相较于前面的基础,这篇文章才是真正意义上的第一个tensorflow的Hello World。我们将使用tensorflow提供的方法来对数据中所体现的线性关系进行建模,通过输入数据对模型进行训练,然后使用训练生成的稳定模型对未知的自变量所对应的因变量进行确认。

回归分析
回归分析研究的是因变量和自变量之间的关系,在预测模型中被广泛地应用。自变量的个数/因变量的类型/回归线的形状都是需要考虑的,常见的回归分析方式如下:
- Linear Regression:线性回归
- Logistic Regression:逻辑回归
- Polynomial Regression:多项式回归
- Lasso Regression:套索回归
- ElasticNet Regression:ElasticNet回归
线性回归
线性,简单来说就是y = k*x + b,自变量和因变量之间的关系用一条直线来进行表述,k是数学意义上的斜率,而b则是调整的偏差。(为了与常用的各种资料保存一致,将k调整为w)
场景说明
求解问题:Y = K*X +B
选项 说明 Y 因变量:数据有训练数据和测试数据两类,为输入数据 X 自变量:数据有训练数据和测试数据两类,训练数据为输入数据,测试数据为待求解的输出数据 K 斜率:自变量和因变量之间的线性关系,为待求解的值,为输出数据 B 偏差:调整的偏差值,为待求解的值,为输出数据
求解过程
事前准备
假定带求解的线性问题为:Y = 2*X + 1
数据准备:
- 自变量:xdata,将0到1进行100等分所形成的等差数列
- 因变量:ydata,满足2*xdata + 1的线性关系
xdata = np.linspace(0,1,100)
ydata = 2 * xdata + 1
具体设定值:
>>> print(xdata)
[0. 0.01010101 0.02020202 0.03030303 0.04040404 0.05050505
0.06060606 0.07070707 0.08080808 0.09090909 0.1010101 0.11111111
0.12121212 0.13131313 0.14141414 0.15151515 0.16161616 0.17171717
0.18181818 0.19191919 0.2020202 0.21212121 0.22222222 0.23232323
0.24242424 0.25252525 0.26262626 0.27272727 0.28282828 0.29292929
0.3030303 0.31313131 0.32323232 0.33333333 0.34343434 0.35353535
0.36363636 0.37373737 0.38383838 0.39393939 0.4040404 0.41414141
0.42424242 0.43434343 0.44444444 0.45454545 0.46464646 0.47474747
0.48484848 0.49494949 0.50505051 0.51515152 0.52525253 0.53535354
0.54545455 0.55555556 0.56565657 0.57575758 0.58585859 0.5959596
0.60606061 0.61616162 0.62626263 0.63636364 0.64646465 0.65656566
0.66666667 0.67676768 0.68686869 0.6969697 0.70707071 0.71717172
0.72727273 0.73737374 0.74747475 0.75757576 0.76767677 0.77777778
0.78787879 0.7979798 0.80808081 0.81818182 0.82828283 0.83838384
0.84848485 0.85858586 0.86868687 0.87878788 0.88888889 0.8989899
0.90909091 0.91919192 0.92929293 0.93939394 0.94949495 0.95959596
0.96969697 0.97979798 0.98989899 1. ]
>>> print(ydata)
[1. 1.02020202 1.04040404 1.06060606 1.08080808 1.1010101
1.12121212 1.14141414 1.16161616 1.18181818 1.2020202 1.22222222
1.24242424 1.26262626 1.28282828 1.3030303 1.32323232 1.34343434
1.36363636 1.38383838 1.4040404 1.42424242 1.44444444 1.46464646
1.48484848 1.50505051 1.52525253 1.54545455 1.56565657 1.58585859
1.60606061 1.62626263 1.64646465 1.66666667 1.68686869 1.70707071
1.72727273 1.74747475 1.76767677 1.78787879 1.80808081 1.82828283
1.84848485 1.86868687 1.88888889 1.90909091 1.92929293 1.94949495
1.96969697 1.98989899 2.01010101 2.03030303 2.05050505 2.07070707
2.09090909 2.11111111 2.13131313 2.15151515 2.17171717 2.19191919
2.21212121 2.23232323 2.25252525 2.27272727 2.29292929 2.31313131
2.33333333 2.35353535 2.37373737 2.39393939 2.41414141 2.43434343
2.45454545 2.47474747 2.49494949 2.51515152 2.53535354 2.55555556
2.57575758 2.5959596 2.61616162 2.63636364 2.65656566 2.67676768
2.6969697 2.71717172 2.73737374 2.75757576 2.77777778 2.7979798
2.81818182 2.83838384 2.85858586 2.87878788 2.8989899 2.91919192
2.93939394 2.95959596 2.97979798 3. ]
>>>
变量初始化
对于四个相关的tensorflow中使用到的变量进行如下设定:
其中X和Y用于上述训练输入数据的输入
X = tf.placeholder("float",name="X")
Y = tf.placeholder("float",name="Y")
W = tf.Variable(3., name="W")
B = tf.Variable(3., name="B")
设定模型
设定模型为X*W + B
linearmodel = tf.add(tf.multiply(X,W),B)
损失函数
loss function也被成为cost function,这里使用方差作为损失函数,用于确认期待值和计算值之间的差距。
lossfunc = (tf.pow(Y - linearmodel, 2))
Optimizer
tensorflow的train中包含多种Optimizer,这里使用最为常用的梯度下降的优化器,以在不断的运算中调整参数的值。这里设定Learning Rate为0.01, 设定过小,收敛速度可能会很慢,但是过大反而可能会导致不收敛,需要根据具体情况进行调整。
learningrate = 0.01
trainoperation = tf.train.GradientDescentOptimizer(learningrate).minimize(lossfunc)
初期化Session
进行训练之前,对session进行初期化
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
进行训练
至此,所需要的准备已经全部完毕,科技进行训练了,而训练而只是使用前面简单例子中说明的方法,向X和Y中灌入训练数据即可。
这里特意使用一个简单的两层循环来说明数据训练的层次,内层i对应xdata和ydata的100条数据,外层j表示对此训练数据整体循环的次数。总体数据运算次数为:100*100 = 10000次
print("caculation begins ...")
