clang static analyzer中使用到的数据结构
注:这篇博客的初衷来源于[Analyzer] Attempting to speed up static analysis
clang static analyzer中使用到的数据结构大致有以下几种,ImmutableMap,ImmutableSet,FoldingSetNode,SmallVector,StringRef以及ArrayRef,这几种数据结构也可以说是llvm和clang中的血与肉。
llvm和clang使用到的其它数据结构还有很多,如下所示:
- BitVector
- DenseMap
- DenseSet
- ImmutableList
- ImmutableMap
- ImmutableSet
- IntervalMap
- IndexedMap
- MapVector
- PriorityQueue
- SetVector
- ScopedHashTable
- SmallBitVector
- SmallPtrSet
- SmallSet
- SmallString
- SmallVector
- SparseBitVector
- SparseSet
- StringMap
- StringRef
- StringSet
- Triple,
- TinyPtrVector
- PackedVector
- FoldingSet
- UniqueVector
- ValueMap
ImmutableMap
ImmutableMap最开始的commit message如下,Ted Kremenek借鉴了OCaml中Map的实现,OCaml中的Map就是Immutable的。
implemented on top of a functional AVL tree. The AVL balancing code
is inspired by the OCaml implementation of Map, which also uses a functional
AVL tree.
ImmutableMap这类具有immutable属性的数据结构通称为Persistent data structure,实现persistent有如下两种方式:
- Fat node
- Path copying
Fat node应该是TARJAN在文章《Planar Point Location Using Persistent Search Trees 》中首次提出来的,而path copying按照这篇文章中介绍的应该是多人同时独立想到的。fat node内存开销小,但是时间开销大,而path copying是内存开销大(非线性log(n),树高),时间开销小,关于两者的介绍,wiki给出的信息很详尽。
A more direct approach is to start with an ephemeral data structure for sorted sets or lists and make it persistent. This idea was pursued independently by Myers [27, 281, Krijnen and Meertens [al], Reps, Teitelbaum, and Demers [33], and Swart [36], who independently proposed essentially the same idea, which we shall call path copying.
The resulting data structure can be used to represent both persistent sorted sets and persistent lists with an O(log m) time bound per operation and an O(log m) space bound per update.
ImmutableMap实现persistent的方式是path copying,ImmutableMap的核心是ImutAVLTree,ImutAVLTree类似于其它的平衡二叉树,区别主要集中在前缀Imut上。
ImutAVLTree
ImutAVLTree的字面含义就是不变平衡树,例如我们要在下图(a)树中添加一个节点3,那么就会创建一个新的树,如下图种树(b)所示,这两棵树会共享大部分的节点。从而达到原平衡树没有修改,而创建的新平衡树只分配了很少的内存的目的。
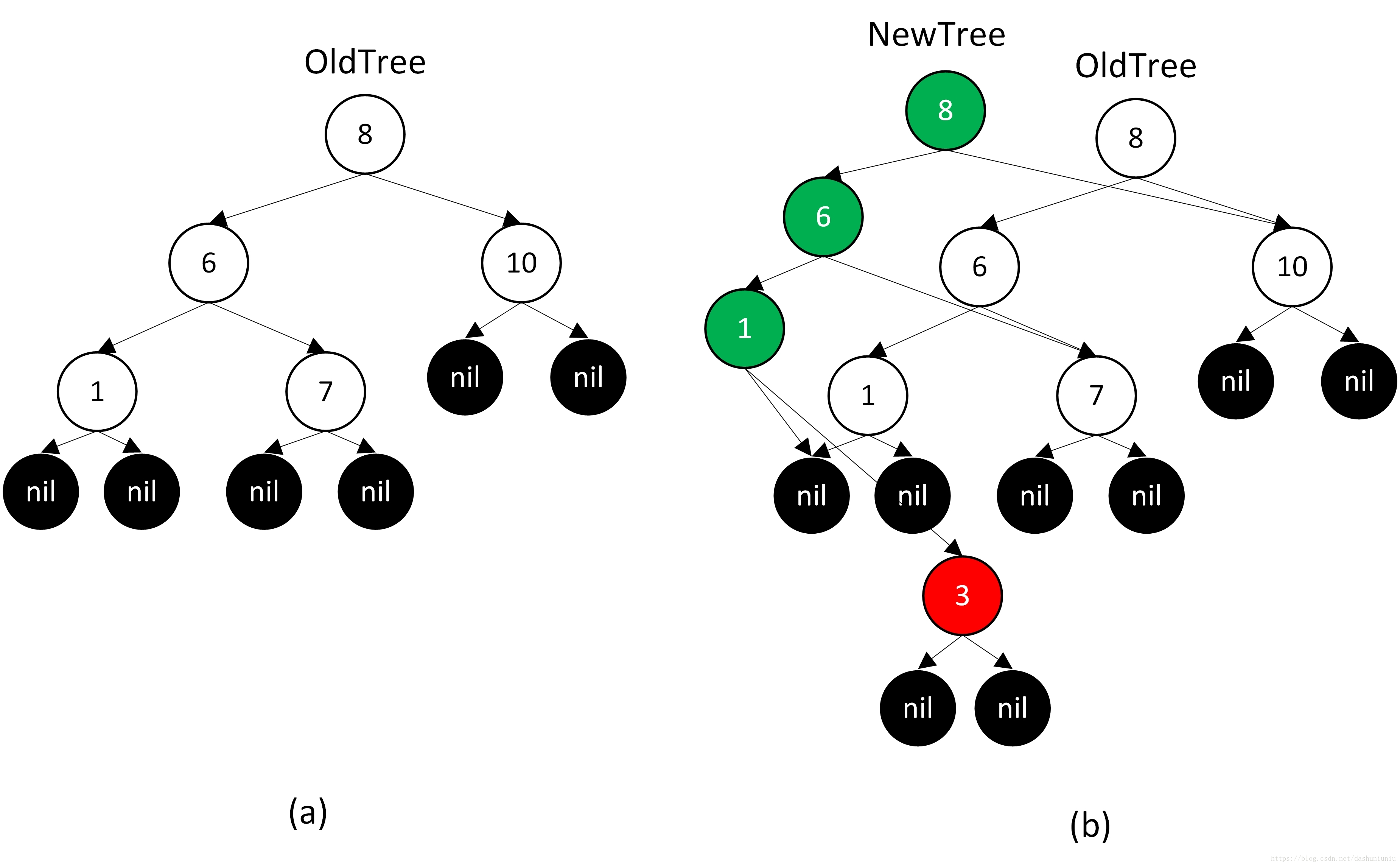
