版本说明:
caffe为windows版本,vs对应的是2012版本,我是用生成exe+windows批处理的方式来使用caffe的。
已经配置好的caffe可见http://pan.baidu.com/s/1gf0iTKB
使用的并不是最新版的caffe,不过在windows下算是很新的啦。
数据生成
首先生成训练和测试目录,我是以人脸的CMU数据库为例进行说明。下面的名字可以根据自己需要进行修改。
训练文件夹CMUtrain如图所示,测试文件夹依照同样方式生成。训练文件夹里边还需要有一个train.txt如图2所示用于记录所有训练数据的相对存储位置以及对应类别。这个我是用Python做文件夹遍历自动生成的。训练与测试用的图片都需要正规化到一定大小,我是正规化到64*64。
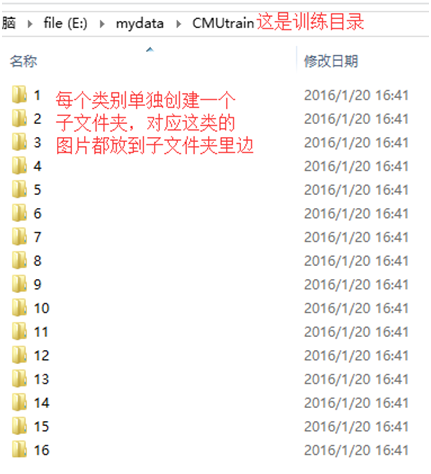
图1.训练文件夹情况
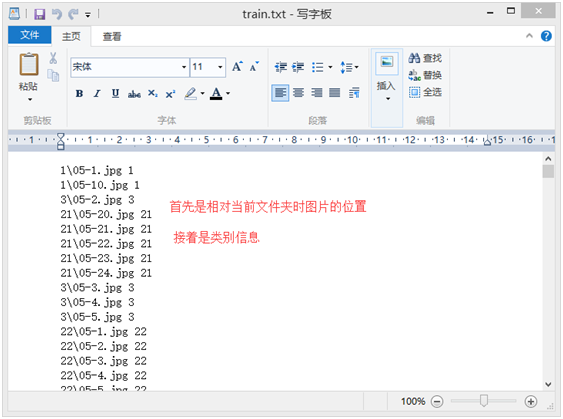
图2.train.txt
接着我在Caffe For Windows VS2012文件夹里边生成一个CMUdata文件夹,之后的实验都会在里边进行。首先把训练文件夹和测试文件夹都复制到里边。接着就是将数据转化为caffe使用的数据格式。
我们运行createD-B.bat,双击这个文件就可以,然后在目录里边会生成两个levedb文件夹以及一个mean.binaryproto,如图3所示。

图3.生成数据情况
createD-B.bat内容如下所示:
SET GLOG_logtostderr=1
"../bin/convert_imageset.exe" ./CMUtrain/ ./CMUtrain/train.txt ./cmu-train-leveldb 1
"../bin/compute_image_mean.exe" ./cmu-train-leveldb cmu-mean.binaryproto
"../bin/convert_imageset.exe" ./CMUtest/ ./CMUtest/test.txt ./cmu-test-leveldb 1
pause首先利用了bin文件夹里边的convert_imageset.exe对CMUtrain里边的数据进行处理生成了相应的leveldb格式。
第一个参数是./CMUtrain,
第二个参数是./CMUtrain/train.txt,
第三个参数是./cmu-train-leveldb,表示生成的leveldb的存储位置
第四个参数是1,表示要对数据进行乱序处理,如果不想乱序处理,可以设置为0。
接着调用了compute_image_mean.exe对刚刚生成的cmu-train-leveldb进行处理生成了一个样本均值文件cmu-mean.binaryproto,这个是用来对样本做正规化处理的。
训练配置
数据生成好以后便可以进行训练了。训练需要用到3个prototxt文件,如图4所示,lenet_train.prototxt文件记录了训练用的网络,
lenet_test.prototxt文件记录了测试用的网络,
lenet_solver.prototxt记录了训练时使用的一些参数。
图4.网络配置文件
lenet网络如图5所示,我用lenet_train.prototxt对它进行说明:
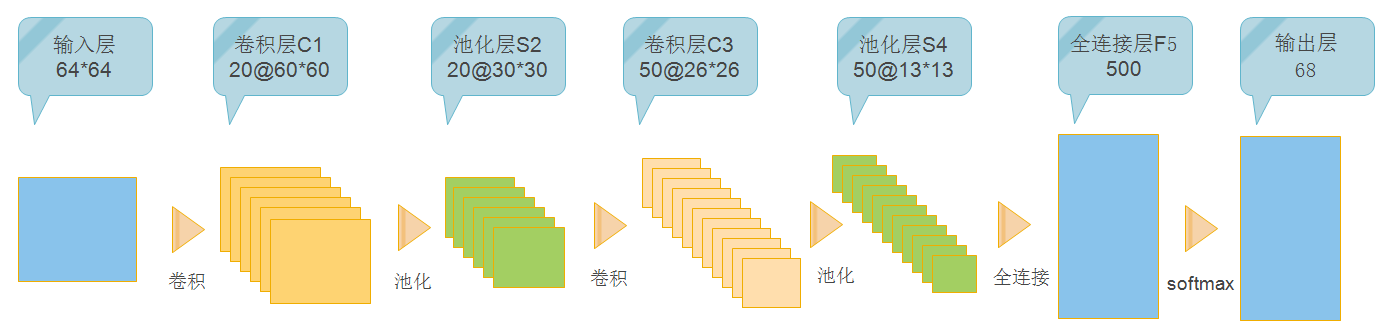
图5.lenet网络
首先是一个输入层,它从source:cmu-train-leveldb里边获取了data和label输出,top后边的项便是这层网络的输出。scale为0.00390625,这个值是1/256,所以是将像素值正规化到0~1,批处理数目设置为100,均值文件用在这里做正规化。
layers {
name: “lenet”
type: DATA