for j in range(100):
for i in range(100):
sess.run(trainoperation, feed_dict={X: xdata[i], Y:ydata[i]})
结果展示
使用scatter展示训练数据的分布状况,使用plot显示训练后数据:
plt.scatter(xdata,ydata)
plt.plot(xdata,B.eval(session=sess)+W.eval(session=sess)*xdata,'b',label='caculated : w*x + b')
plt.legend()
plt.show()
数据预测
训练稳定后的模型,可以用来预测训练数据以外的其他情况,这里使用如下测试数据:
| 测试数据(自变量X) | 期待结果 |
|---|---|
| 3 | 3*2 + 1 = 7 |
| 10 | 10*2 + 1 =21 |
示例代码
liumiaocn:Notebook liumiao$ cat basic-operation-6.py
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
xdata = np.linspace(0,1,100)
ydata = 2 * xdata + 1
print("init modole ...")
X = tf.placeholder("float",name="X")
Y = tf.placeholder("float",name="Y")
W = tf.Variable(3., name="W")
B = tf.Variable(3., name="B")
linearmodel = tf.add(tf.multiply(X,W),B)
lossfunc = (tf.pow(Y - linearmodel, 2))
learningrate = 0.01
print("set Optimizer")
trainoperation = tf.train.GradientDescentOptimizer(learningrate).minimize(lossfunc)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
print("caculation begins ...")
for j in range(100):
for i in range(100):
sess.run(trainoperation, feed_dict={X: xdata[i], Y:ydata[i]})
#print("i = " + str(i) + "b: " + str(B.eval(session=sess)) + ", w : " + str(W.eval(session=sess)))
print("caculation ends ...")
print("##After Caculation: ")
print(" B: " + str(B.eval(session=sess)) + ", W : " + str(W.eval(session=sess)))
print(" B: 2 W: 1 (Real Value)")
print("##Test for the trained model: Y = X*W + B")
testxdata = 3.
expectydata = testxdata*2 + 1
calculatedydata = W.eval(session=sess) * testxdata + B.eval(session=sess)
precision = 100 - np.abs(calculatedydata/expectydata - 1) * 100
print(" X=%f , Y = ? (2*%f + 1 = %f)" %(testxdata,testxdata,expectydata))
print(" Y= %f, pricse = %f %%" %(calculatedydata,precision))
testxdata = 10.
expectydata = testxdata*2 + 1
calculatedydata = W.eval(session=sess) * testxdata + B.eval(session=sess)
precision = 100 - np.abs(calculatedydata/expectydata - 1) * 100
print(" X=%f , Y = ? (2*%f + 1 = %f)" %(testxdata,testxdata,expectydata))
print(" Y= %f, pricse = %f %%" %(calculatedydata,precision))
plt.scatter(xdata,ydata)
plt.plot(xdata,B.eval(session=sess)+W.eval(session=sess)*xdata,'b',label='caculated : w*x + b')
plt.legend()
plt.show()
liumiaocn:Notebook liumiao$
结果确认
测试数据覆盖状况
使用测试数据3与10,使用上面100次迭代后得到的Model进行预测,与期待值有较好的一个匹配,达到了99.999%
liumiaocn:Notebook liumiao$ python basic-operation-6.py
init modole ...
set Optimizer
caculation begins ...
caculation ends ...