Since ProgramStates are likely to differ only slightly from each other, we use a functional data structure, ImmutableMap, that represents a mapping using a functional AVL tree. When you add a value to an ImmutableMap, you really just create a new ImmutableMap and the original stays intact. The trick is that ImmutableMaps share large amounts of their map representation (subtrees of the AVL tree) between each other, which represents a significant memory savings.
下面简单介绍下ImutAVLTree的实现。
template <typename ImutInfo>
class ImutAVLTree {
public:
//===----------------------------------------------------===//
// public Interface.
//===----------------------------------------------------===//
ImutAVLTree *getLeft() const { return left; }
ImutAVlTree *getRight() const { return right; }
unsigned getHeight() const { return height; }
const value_type& getValue() const { return value; }
/// find - Finds the subtree associated with the specified key value.
/// This method returns NULL if no matching subtree is found.
ImutAVLTree* find(key_type_ref K) {
ImutAVLTree *T = this;
while(T) {
key_type_ref CurrentKey = ImutInfo::KeyOfValue(T->getValue());
if (ImutInfo::isEual(K, CurrentKey))
return T;
else if (ImutInfo::isLess(K, CurrentKey))
T = T->getLeft();
else
T = T->getRight();
}
return nullptr;
}
ImutAVLTree* getMaxElement() {
ImutAVLTree *T = this;
ImutAVLTree *Right = T->getRight();
while(Right) { T = Right; Right = T->getRight(); }
return T;
}
/// containts - Returns true if this tree contains a subtree (node) that
/// has an data element that matches the specified key. Complexity is
/// logarithmic in the size of the tree.
bool contains(key_type_ref K) { return (bool) find(K); }
};从上面部分实现可以看出来,ImutAVLTree就是一颗很普通的二叉平衡树,使其特殊的操作在于插入和删除操作。ImutAVLTree的add(),remove()和节点管理是其核心,其余的方法都是一些很简单的API。
插入
template <typename ImutInfo>
class ImutAVLFactory {
public:
TreeTy* add(TreeTy* T, value_type_ref V) {
T = add_internal(V, T);
markImmutable(T);
recoverNodes();
return T;
}
/// add_internal - Creates a new tree that includes the specified
/// data and the data from the original tree. If the original tree
/// already containted the data item, the original tree is returned.
