朴素贝叶斯法naïve Bayes,在naïve的中间字母上其实有两个点,查了一下才发现是法语中的分音符,在发音过程中发挥作用。但这不是重要的,重要的是在这种学习方法中贝叶斯承担了什么样的角色。
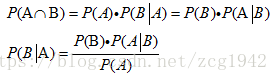
首先简单证明一下贝叶斯公式。联合概率Joint probabilities是可逆的,只要同时满足两个条件就可以,无所谓先满足哪个条件,所以可以有两种写法,都是利用了条件概率Conditionalprobabilities和乘法,因为条件概率就是满足条件之后另外一个事件的概率,这时候再乘条件满足的概率,结果就是联合概率。在最后贝叶斯公式的分母中,P(A)称作先验概率,也称作边际概率Marginal probabilities,一般通过全概率公式求出。
提到贝叶斯定理,就必须要提到贝叶斯学派才能了解这种方法的思想,与其对应的是频率学派。频率学派认为模型的参数是固定的,只不过是未知的,实验次数大到一定程度,频率会稳定于一个固定值,即概率。具体主要通过似然函数求解,如最大似然估计MLE;而贝叶斯是从数据出发,认为参数也是随机变量,拥有概率分布,通过后验概率计算,如最大后验概率MAP,旧的后验会成为新的先验,如此重复下去。贝叶斯学派加入了先验概率,靠谱的先验概率可以使含有随机噪声的数据更加健壮。可以把频率学派中的最大似然看作各种猜测先验概率相等的特殊情况。
我们会发现,频率学派和贝叶斯学派都不约而同地提到了模型,而模型正好是统计机器学习的三要素之一。朴素贝叶斯法,顾名思义,选择了贝叶斯方法构造分类器。输入依然是特征向量x,输出是类标记y。我们希望通过训练数据学习联合概率分布P(X,Y),这说明朴素贝叶斯属于生成模型。具体又是学习y的先验概率和条件概率P(x|y)。既然已经有训练数据,特征和对应的标签类别是已知的,所以根据统计可以很容易地知道y的先验概率。而条件概率就比较棘手了,因为特征空间通常是高维的,所以在已知某个类别下的条件概率有好多个,所以我们做了一个特别重要的假设,叫做条件独立性假设:在类确定的条件下,用于分类的特征是条件独立的。这一假设使得模型包含的条件概率的数量大为减少,简化了学习和预测,缺点是分类的性能不一定很高。
下面还是从三要素的方法研究一下朴素贝叶斯:
模型
前面已经提到了,朴素贝叶斯是生成模型,这是因为它会对联合概率密度P(X,Y)进行估计。具体模型由条件概率表示,所以还属于概率模型(由决策函数表示的模型为非概率模型)。在参考链接3中有这么一句话:贝叶斯非参数模型中的参数数量可以随着数据增大或者减小以适应模型的变化。比较流行的贝叶斯非参数模型还有高斯回归过程,隐含狄利克雷分布(LDA)。选择贝叶斯作为模型是因为我们可以考虑先验概率,特殊的,先验概率相等时,只能依靠似然函数。
策略
我们知道,策略有两种,分别是经验风险最小化和结构风险最小化,前者认为平均损失最小化的模型是最优模型,后者在经验风险最小化的同时还要防止过拟合。从这个角度看,因为极大似然方法因为认为模型参数是固定不变的,就很容易过拟合,而朴素贝叶斯方法选择了最大后验概率作为策略,选择0-1函数作为损失函数。按照书中的推导,为了使期望风险最小化,应该使已知输入特征的后验概率最大化。所以朴素贝叶斯的策略应该是结构风险最小化的策略,先验概率表示了模型的复杂度。
学习方法

方法主要是先估算出先验概率和条件概率,取使得后验概率最大时的y作为输出。根据根据方法采用的是贝叶斯估计还是极大似然函数,又分为两种方法。极大似然估计比较简单,就是利用统计的频率作为概率。但使用极大似然估计可能会出现所要估计的概率值为0的情况,可以采用贝叶斯估计避免。具体来说,对先验概率P(Y),分母和分母分别在极大似然估计的统计上加常数lamda和K*lamda,K表示分类标签数。对条件概率P(X|Y),分子和分母分别加lamda和S*lamda,S代表特征空间的维数。我们常取lamda=1,这是称作拉普拉斯平滑(Laplace smoothing)。
下面再回顾一下信号检测与估计课程中的贝叶斯估计。

至于为什么把它叫做贝叶斯估计,是因为可以根据贝叶斯公式把联合概率密度重写,将问题转换为使条件平均代价最小。

接下来就主要看代价函数的选取,当代价函数选择平方损失函数时,就是最小均方误差估计。当代价函数选择0-1损失函数时,是最大后验估计。估计量使得其后验概率最大。

当代价函数选择绝对损失函数时,贝叶斯估计就是条件中值估计,估计量是随机参数变量的条件中值。
三种代价函数下的贝叶斯估计可以是统计的:当被估计量的后验概率密度函数是高斯型的,三种代价函数下的估计量相同。这就是最佳估计的不变性。
在通信的译码中也有贝叶斯的应用。最小错误概率准则(采用0-1损失函数),即最大后验概率准则。当所有可能消息序列的先验概率相等,最大后验概率准则又等价于最大似然译码准则。在输入不等概分布时采用最大似然译码准则的平均错误概率不是最小。
Refernence:
- 伯乐电影院 http://blog.jobbole.com/111399/
- 频率贝叶斯https://blog.csdn.net/u012116229/article/details/24636001
- 中文分词https://blog.csdn.net/fnqtyr45/article/details/79338829
- 译码https://max.book118.com/html/2016/1214/71919163.shtm