top: “data”
top: “label”
data_param {
source: “cmu-train-leveldb”
scale: 0.00390625
batch_size: 100
mean_file: “cmu-mean.binaryproto”
}
}
接着是一个卷积层conv1,它以上一层的输出data作为输入,bottom后边接的便是输入项,它输出的则是”conv1”。这里关注的主要是卷积参数,num_output=20,kernel_size=5,stride=1表示这一层有20个5*5大小的卷积需要学习,每次卷积步长为1(这个一般不改的)。
layers {
name: “conv1”
type: CONVOLUTION
bottom: “data”
top: “conv1”
blobs_lr: 1
blobs_lr: 2
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: “xavier”
}
bias_filler {
type: “constant”
}
}
}
接着是个池化层,它以conv1为输入,输出pool1,池化采用最大池化方式,池化核为2*2大小,步长为2。
layers {
name: “pool1”
type: POOLING
bottom: “conv1”
top: “pool1”
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
接着是卷积层conv2,池化层pool2,这个就不提了。
然后就是个全连接层了,采用了500个神经元。
layers {
name: “ip1”
type: INNER_PRODUCT
bottom: “pool2”
top: “ip1”
blobs_lr: 1
blobs_lr: 2
inner_product_param {
num_output: 500
weight_filler {
type: “xavier”
}
bias_filler {
type: “constant”
}
}
}
然后到了分类的softmax层,其实也是个全连接层,因为CMU数据库有68类,所以此处输出为68,这个值要根据分类类别数来进行修改。
layers {
name: “ip2”
type: INNER_PRODUCT
bottom: “ip1”
top: “ip2”
blobs_lr: 1
blobs_lr: 2
inner_product_param {
num_output: 68
weight_filler {
type: “xavier”
}
bias_filler {
type: “constant”
}
}
}
最后根据ip2的输出与label进行比较从而判断损失值进行网络更新。
layers {
name: “loss”
type: SOFTMAX_LOSS
bottom: “ip2”
bottom: “label”
}
lenet_test的不同之处在于最后多了一个判断准确率的accuracy层。
另外lenet_test的输入层则是从cmu-test-leveldb里边获取数据。
layers {
name: “accuracy”
type: ACCURACY
bottom: “prob”
bottom: “label”
top: “accuracy”
}
lenet_solver里边参数作用如下:
train_net:记录lenet_train.prototxt的位置
test_net: 记录lenet_test.prototxt的位置
test_iter: 与batch_size搭配使用,比如说有1W个训练样本,batch_size设置为100,那这里就是1W/100=100
test_interval: 训练迭代N次之后测试一下网络在测试集上的准确率并输出。