TreeTy* add_internal(value_type_ref V, TreeTy* T) {
if (isEmpty(T))
return createNode(T, V, T);
assert(!T->isMutable());
key_type_ref K = ImutInfo::KeyOfValue(V);
key_type_ref KCurrent = ImutInfo::KeyOfValue(getValue(T));
if (ImutInfo::isEqual(K, KCurrent))
return createNode(getLeft(T), V, getRight(T));
else if (ImutInfo::isLess(K, KCurrent))
return balanceTree(add_internal(V, getLeft(T)), getValue(T), getRight(T));
else
return balanceTree(getLeft(T), getValue(T), add_internal(V, getRight(T)));
}
/// balanceTree - Used by add_internal and remove_internal to
/// balance a newly created tree.
TreeTy* balanceTree(TreeTy* L, value_type_ref V, TreeTy* R) {
unsigned hl = getHeight(L);
unsigned hr = getHeight(R);
if (hl > hr + 2) {
TreeTy* LL = getLeft(L);
TreeTy* LR = getRight(L);
if (getHeight(LL) >= getHeight(LR))
return createNode(LL, L, createNode(LR, V, R));
TreeTy *LRL = getLeft(LR);
TreeTy *LRR = getRight(LR);
return crateNode(createNode(LL, L, LRL), LR, createNode(LRR, V, R));
}
if (hr > hl + 2) {
TreeTy *RL = getLeft(R);
TreeTy *RR = getRight(R);
if (getHeight(RR) >= getHeight(RL))
return createNode(createNode(L, V, RL), R, RR);
TreeTy *RLL = getLeft(RL);
TreeTy *RLR = getRight(RL);
return createNode(createNode(L, V, RLL), RL, createNode(RLR, R, RR));
}
return createNode(L, V, R);
}
};插入的过程也与普通的AVL Tree相似,区别在于穿插其中的createNode(),ImutAVLTree的插入并不会修改原有的树,而是会创建一个新的ImutAVLTree,为了节省内存,新旧两棵树共享大部分数据,而createNode()就是用来创建支撑新插入值的辅助节点。这些辅助节点连带新插入的值,会构成一条从树根到新插入值的路径。后面我们通过示例可以看到这些辅助节点就是在寻找插入位置时,访问过的节点的拷贝节点。
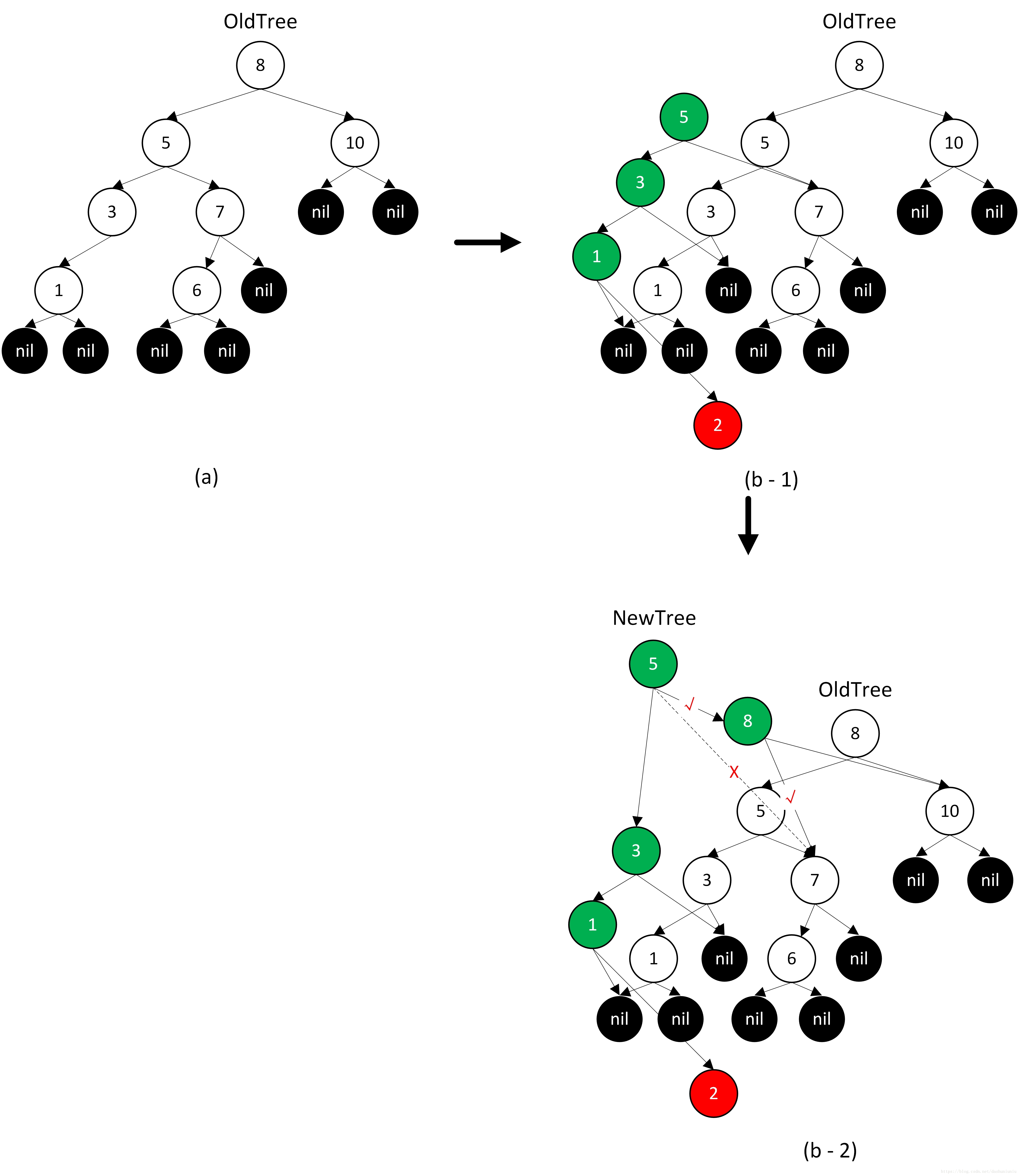
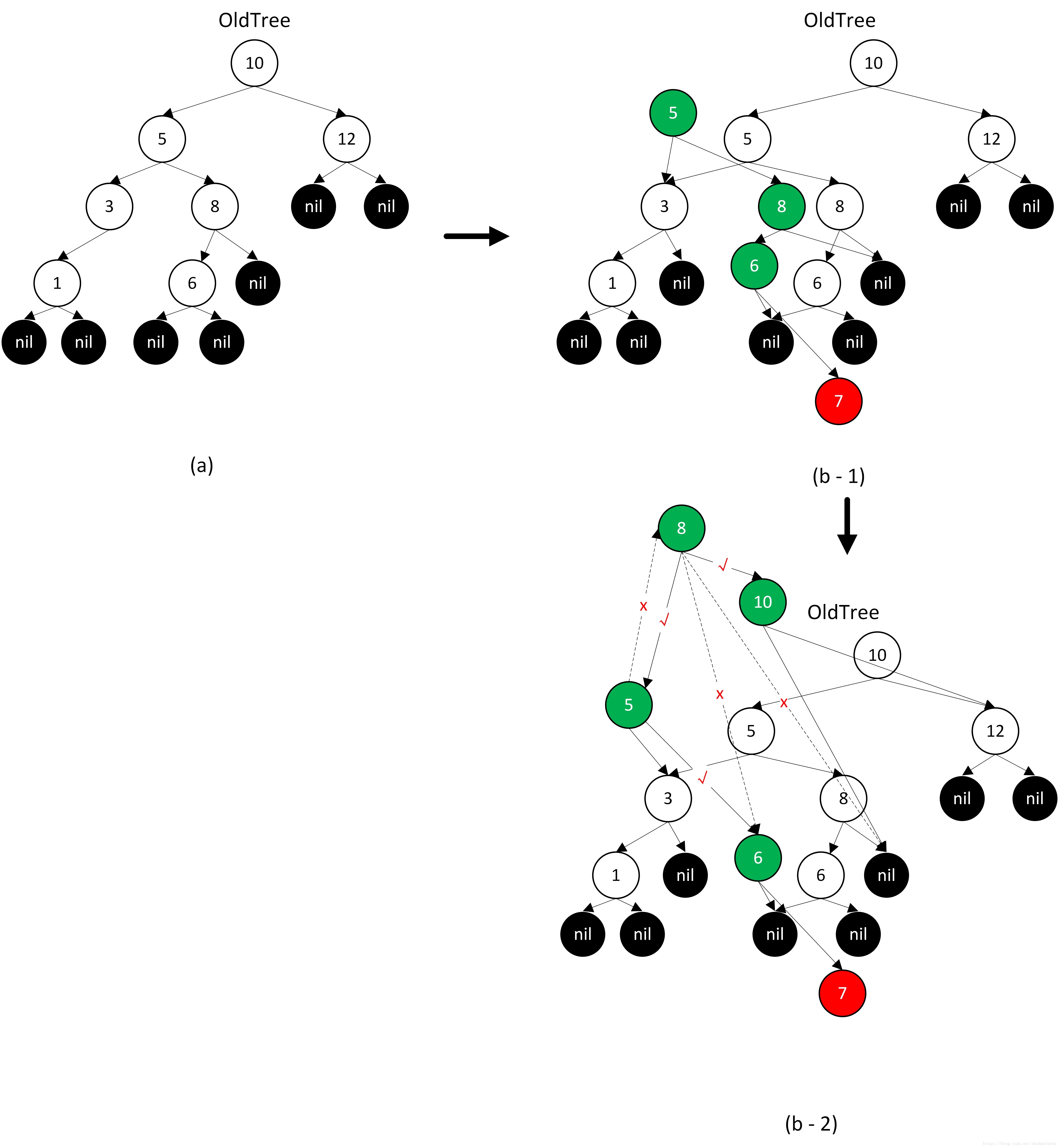
我们插入左子树的两种情况为例,说明整个插入以及维护树平衡的过程。
- 示例1,插入过程中存在左子树树高 > 右子树树高 + 2的情形,并且左左子树高 >= 左右子树
- 示例2,插入过程中存在左子树树高 > 右子树树高 + 2的情形,并且左左子树高 < 左右子树
