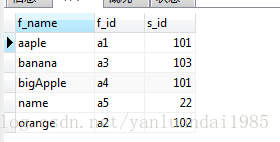
7.2.11 对查询结果进行排序
根据字母进行排序,或者根据数字进行排序。默认是升序 ASC
SELECT
f_name,
f_id,
s_id
FROM
fruits
ORDER BY
f_name;
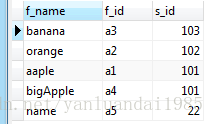
降序的话,只需要加上 DESC
SELECT
f_name,
f_id,
s_id
FROM
fruits
ORDER BY
s_id DESC
有时,需要根据多列进行排序。比如当成绩相同的时候,按照名字降序排列。
CREATE TABLE t_student
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
score INT(11) NOT NULL
);
INSERT INTO t_student(name,score) VALUES('jay',60),('jea',60),('dayu',90);
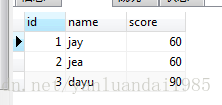
升序与降序,究竟是哪个方向?
如下所示,从第一条记录开始,往下比较指定的字段。如果越来越高,说明就是升序。
从第一条记录开始,往下比较指定的字段。越来越低,说明就是降序。
SELECT * FROM t_student ORDER BY score ASC;
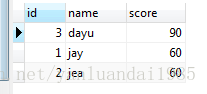
搞明白了升序与降序的区别,那么再来看新的需求。按照成绩降序排列,成绩高的人自然在上面,字母按照'a'--'z'大小递增的规律比较。现需求为:按照成绩降序排列,且相同分数的人按照名字升序排列(名字小的人在上面)。
对于多列数据进行排序,只需要用逗号隔开,并指明其排列是升序还是降序。升序降序的原则是拿第一条记录的值与下面的记录比较,变得越来越大就是升序,变得越来越小就是降序。
另外,进行多列排序必须要满足第一个排序条件相同。如果第一个排序条件的字段是唯一的,那么压根就不会出现比较第二个排序条件。
SELECT * FROM t_student ORDER BY score DESC , name ASC
7.2.12 分组查询
DROP TABLE IF EXISTS t_student;
CREATE TABLE t_student
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
classId INT(11) NOT NULL
);
INSERT INTO t_student(name,classId) VALUES('大宇',1),('小大宇',1),('大大宇',1),('小雨',2),('毛毛雨',2);
SELECT * FROM t_student;

现有5个学生,3个是一班的,2个是二班的。
现在需求是统计每个班的学生的数量,所以要用到分组查询。
分组查询是按照某个或多个字段进行分组。使用的是GROUP BY 关键字。语法:
GROUP BY 字段 HAVING 条件
如果执行SELECT * FROM 表 GROUP BY 指定字段; 那么,会把每个组的第一条数据查询出来。其它的不显示。
SELECT
classId,
count(0) AS stuNumber,
name
FROM
t_student
GROUP BY
classId
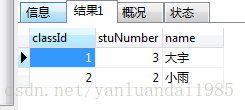
可以看到,现在是把每个班的学生的数量正确的查询出来了,但是如果加了name,仿佛就是说1班所有的学生的名字都叫大宇,2班所有的学生的名字都叫小雨,这显然是不对的。那如何才能正确获取到这个班的学生的名字呢?
原来,GROUP BY关键字常与集合函数一切使用。常见的集合函数比如MAX() MIN() COUNT() SUM() AVG()。这里使用的是一个叫GROUP_CONCAT的函数,可以把需要的字段全部连接起来。
SELECT
classId,
count(0),
GROUP_CONCAT(name)
FROM
t_student
GROUP BY
classId
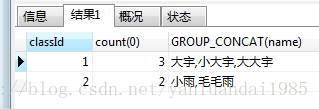
新的需求是,查询班级人数至少是3个人的班级。
语法规则为 GROUP BY 字段 HAVING 条件。 这里把WHERE 换成了 HAVING。
虽然过了这么久才再次重新学习数据库,但是我还能清楚的记得那年大三的在上《数据库原理》的时候,田教授在讲台上疯狂强调这个HAVING o(∩_∩)o 哈哈。
SELECT
classId,
count(0),
GROUP_CONCAT(NAME)
FROM
t_student
GROUP BY
classId
HAVING
COUNT(NAME) > 2

卧槽,新的需求又来了,需要统计所有的记录的总和,即统计记录的数量。(了解)
使用的语法关键字为: GROUP BY 字段 WITH ROLLUP
SELECT
classId,
count(0)
FROM
t_student
GROUP BY
classId WITH ROLLUP
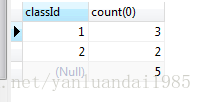
分组系列的最后坑爹需求:多字段分组。
我算是明白了,按照具体的某个字段分组,即会把相同字段的多条记录视为一条记录,并只展示这个组里的第一条数据给客户端。若是多字段分组,那么也就是把多个字段视为一个依据。比如 GROUP BY A , B 。 如果两条记录的A字段与B字段一模一样,那么可把这两条记录视为同一组(个)。
SELECT
*
FROM
t_student
GROUP BY
classId , name
因为没有任何两条记录的 classId与name 属性完全一样,所以大家都是独立的分组.

什么?上面的查询结果这么乱,能不能再根据ID排一哈序。原来,GROUP BY HAVING ORDER BY 是可以一起使用的。
一般来说,ORDER BY 会放在SQL的最后,原因是它是对已经条件查询的结果 进行排序。
我总结的关键字顺序 SELECT * FROM table GROUP BY 字段 HAVING 条件 ORDER BY 条件 LIMIT 0,10
SELECT
*
FROM
t_student
GROUP BY
classId,name --多字段分组
ORDER BY
id DESC

7.2.13 分页查询
MySQL的分页查询使用的是LIMIT 关键字,而Oracle用的是 ROWNUM什么的,坑的一批。
LIMIT关键字语法如下:
LIMIT [位偏移量,] 行数
第一条记录的位偏移量是0,第二条记录的位偏移量是1,以此类推。
“行数”是指本次查询返回的记录的条数。
若不指定位偏移量,则将会从表中的第一条记录开始。
根据上述原则,那么应该知道,如果页面传了一个page与limit。并且每页显示的数量是pageSize。那么LIMIT的值应该是
LIMIT (page-1)*pageSize ,limit 。下面的Java代码也印证了我的说法:
public Integer getStart() {
return Integer.valueOf((this.page.intValue() - 1) * this.rows.intValue());
}下面指明位偏移量的例子
SELECT * FROM t_student;

SELECT * FROM t_student
LIMIT 2,3
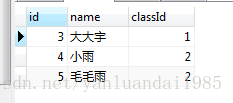
.