base_lr: 学习率,这个就是根据网络不断调整了,一般都不太大
momentum: 冲量,避免网络训练陷入极值情况跳不出来
weight_decay: 权重衰减,base_lr好像每迭代一次会乘以(1-weight_decay)。
max_iter:最大迭代次数
snapshot: 每训练迭代N次存储一下网络结构
snapshot_prefix: 存储的网络结构命名时的前缀
solver_mode: GPU或者CPU
开始训练
双击train_lenet.bat便开始了训练。
批处理文件内容如下:
SET GLOG_logtostderr=1
“../bin/train_net.exe” lenet_solver.prototxt
pause
它调用了train_net.exe,并传入lenet_solver.prototxt文件。
网络配置没有问题的话,如图6所示便会开始构建我们设计的网络了。
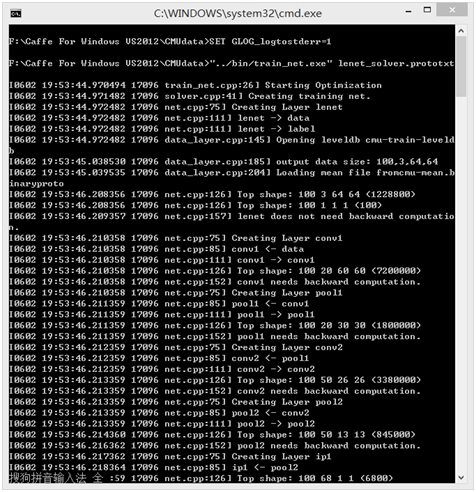
图6.运行
之后每100次迭代会显示下学习率以及损失值,500次迭代时则是会测试下网络并保存此时的网络如图7所示。500次迭代保存的网络会有两个文件,一个是“lenet_iter_500.solverstate”,还有一个是“lenet_iter_500”,如图8所示。
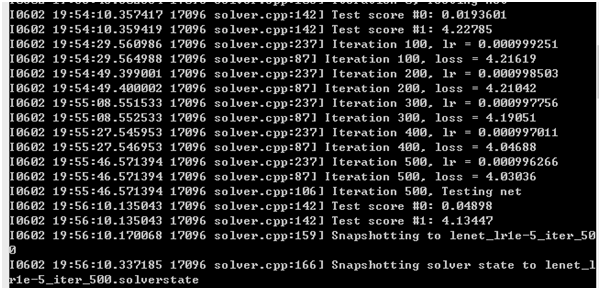
图7.运行
图7.网络保存
一般是先以一个lr训练一段时间,从中找到最好的一个结果,然后降低lr,在这个最好结果基础上继续进行训练。比如说想在上面500次网络的基础下继续进行训练,那么可以将train_lenet.bat修改为如下,具体可见train_lene2.bat文件。
“../bin/train_net.exe” lenet_solver.prototxt “lenet_iter_500.solverstate”
到此训练过程差不多就结束了啊,多调调就行了。
可选:提取特征
如果只是把网络结构作为一个特征提取工具,比如上面的lenet结构,我想把全连接层的输出作为特征提取出来,那么运行extract.bat即可。
它内容如下:
SET GLOG_logtostderr=1
"../bin/extract_features.exe" lenet_iter_500 lenet_train.prototxt ip1 train-extract-leveldb 100 GPU
"../bin/extract_features.exe" lenet_iter_500 lenet_test.prototxt ip1 test-extract-leveldb 100 GPU
pause几个参数做下说明:
lenet_iter_500是我们训练得到的网络,这个就是上面500次训练后保存的。
lenet_train.prototxt是训练网络的配置。
ip1是lenet_train.prototxt里边我们需要提取特征的那一层的name。
100,这个就是lenet_solver里边的test_iter,和batch_size一起使用,相乘应该为样本总数。
train-extract-leveldb:提取得到的特征保存的名字。
最后则是模式选择,GPU或者CPU
可选:可执行文件的生成
这个版本是vs2012版本,所以工程要用vs2012打开啊。
首先到example文件夹里边打开MainCaller.cpp,里边的那些include选择一个取消注释,其它的都要加上注释的。
比如说相要生成train_net.exe,那就只让第一行的
#include “../../tools/train_net.cpp”没有注释。
然后打开build\MSVC文件夹里边的sln,在外部依赖项里边能够找到train_net.cpp,打开它便能看到它的实现,然后就了解了这个exe该如何添加参数。生成它的话直接调试生成即可生成exe。