对于示例1,例如我们要在下图树(a)中插入节点2,需要沿着左子树寻找插入过程,最终我们会发现节点2需要作为节点1的左子树,为了不影响原有的ImutAVLTree,我们需要创建新的节点用于挂载新插入的节点2,然后依次创建这些辅助节点。由于ImutAVLTree同时也是平衡树,所以需要在创建辅助节点并挂载子树的过程中,维护树的平衡。例如创建完辅助节点5以后,按理说应该创建一个新的辅助节点8(根节点),然后将节点5代表的左子树和节点10代表的右子树*挂载*在辅助节点8上。但是如果这样话的新创建的树,会失去平衡,左子树树高为4,而右子树树高为1,所以此时需要做一些调整,创建完新的辅助节点8以后,将挂载关系做一些微小的调整。
注:维持树平衡的操作,网上资料很多,这里我就不继续介绍了,其实介绍了我也记不住。
对于示例2,与示例1大同小异,只是这里在遇到树不平衡时,左左子树树高小于左右子树树高,因此使树重新平衡的操作也不同,相比于示例1会稍微复杂一些。
另外还有下面两点需要注意:
- 辅助节点的创建,辅助节点的个数最大值是旧树中的最长路径(也就是树高)
- 树不平衡的阈值,树不平衡的阈值是左右子树的树高相差大于2,也就是差值等于3时,需要调整。该阈值相较于普通的平衡树较高,较长的查询时间换来较少的调整次数。
通过这种方式,两颗树几乎会共享绝大部分的数据,几乎需要很多次插入,才有可能构成一颗全新的树。例如我们以下图(a)树为起始树,依次插入60,25,40后会得到一棵新的ImutAVLTree(b),通过(b)树我们可以发现,此时只有15节点是最旧的树的节点,其余节点都是新创建的节点。
删除
template <typename ImutInfo>
class ImutAVLFactory {
public:
/// remove_internal - Creates a new tree that includes all the data
/// from the original tree except the specified data. If the specified
/// data did not exist in the original tree, the original tree is
/// returned.
