OCR,全称Optical character recognition,中文译名叫做光学文字识别。它把图像中的字符,转换为机器编码的文本的一种方法。OCR技术在印刷行业应用得非常多,也广泛用于识别图片中的文字数据 – 比如护照,支票,银行声明,收据,统计表单,邮件等。
pytesseract,即Python-tesseract,是Google Tesseract ORC引擎的封装。首次于2014年提出,支持的图片格式有’JPEG’, ‘PNG’, ‘PBM’, ‘PGM’, ‘PPM’, ‘TIFF’, ‘BMP’, ‘GIF’,只需要简短的代码就能够提取图片中的字符合文字了,极大方便文字工作。
准备工作
1,安装pillow或者PIL,主要用来打开本地图片
pip install PIL
pip install pillow
2,安装pytesseract,主要用来将图片里面文字转化字符串或者pdf
pip install pytesseract
3,安装 Tesseract-OCR应用程序
进入 https://pan.baidu.com/s/1qXumxdltxOnb0geaE_1U-Q下载安装
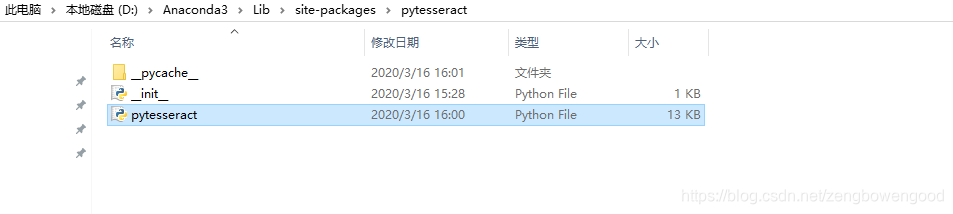
4,修改 pytesseract 源码中的路径
进入D:\Anaconda3\Lib\site-packages\pytesseract,用Notepad++打开pytesseract.py,将源码第26行的路径修改成安装Tesseract-OCR应用程序路径。
tesseract_cmd = 'tesseract.exe'
修改成
tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
5,安装中文字库
进入https://pan.baidu.com/s/1GfspC5uef73B2Oa8YudBgQ,下载中文库复制到 Tesseract-OCR 安装目录下的 tessdata 文件夹中

原图片

完整代码
from PIL import Image
import pytesseract
image = Image.open("粉丝.jpg") #打开图片
#print(image.size) #测试图片像素尺寸
text = pytesseract.image_to_string(image, lang='chi_sim') #图片转字符串
text = text.replace("“ ","").replace("。","") #去掉杂质,提纯
print(text) #测试结果
结果预览
关 注 我 的 人
共 634 位
排 行 榜 用 户 分 析
1 上 海 133 人 21.0%
2 邵 阳 64 人 10.1%8
3 北 京 34 人 5.4%
4 广 州 19 人 3.0%
5 深 圳 18 人 2.8%
6 武 汉 16 人 2.5%
7 阜 阳 13 人 2.1%
8 长 沙 12 人 1.9%
9 成 都 1 人 1.7%
10 南 京 1 人 1.7%
人 重 庆 10 人 1.6%
12 苏 州 9 人 1.4%
13 杭 州 8 人 1.3%
14 西 安 6 人 0.9%
15 滩 坊 6 人 0.9%
16 美 国 5 人 0.8%
17 合 肥 5 人 0.8%
18 宁 波 5 人 0.8%
19 徐 州 5 人 0.8%
20 厦 门 4 人 0.6%
21 十 堰 4 人 0.6%
22 绍 兴 4 人 0.6%
23 哈 尔 滨 4 人 0.6%
24 石 家 庄 4 人 0.6%
25 沈 阳 4 人 【
26 济 南 4 人 0.6%
27 江 门 3 人 0.5%
28 洛 阳 3 人 0.5%
29 焦 作 3 人 0.5%
30 安 阳 3 人 0.5%
31 郁 州 3 人 0.5%
32 东 菀 3 人 0.5%
33 尾 明 3 人 0.5%
34 中 山 3 人 0.5%
35 长 春 3 人 0.5%
36 济 宁 3 人 0.5%
37 株 洲 3 人 0.5%
38 呼 和 浩 特 3 人 0.5%
39 贵 阳 3 人 0.5%
40 铜 仁 3 人 0.5%
41 长 治 3 人 0.5%
42 泰 安 2 人 0.3%
43 怀 化 2 人 0.3%
44 崴 州 2 人 0.3%
45 濮 阳 2 人 0.3%
46 聊 城 2 人 0.3%
47 邢 台 2 人 0.3%
48 烟 台 2 人 0.3%
49 湖 南 省 2 人 0.3%
50 保 定 2 人 0.3%
51 岳 阳 2 人 0.3%
52 常 德 2 人 0.3%
53 永 州 2 人 0.3%
54 天 津 2 人 0.3%
55 广 东 省 2 人 0.3%
56 秦 皇 峤 2 人 0.3%
57 湛 江 2 人 0.3%
58 揭 阳 2 人 0.3%
59 南 宁 2 人 0.3%
60 贺 州 2 人 0.3%
