前言
如果你没有见过core dumped,说明你不是一个合格的Coder(但并不代表知道就是合格的Coder),在Linux操作系统下,通过gcc、g++编译出的代码就有可能出现这样的问题(windows下一般都是栈溢出),下面就具体的core dumped的一系列操作作以说明。
什么是core dumped?
core dumped即段错误,当然它也有更官方的说法,称之为核心转储。当某一个进程在异常退出时,内核有可能把该程序当前内存映射到core文件里,即以文件的方式存储于硬盘上,方便后续的gdb调试。
下面看一个简短的程序(非法赋值):
#include <stdio.h>
int main()
{
char* str = "hello world";
str[1] = 'H';
return 0;
}
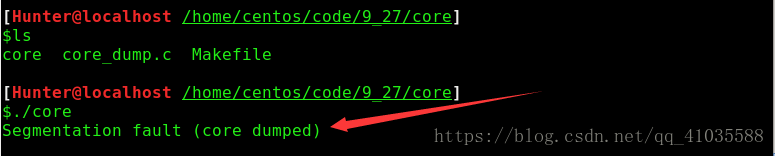
运行结果:
从运行结果可以很清晰的看见core dumped,即段错误,也称核心转储。出现core dumped主要有以下几个原因:
① 内存访问越界:由于使用错误的下标,导致数组越界。
② 多线程程序使用了线程不安全的函数。
③ 多线程读写的数据未加锁保护。
④ 非法指针:比如指针的++操作,使用空指针以及随意转换指针类型等。
⑤ 堆栈溢出。Linux默认的栈大小为10M(与Linux内核版本有关),比如定义一个数组(空间在栈上)大于此默认空间就会溢出。
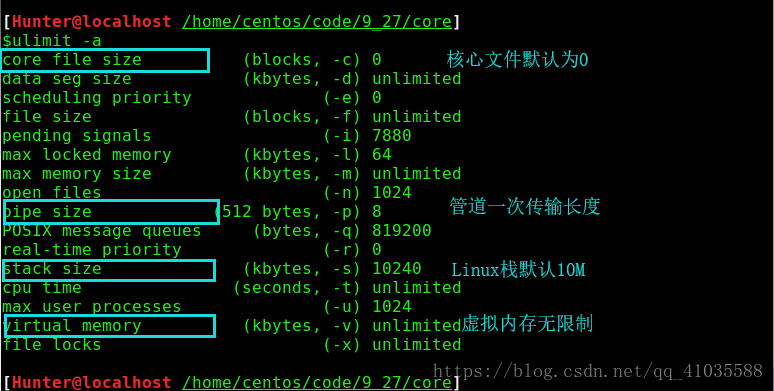
当我们出现core dump时,如何获取具体的错误信息?我们先使用ulimit -a命令来查看系统资源限制。
默认为0,即不会生成core文件,需要修改core file size的值在编译链接时生成core file。
既然core file存储了错误信息,目的是后续的gdb调试,那么为什么操作系统(在Linux下)默认关闭?
如果操作系统对core file默认开启,一旦程序上线之后,程序就脱离了程序员的管理范畴,此时程序员可能不知情,程序一直重启挂掉重启挂掉,那么你的硬盘上就会dump出很多文件,将你的硬盘空间慢慢吞噬,甚至将你的操作系统挂掉。
我们可以使用ulimit -c来改变core文件的大小(临时改变,重启后恢复默认):
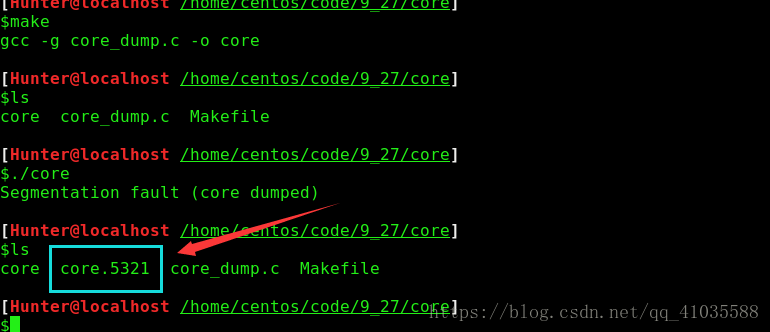
现在我们执行刚才的程序看是否生成了core文件。
从上述结果可以看出,此时重新编译链接会生成一个core.5321的文件,5321为引起错误的进程id。进入gdb模式并定位dump信息需要两步:

① gdb [可执行程序] [dump文件] 进入gdb模式。
② 使用where或core-file [core.(进程号)]定位dump的错误信息。
![[root@bogon Core_file]# gdb Core core.5321](https://img-blog.csdn.net/20180928153037820?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxMDM1NTg4/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
从结果可以看出,程序第12行出错,快速定位了dump的位置。以上就是gdb模式下dump错误信息的定位,下一节我将对gdb的使用技巧作以阐述。