TreeTy* remove_internal(key_type_ref K, TreeTy* T) {
if (isEmpty(T))
return T;
key_type_ref KCurrent = ImutInfo::KeyOfValue(getValue(T));
if (ImutInfo::isEqual(K, KCurrent)) {
return combineTrees(getLeft(T), getRight(T));
} else if (ImutInfo::isLess(K, KCurrent)) {
return balanceTree(remove_internal(K, getLeft(T)),
getValue(T), getRigth(T));
} else {
return balanceTree(getLeft(T), getValue(T),
remove_internal(K, getRight(T)));
}
}
TreeTy* remove(TreeTy* T, key_type_ref V) {
T = remove_internal(V, T);
markImmutable(T);
recoverNodes();
return T;
}
TreeTy* combineTrees(TreeTy* L, TreeTy* R) {
if (isEmpty(L))
return R;
if (isEmpty(R))
return L;
TreeTy* OldNode;
TreeTy* newRight = removeMinBinding(R, OldNode);
return balanceTree(L, getValue(OldNode), newRight);
}
TreeTy* removeMinBinding(TreeTy* T, TreeTy*& Noderemoved) {
if (isEmpty(getLeft(T))) {
Noderemoved = T;
return getRight(T);
}
return balanceTree(removeMinBinding(getLeft(T), Noderemoved),
getValue(T), getRight(T));
}
};remove()相比于add()大概思路差不多,都是基于path copying的机制。只是由于删除一个节点,需要选择原树中的一个节点去“填充“该节点,所以remove()会有一个寻找“填充节点“的过程。“填充节点“是待删除节点右子树中的最小节点,这样填充以后,能够维持平衡树的特性。
寻找“填充节点“的方法是removeMinBinding(),该方法是一个递归方法,通过递归地访问左子树以便找到最小值节点,虽然方法名中有remove,但removeMinBinding()并不是真正的删除。如下图所示,如果我们要删除树(a)中的节点4,那么我们首先找到节点4右子树中的最小节点5,该节点就作为“填充节点“,用来填充删除节点4中的位置。在调用removeMinBinding()的过程中,会调用balanceTree()创建新的辅助节点,并调节树的平衡性,最终删除后的情况如树(b)所示。
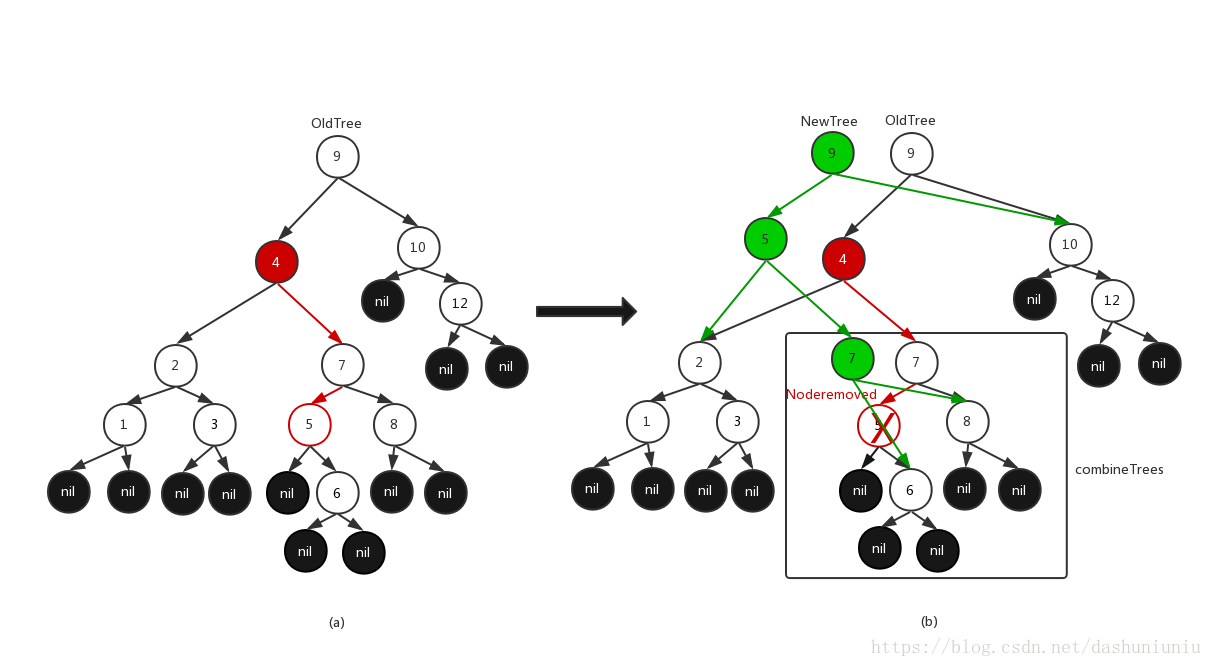
节点管理
ImutAVLTree有两个成员方法retain()和release(),以及一个数据成员refCount,这三个成员用来控制节点是否应该被回收,如果该节点的refCount为0则应该调用destroy()方法进行回收。但是通过上面的add_internal()和remove_internal()可以看出来,两者都是创建新的辅助节点,也就是节点的refCount都是增长的。而节点的refCount唯一减小的过程,就是基于ImutAVLTree的数据结构,例如ImmutableMap<>,的对象调用析构函数的时候,ImmutableMap的析构函数如下所示:
~ImmutableMap() {
if (Root) { Root->release(); }
