行优化,而不考虑其他任务的优化。为了解决这个问题,我们可以为每个损失值对最终损失的贡献分配不同的大小重要性。如果不同的损失具有不同的取值范围,那个这一方法尤其有用。比如,用于年龄回归任务的均方误差(MSE)损失通常在3-5左右,而用于性别分类任务的交叉熵损失可能低至0.1。在这种情况下,为了平衡不同的损失贡献,我们可以让交叉熵损失的权重取10,而MSE损失的权重取0.5。
Inception模块
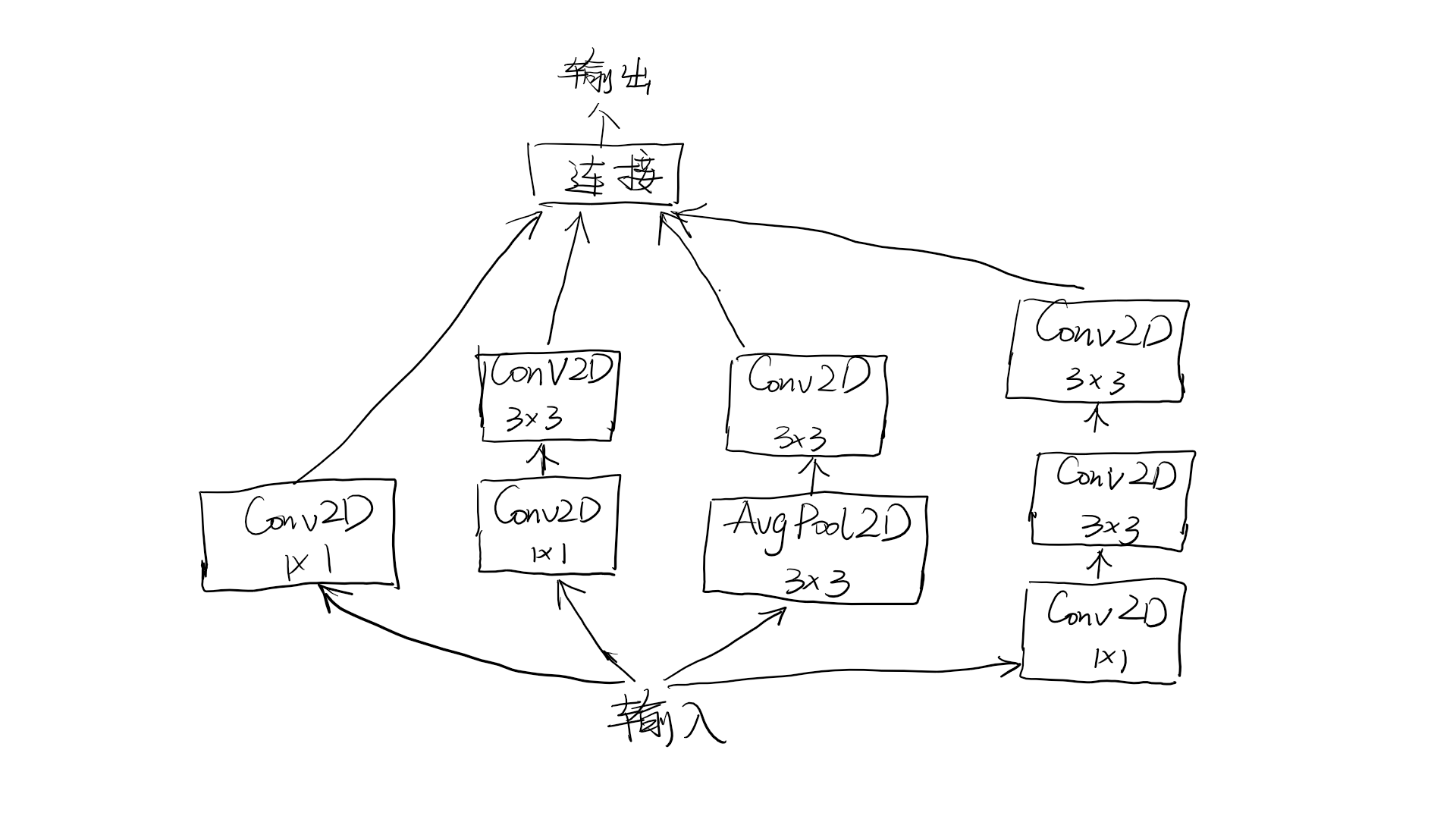
from keras import layers
# 每个分支都有相同的步幅2,这对于保持所有分支输出都具有相同的尺寸是很重要的,这样才可以把他们连接在一起
branch_a = layers.Conv2D(128, 1, activation = 'relu', strides = 2)(x)
branch_b = layers.Conv2D(128, 1, activation = 'relu')(x)
branch_b = layers.Conv2D(128, 3, activation = 'relu', strides = 2)(branch_b)
branch_c = layers.AveragePooling2D(3, strides = 2)(x)
branch_c = layers.Conv2D(128, 3, activation = 'relu')(branch_c)
branch_d = layers.Conv2D(128, 1, activation = 'relu')(x)
branch_d = layers.Conv2D(128, 3, activation = 'relu')(branch_d)
branch_d = layers.Conv2D(128, 3, activation = 'relu', strides = 2)(branch_d)
# 将分支输出连接在一起,得到模块输出
output = layers.concatenate([branch_a, branch_b, branch_d], axis = -1)
残差连接
如果特征图的尺寸相同,在Keras中实现残差连接的方法如下。这里例子中我们假设有一个四维输入张量x
from keras import layers
x = ...
y = layers.Conv2D(128, 3, activation = 'relu', padding = 'same')(x)
y = layers.Conv2D(128, 3, activation = 'relu', padding = 'same')(y)
y = layers.Conv2D(128, 3, activation = 'relu', padding = 'same')(y)
y = layers.add([y, x]) #将原始x与输出特征相加
如果特征图尺寸不同,实现残差的方法如下。同样,我们也假设有一个四维输入张量x
from keras import layers
x = ...
y = layers.Conv2D(128, 3, activation = 'relu', padding = 'same')(x)
y = layers.Conv2D(128, 3, activation = 'relu', padding = 'same')(y)
y = layers.maxPooling2D(2, strides = 2)(y)
residual = layers.Conv2D(128, 1, strides = 2, padding = 'same')(x) #使用1*1卷积,将原始x张量线性下采样为与y具有相同的形状
y = layers.add([y, residual]) #将残差张量与输出特征相加