61 兰 州 2 人 0.3%
62 巴 音 郭 楼 2 人 0.3%
63 加 拿 大 2 人 0.3%
64 忻 州 2 人 0.3%
65 无 锡 2 人 0.3%
66 温 州 2 人 0.3%
67 芳 湖 2 人 0.3%
68 临 汾 2 人 0.3%
69 安 庆 2 人 0.3%
70 满 州 2 人 0.3%
71 吕 梁 2 人 0.3%
72 吉 林 2 人 0.3%
73 运 城 2 人 0.3%
74 根 州 1 人 0.2%
75 广 元 1 人 0.2%
76 松 原 1 人 0.2%
77 攀 枝 花 1 人 0.2%
78 泸 州 1 人 0.2%
79 宥 宾 1 人 【
80 绵 阳 1 人 0.2%
81 铁 峙 1 人 0.2%
s 遮 押 晚 白 人 02x
83 蹇萱黎族自 1 人 0.2%
84 海 口 1 人 0.2%
85 贵 潜 1 人 0.2%
86 桂 林 1 人 0.2%
87 营 口 1 人 0.2%
88 白 城 1 人 0.2%
89 百 色 1 人 0.2%
90 甘 孜 1 人 0.2%
91 北 海 1 人 0.2%
92 柳 州 1 人 0.2%
93 韶 关 1 人 0.2%
94 鞍 山 1 人 0.2%
95 梅 州 1 人 0.2%
96 辽 阳 1 人 0.2%
97 汕 属 1 人 0.2%
98 肇 庆 1 人 0.2%
99 包 头 1 人 0.2%
100 未 知 地 域 1 人 0.2%
101 荷 兰 1 人 0.2%
102 日 本 1 人 0.2%
103 英 国 1 人 0.2%
104 晋 中 1 人 0.2%
105 澳 大 利 亚 1 人 0.2%
106 奥 地 利 1 人 0.2%
107 昌 吉 1 人 0.2%
108 克 拉 玛 依 1 人 0.2%
109 银 川 1 人 0.2%
10 黄 南 1 人 0.2%
111 平 凉 1 人 0.2%
112 武 威 1 人 0.2%
113 达 州 1 人 0.2%
14 榆 林 1 人 0.2%
115 延 安 1 人 0.2%
116 宝 鸡 1 人 0.2%
117 香 潜 1 人 0.2%
8 呼 伦 贝 尔 1 人 0.2%
119 黔 东 南 1 人 0.2%
120 大 连 1 人 0.2%
121 邋 义 1 人 0.2%
122 六 盘 水 1 人 0.2%
123 葫 芦 岛 1 人 0.2%
124 延 边 1 人 0.2%
125 眉 山 1 人 0.2%
126 德 州 1 人 0.2%
127 信 阳 1 人 0.2%
128 新 乡 1 人 0.2%
129 台 州 1 人 0.2%
130 开 封 1 人 0.2%
131 嘉 兴 1 人 0.2%
132 衢 州 1 人 0.2%
133 金 华 1 人 0.2%
134 日 照 1 人 0.2%
135 张 家 口 1 人 0.2%
136 溏 博 1 人 0.2%
137 _ 临 沂 1 人 0.2%
138 菏 泽 1 人 0.2%
139 淮 北 1 人 0.2%
140 许 昌 1 人 0.2%
141 铜 陵 1 人 0.2%
142 青 岛 1 人 0.2%
143 新 余 1 人 0.2%
144 景 德 镇 1 人 0.2%
145 衡 水 1 人 0.2%
146 南 昌 1 人 0.2%
147 宁 德 1 人 0.2%
148 莲 田 1 人 0.2%
149 三 明 1 人 0.2%
150 泉 州 1 人 0.2%
151 六 安 1 人 0.2%
152 福 州 1 人 0.2%
153 梦 州 1 人 0.2%
154 滕 州 1 人 0.2%
155 佛 山 1 人 0.2%
156 鸣 州 1 人 0.2%
157 珠 海 1 人 0.2%
158 沧 州 1 人 0.2%
159 江 苏 省 1 人 0.2%
160 云 浮 1 人 0.2%
161 晋 城 1 人 0.2%
162 娄 底 1 人 0.2%
163 扬 州 1 人 0.2%
164 常 州 1 人 0.2%
165 唐 山 1 人 0.2%
166 湘 潭 1 人 0.2%
167 汕 头 1 人 0.2%
168 衡 阳 1 人 0.2%
169 连 云 湛 1 人 0.2%
170 张 家 界 1 人 0.2%
171 大 同 1 人 0.2%
172 盐 城 1 人 0.2%
173 黄 冈 1 人 0.2%
174 襄 糜 1 人 0.2%
175 宣 昌 1 人 0.2%
176 太 原 1 人 0.2%
177 庾 坊 1 人 0.2%
178 湖 北 省 1 人 0.2%
179 周 口 1 人 0.2%
全 部 加 载 完 成
结果还是不错的,90%都识别出来了,只是汉字之间都是空格隔开,可以考虑replace掉。
参考文献
1,https://github.com/madmaze/pytesseract