在bin文件夹里边会生成一个MainCaller.exe,我们把它修改为train_net.exe就可以了。
下面以AR数据库为例做个详细说明
AR数据库的数据准备
首先是将AR数据库转化为caffe所用leveldb的预处理准备。
caffe提供了convert_imageset.exe和compute_image_mean.exe两个可执行程序供我们转换数据,所以我首先要根据它们的输入做好准备。
AR数据库有100个类,50个男人,50个女人,每个人有26张图片。
如下所示,我需要创建一个ARTrain目录,在这个目录里边为每个类分别创建一个子文件夹用于存储每个类的训练图片。
同时我在ARTrain目录里边新建一个train.txt,它里边记录了各个类里边包含的文件以及对应的类标签。
因为在AR中男性图片命名规则为m_001_001.pgm,女性则为w_001_001.pgm,所以女性的类为图片中的类标签,男性的则是图片类标签+50。
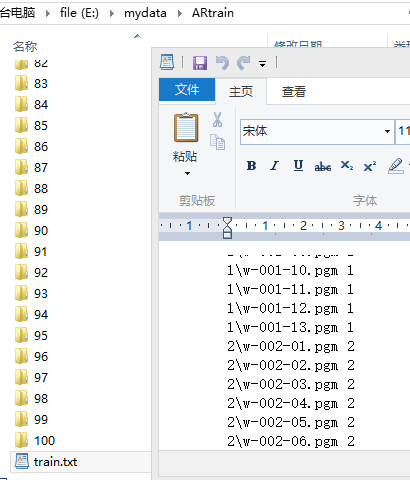
处理好了train之后还需要处理test,我目前是把每个人的前13张作为训练,后13张作为测试。
整个过程我用一个python文件来进行执行:
# -*- coding: utf-8 -*-
from shutil import *
import os
import os.path
import Image
import string
#rootdir用来记录AR数据库的保存位置
rootdir = "E:\\database\\AR"
#datadir则是用来记录最后数据保存的位置,可以自行设定
datadir = "E:\\mydata\\ARtest"
if not os.path.exists(datadir):
os.mkdir(datadir)
#如果datadir是train,那这里打开的就是train.txt了,自行修改
f = open(os.path.join(datadir, "test.txt"), "w")
for parent, dirnames, filenames in os.walk(rootdir):
for filename in filenames:
if filename.endswith("pgm"):
#print filename
sp = filename.split('-')
sex = sp[0]
classlabel = string.atoi(sp[1])
if sex == 'm':
classlabel = classlabel + 50
classdir = datadir + "\\" + str(classlabel)
if not os.path.exists(classdir):
os.mkdir(classdir)
seqstr = sp[2].split('.')[0]
seq = string.atoi(seqstr)
#如果是train,那么就改成if seq <= 13
if not seq <= 13:
if not os.path.exists(os.path.join(classdir, filename)):
print seq
im = Image.open(os.path.join(parent, filename))
resizedIm = im.resize((250,250), Image.ANTIALIAS)
resizedIm.save(os.path.join(classdir, filename))
f.write(str(classlabel) + "\\" + filename + " " + str(classlabel) + "\n")
f.close()