版权声明:本博所有原创文章,欢迎转载,转载请注明出处 https://blog.csdn.net/qq_34553043/article/details/83045285
对应代码
监督学习过程: 最小化误差同时规划参数。例如公式中的L项作用是拟合数据, 项作用是防止过拟合,简化模型使模型具有更好的泛化能力
当模型复杂化,产生过拟合时,可增大 或者选择其他形式的 ,使 所占的比重增大,约束参数。
这里挑选部分范数说明。
L0范数和L1范数
L0范数是指向量中非零元素的个数。如果用L0规则化一个参数矩阵W,就是希望W中大部分元素是零,实现稀疏化。
L1范数也称为曼哈顿距离。
如图,目标函数是(w1,w2)空间上的等高线,L1范数则是一个正方形。两者最优解在相交于坐标轴处。那么存在一个权重参数为0,即稀疏化。
L0和L1都可以实现稀疏化,不过一般选用L1而不用L0,原因包括:1)L0范数很难优化求解(NP难);2)L1是L0的最优凸近似,比L0更容易优化求解。(这一段解释过于数学化,姑且当做结论记住)
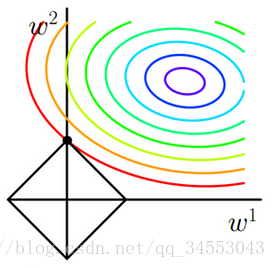
L2范数
L2范数也称为欧几里得距离和。
与L1范数不同的是L2范数与目标函数最优解并不在坐标轴上,L2会选择更多特征。但因为L2范数的规则项||W||2 尽可能小,可以使得W每个元素都很小,接近于零。