}如果ImutAVLTree节点的refCount减小到0时,则调用destroy()方法删除该节点,删除只是将子节点的refCount减1,然后将该节点加入到freeNodes的集合中。等到调用createNode()方法时,会对这些节点进行回收再利用。另外代码中,还有部分与Canonical相关,这部分代码会在后面介绍。另外destory()会将isMutable设置为false,这样做是避免和recoverNodes()进行冲突,避免再次删除。
void retain() { ++refCount; }
void release() {
assert(refCount > 0);
if (--refCount == 0)
destroy();
}
void destroy() {
if (left)
left->release();
else (right)
right->release();
if (IsCanonicalized) {
if (next)
next->prev = prev;
if (prev)
prev->next = next;
else
factory->Cache[factory->maskCacheIndex(computeDigest())] = next;
}
// We need to clear the mutability bit in case we are
// destroying the node as part of a sweep in ImutAVLFactory::recoverNodes().
IsMutable = false;
factory->freeNodes.push_back(this);
}在前面两小节提到createNodes()方法,如下代码所示。创建新的节点有两种方式,一是从freeNodes中回收已经创建的节点,一是通过BumpPtrAllocator创建一块新的内存,基于此创建新的节点。关于BumpAllocator会在后面进行介绍。创建的节点,都会存放在createNodes中(通过vector存储),由于这些内存是通过BumpPtrAllocator创建,所以都是一次性释放。
TreeTy* createNode(TreeTy* L, value_type_ref V, TreeTy* R) {
BumpPtrAllocator& A = getAllocator();
TreeTy* T;
if (!freeNodes.empty()) {
T = freeNodes.back();
freeNodes.pop_back();
} else {
T = (TreeTy*) A.Allocate<TreeTy>();
}
new (T) TreeTy(this, L, R, V, incrementHeight(L, R));
createNodes.push_back(T);
return T;
}getCanonicalTree()
在介绍完ImutAVLTree的内部实现以后,我们回到ImmutableMap的实现,ImmutableMap的部分定义如下,其中用于存储值的ImmutableValueInfo<>核心是std::pair(),节点是类型为ImutAVLTree。相应的构造函数,析构函数以及重载的operator=()的操作都只是简单的增减root的refCount。另外一些ImmutableMap相关的API都很简单。
template <typename KeyT, typename ValT,
typename ValInfo = ImmutableValueInfo<KeyT, ValT>>
class ImmutableMap {
public:
using TreeTy = ImutAVLTree<ValInfo>;
protected:
TreeTy* Root;
public:
/// Construct a map from a pointer to a tree root. In general one
/// should use a Factory object to create maps instead of directly
/// invoking the constructor, but there are cases where make this
/// constructor public is useful.
