#multi_layer Perceptron by ffzhang
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time
import os
os.environ["CUDA_VISIBLE_DEVICES"]='2'
mnist = input_data.read_data_sets('data/mnist',one_hot=True)
mnist.train.images.shape
mnist.train.labels.shape
#define placeholder to save the training data
X = tf.placeholder(tf.float32,[None,784],name='X_placeholder')
Y = tf.placeholder(tf.float32,[None,10],name='Y_placeholder')
#define parameters
n_hidden_1 =256
n_hidden_2 =256
n_input =784
n_classes =10
weights ={
'h1': tf.Variable(tf.random_normal([n_input,n_hidden_1]),name='W1'),
'h2': tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2]),name='W2'),
'out': tf.Variable(tf.random_normal([n_hidden_2,n_classes]),name='W')
}
biases ={
'b1': tf.Variable(tf.random_normal([n_hidden_1]),name='b1'),
'b2': tf.Variable(tf.random_normal([n_hidden_2]),name='b2'),
'out': tf.Variable(tf.random_normal([n_classes]),name='bias')
}
#define graph for this network
def multilayer_perceptron(x,weights,biases):
layer_1 = tf.add(tf.matmul(x,weights['h1']),biases['b1'],name='fc_1')
layer_1 = tf.nn.relu(layer_1,name='relu_1')
layer_2 = tf.add(tf.matmul(layer_1,weights['h2']),biases['b2'],name='fc_2')
layer_2 = tf.nn.relu(layer_2,name='relu_2')
out_layer = tf.add(tf.matmul(layer_2,weights['out']),biases['out'],name='fc_3')
return out_layer
pred = multilayer_perceptron(X, weights, biases)
learning_rate = 0.001
loss_all = tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=pred,name='cross_entropy')
loss = tf.reduce_mean(loss_all,name='avg_loss')
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
init =tf.global_variables_initializer()
training_epochs=15
batch_size=128
display_step =1
with tf.Session() as sess:
sess.run(init)
writer =tf.summary.FileWriter('./graphs/MLP_dnn',sess.graph)
for epoch in range(training_epochs):
avg_loss =0
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_x, batch_y =mnist.train.next_batch(batch_size)
_, l =sess.run([optimizer,loss],feed_dict={X: batch_x, Y: batch_y})
avg_loss += l/total_batch
if epoch%display_step==0:
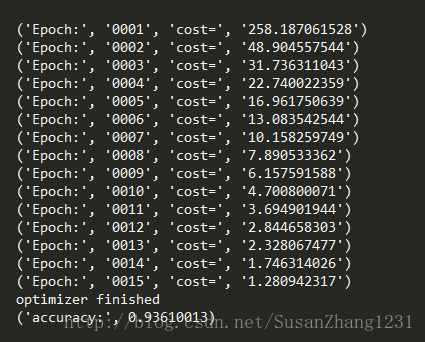
print ('Epoch:', '%04d'% (epoch+1),'cost=', "{:.9f}".format(avg_loss))
print ('optimizer finished')
correct_prediction = tf.equal(tf.argmax(pred,1),tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,'float'))
print ('accuracy:',accuracy.eval({X:mnist.test.images, Y:mnist.test.labels}))
writer.close()
多层感知机(multi-layer perceptron)实现手写体分类(TensorFlow)
猜你喜欢
转载自blog.csdn.net/SusanZhang1231/article/details/76848101
今日推荐
周排行