版权声明:个人 https://blog.csdn.net/csdnmrliu/article/details/82982183
安装包:spark-2.3.0-bin-hadoop2.7
1. 下载安装包
wget https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz2. 解压缩
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /usr/local3. 配置环境变量
vim /etc/profile
#spark-2.3.1-without-hadoop setting
export SPARK_HOME=/usr/local/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin
#刷新环境变量
source /etc/profile4. spark配置
#配置文件目录
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
export SCALA_HOME=/usr/local/scala-2.11.8
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/usr/local/hadoop-2.7.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-2.3.1-bin-without-hadoop
export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)
export SPARK_MASTER_IP=localhost
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_WORKER_MEMORY=2G
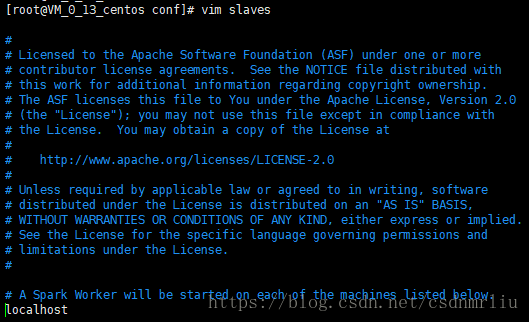
cp slaves.template slaves
#添加hostname
localhost
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.yarn.jars hdfs://localhost:9000//spark_jars/*
cd ../
hadoop fs -mkdir /spark_jars
hadoop fs -put ./jars/* /spark_jars
5. 启动与关闭服务(先启动hadoop)
#进入SPARK_HOME
cd $SPARK_HOME
#启动
./sbin/start-all.sh
#关闭
./sbin/stop-all.sh
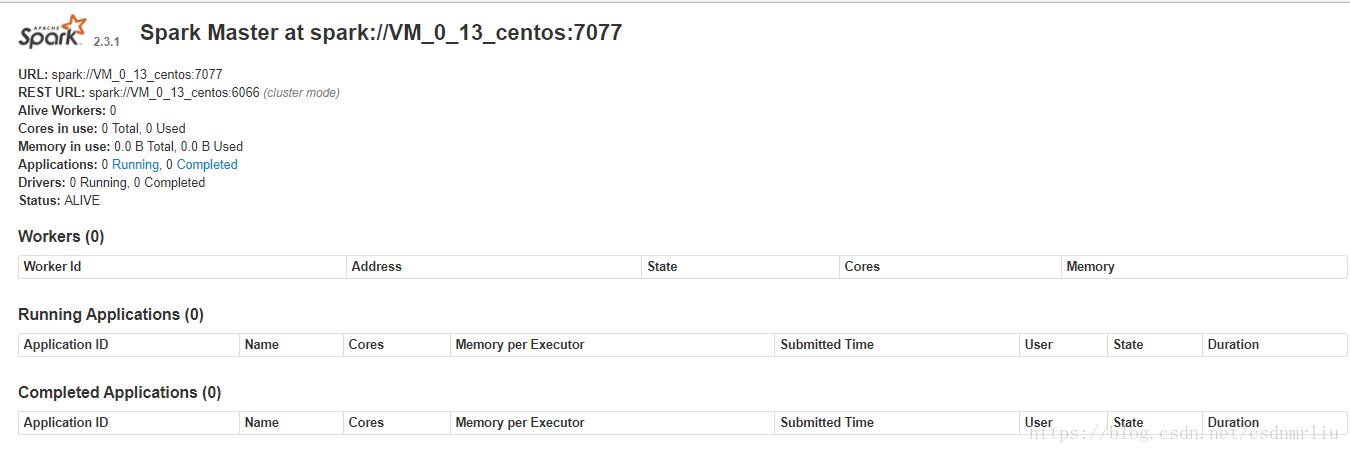
ip:8080