##After Caculation:
B: 0.99998814, W : 2.0000176
B: 2 W: 1 (Real Value)
##Test for the trained model: Y = X*W + B
X=3.000000 , Y = ? (2*3.000000 + 1 = 7.000000)
Y= 7.000041, pricse = 99.999413 %
X=10.000000 , Y = ? (2*10.000000 + 1 = 21.000000)
Y= 21.000165, pricse = 99.999216 %
liumiaocn:Notebook liumiao$
训练数据覆盖状况
使用梯度下降的方式所计算出来的曲线,可以看出将输入数据几乎完全覆盖
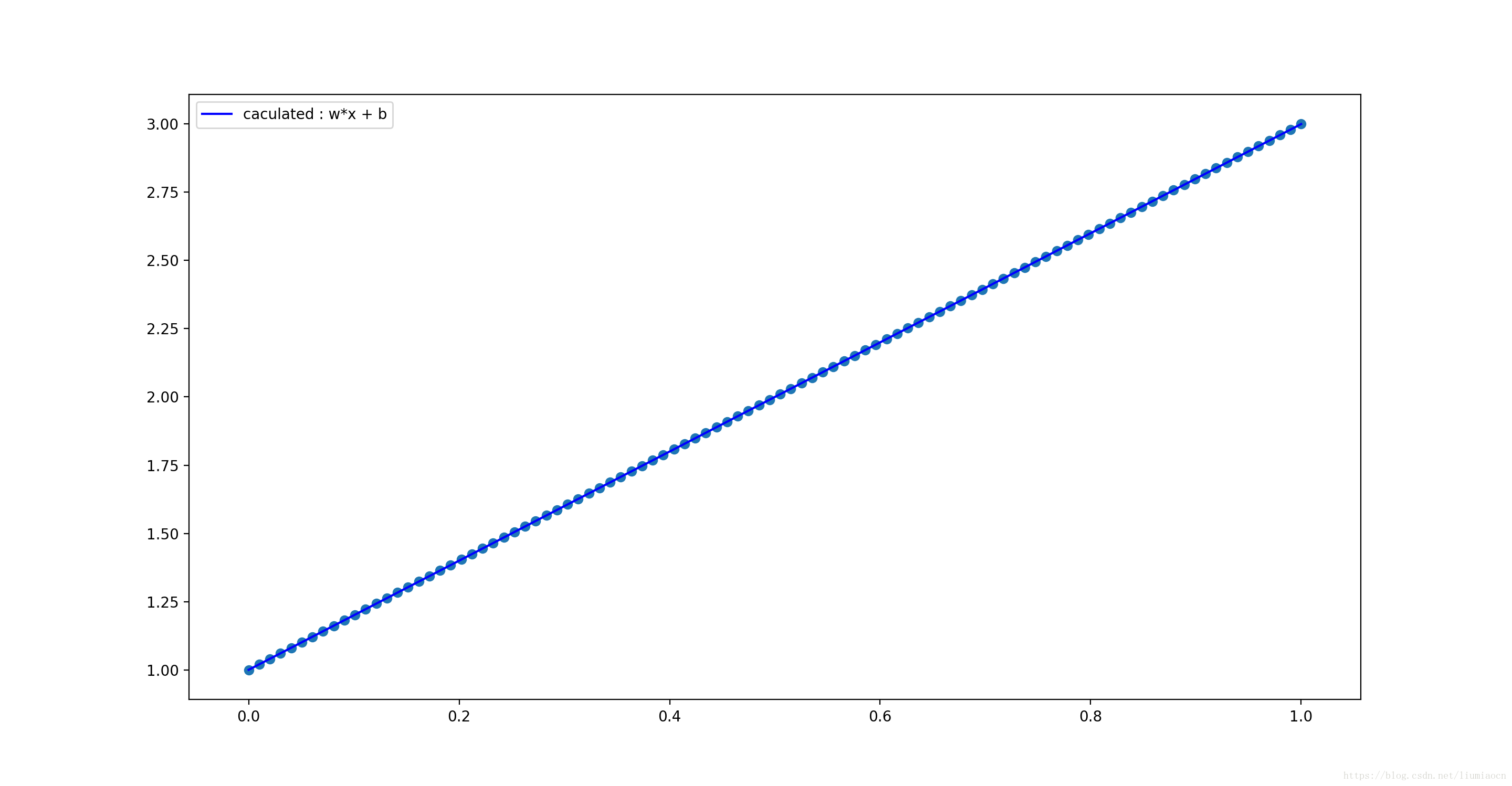
这里就是典型的测试数据和训练数据都有很好的结果的状况,基本上就是理想状况,原因当然和很简单,因为是完美的数据,超级简单的线性模型。
总结
通过这篇文章,虽然只是一个非常简单的线性回归模拟,我们了解到了tensorflow使用的方式,看到了有导师监督的算法的训练和使用方式,也可以看出tensorflow的强大,至少梯度下降只需要设定Learningrate即可,不再需要再确认导数相关的内容,也不必过于担心简单编码错误导致的结论错误,节省了很多的时间,所以即使没有强大的数学底子,进行AI的研究也不是不可能了,极大地降低了入门的门槛。
接下来,我们将会继续使用这样一个超级简单的例子,来模拟实际环境中的各种情况比如影响数据的模拟下的,同样的迭代所能达到的程度等更为具体的情况。