二叉查找树
二叉查找树(BST)具备什么特性呢?
1.左子树上所有结点的值均小于或等于它的根结点的值。
2.右子树上所有结点的值均大于或等于它的根结点的值。
3.左、右子树也分别为二叉排序树。
红黑树
红黑树也是一个二叉查找树,它对二叉查找树的高度问题作了一定的优化。
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
红黑树最重要的作用就是维护二叉查找树(BST)宽度,保持高效平衡红黑树的特性
TreeMap
数据结构为红黑树。
TreeMap特性
尽管如此,HashMap与LinkedHashMap还是有自己的局限性----它们不具备统计性能,或者说它们的统计性能时间复杂度并不是很好才更准确,所有的统计必须遍历所有Entry,因此时间复杂度为O(N)。比如Map的Key有1、2、3、4、5、6、7,我现在要统计:
1.所有Key比3大的键值对有哪些
2.Key最小的和Key最大的是哪两个
就类似这些操作,HashMap和LinkedHashMap做得比较差,此时我们可以使用TreeMap。TreeMap的Key按照自然顺序进行排序或者根据创建映射时提供的Comparator接口进行排序。
TreeMap为增、删、改、查这些操作提供了log(N)的时间开销,从存储角度而言,这比HashMap与LinkedHashMap的O(1)时间复杂度要差些;但是在统计性能上,TreeMap同样可以保证log(N)的时间开销,这又比HashMap与LinkedHashMap的O(N)时间复杂度好不少。
因此总结而言:如果只需要存储功能,使用HashMap与LinkedHashMap是一种更好的选择;如果还需要保证统计性能或者需要对Key按照一定规则进行排序,那么使用TreeMap是一种更好的选择。
TreeSet
TreeSet的数据结构就是基于TreeMap,故它的实现原理和TreeMap相似
Java8 HashMap
JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。时间复杂度为 O(logN)。
其数据结构如下
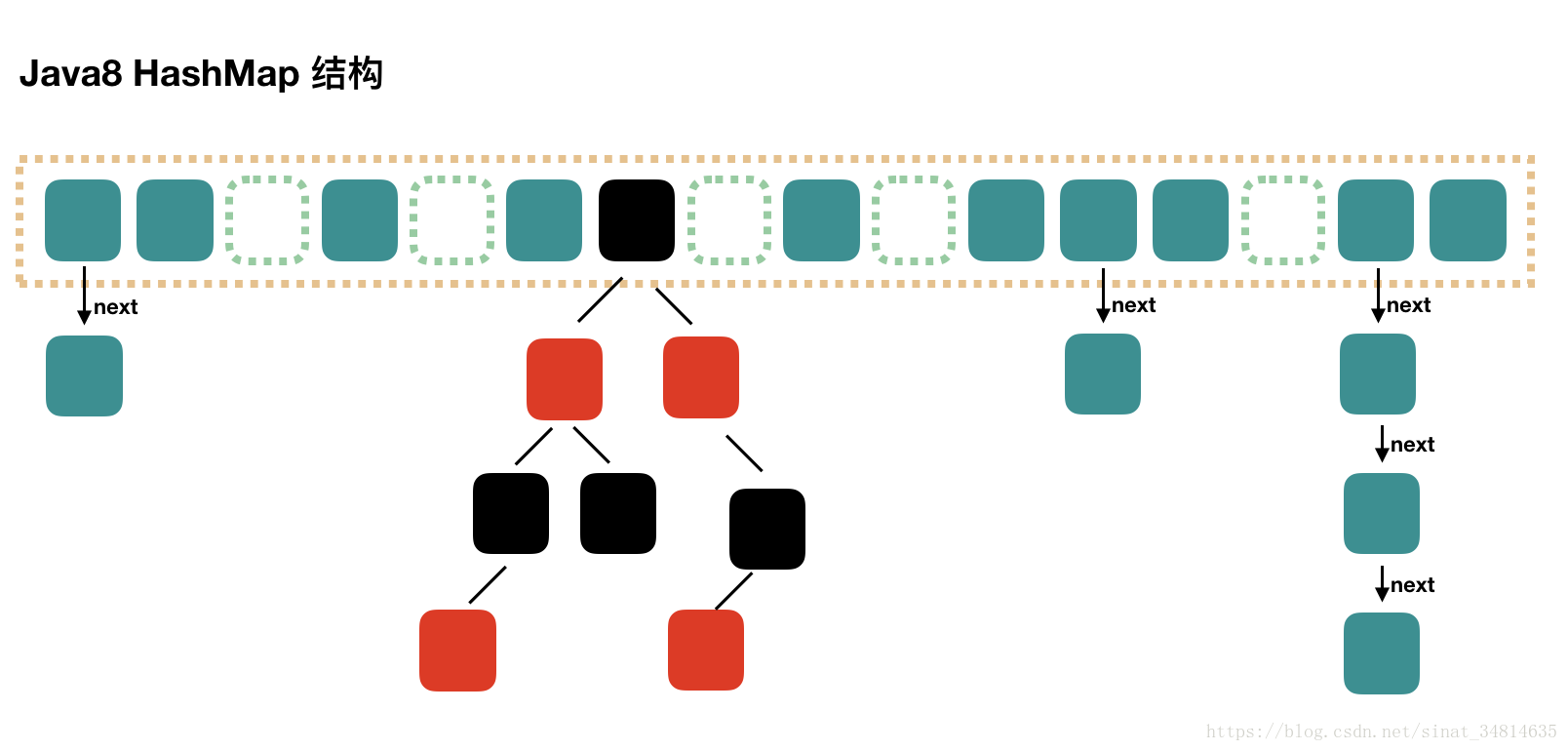
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
put原理
下面简单说下添加键值对put(key,value)的过程:
1,判断键值对数组tab[]是否为空或为null,否则以默认大小resize();
2,根据键值key计算hash值得到插入的数组索引i,如果tab[i]==null,直接新建节点添加,否则转入3
3,判断当前数组中处理hash冲突的方式为链表还是红黑树(check第一个节点类型即可),分别处理
get原理
相对于 put 来说,get 真的太简单了。
1.计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
2.判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
3.判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
4.遍历链表,直到找到相等(==或equals)的 key
Java8 ConcurrentHashMap
数据结构
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,
虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
put原理
1.如果没有初始化就先调用initTable()方法来进行初始化过程
2.如果没有hash冲突就直接CAS插入
3.如果还在进行扩容操作就先进行扩容
4.如果存在hash冲突,就加锁(使用synchronized)来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
5.最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环
6.如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
get原理
ConcurrentHashMap的get操作的流程很简单,也很清晰,可以分为三个步骤来描述
1.计算hash值,定位到该table索引位置,如果是首节点符合就返回
2.如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
3.以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考:
1.JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
2.JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
3.JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
4.JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,
参考资料
1.Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析http://www.importnew.com/28263.html
2.Java中HashMap底层实现原理(JDK1.8)源码分析 https://www.cnblogs.com/little-fly/p/7344285.html
3.漫画算法:什么是红黑树?https://blog.csdn.net/p5deyt322jacs/article/details/78433942
4.图解集合7:红黑树概念、红黑树的插入及旋转操作详细解读https://www.cnblogs.com/xrq730/p/6867924.html
5.图解集合8:红黑树的移除节点操作https://www.cnblogs.com/xrq730/p/6882018.html
6.深入并发包 ConcurrentHashMap http://www.importnew.com/26049.html