explicit ImmutableMap(const TreeTy *R) : Root(const_cast<TreeTy*>(R)) {
if (Root) { Root->retain(); }
}
ImmutableMap(const ImmutableMap &X) : Root(X.Root) {
if (Root) { Root->retain(); }
}
~ImmutableMap() {
if (Root) { Root->release(); }
}
ImmutableMap &operator=(const ImmutableMap &X) {
if (Root != X.Root) {
if (X.Root) {X.Root->retain(); }
if (Root) { Root->release(); }
Root = X.Root;
}
return *this;
}
bool contains(key_type_ref K) const {
return Root ? Root->contains(K) : false;
}
bool operator==(const ImmutableMap &RHS) const {
return Root && RHS.Root ? Root->isEqual(*RHS.Root) : Root == RHS.Root;
}
bool operator!=(const ImmutableMap &RHS) const {
return Root && RHS.Root ? Root->isNotEqual(*RHS.Root) : Root != RHS.Root;
}
};这里介绍下ImmutableMap的getCanonicalTree()操作,canonicalize是用来删除重复ImmutableMap的,例如我们在创建新树的过程中如果发现已经存在相同的ImmutableMap了,那么就直接返回该旧Map,该机制主要是为了减少内存占用。
getCanonicalTree() gets called when we unique the maps. This uniquing is critical for de-duplication of ProgramStates, but we don’t always need to de-duplicate ProgramStates unless we think there is a strong possibility we will want to merge two paths together. That said, recall I mentioned that saving memory was also important. We also want to de-duplicate ImmutableMaps, since they are used everywhere, for memory savings. - [Analyzer] Attempting to speed up static analysis
既然需要判断两个ImmutableMap对象是否相同,那么就需要一个判断的标准,核心思想是基于ImmutableMap中所有节点计算一个哈希值,通过判断哈希值是否相同,来判断两个ImmutableMap对象是否相同。这些节点的哈希值存储在ImutAVLFactory<>中,ImutAVLFactory<>同时存储着创建的节点和用于回收的节点,Cache存储的就是ImutAVLTree的哈希值,由DenseMap<>实现,关于DenseMap<>会在后面详细介绍。
template <typename ImutInfo>
class ImutAVLFactory {
using CacheTy = DenseMap<unsigned, TreeTy*>;
CacheTy Cache;
std::vector<TreeTy*> createNodes;
std::vector<TreeTy*> freeNodes;
};哈希值的计算由computeDigest()实现,该函数的定义如下,主要是递归地哈希ImutAVLTree中所有节点的值。
static uint32_t computeDigest(ImutAVLTree *L, ImutAVLTree *R,
value_type_ref V) {
if (L)
digest += L->computeDigest();
// Compute digest of stored data.
FoldingSetNodeID ID;
ImutInfo::Profile(ID, V);
digest += ID.ComputeHash();
if (R)
digest += R->computeDigest();
return digest;
}
uint32_t computeDigest() {
// Check the lowest bit to determine if digest has actually been
// pre-computed.
if (hasCachedDigest())
return digest;
uint32_t X = computeDigest(getLeft(), getRight(), getValue());
digest = X;
markedCacheDigest();
return X;
}了解了ImutAVLTree哈希值的计算与存储,下面就要通过获取哈希值来判断两棵树是否相同了。获取与指定ImmutableMap对象具有相同哈希值的方法是getCanonicalTree(),该方法的定义如下。该方法首先计算当前ImmutableMap的哈希值,然后通过该哈希值,获取对应的bucket(<哈希值, ImutAVLTree>由DenseMap组织),
- 如果bucket的entry为空,说明没有相同的
ImmutableMap存储,那么将当前ImmutableMap对象作为该bucket的entry,并将当前对象返回 - 如果bucket的entry不为空,说明可能有相同的
ImmutableMap,那么依次比较当前bucket中的Map是否相同
注:现在只知道这些候选Map是以单链表的形式组织起来的 :( ?
比较两颗树是否相同的方法是compareTreeWithSection(),该方法本质上依次比较两棵树的值是否相同(使用iterator的中序遍历),然后返回相同的树,同时如果当前查询的树的refCount为0,那么就删除该树,这一步是减小内存占用关键的一步。如果没有找到相同的树,则将该带当前树插入链表中的合适位置(bucket中的对象是以链表组织的 : (?)。
最后将IsCanonicalized置为true,联想前面提到的destroy()方法,该方法中如果判断该树IsCanonicalized为true,说明该树在Cache中应该有存储,我们需要将该树在链表中删除,也就是相应的调整prev和next指针。
TreeTy *getCanonicalTree(TreeTy *TNew) {
if (!TNew)
return nullptr;
if (TNew->IsCanonicalized)
return TNew;
// Search the hashtable for another tree with the same digest, and
// if find a collision compare those trees by their contents.
unsigned digest = TNew->computeDigest();
TreeTy *&entry = Cache[maskCacheIndex(digest)];
do {
if (!entry)
break;
for (TreeTy *T = entry; T!= nullptr; T = T->next) {
// Compare the Contents('T') with Contents('TNew')
typename TreeTy::iterator TI = T->begin(), TE = T->end();
if (!compareTreeWithSection(TNew, TI, TE))
continue;
if (TI != TE)
continue; // T has more contents than TNew.
// Trees did match! Return 'T'.
if (TNew->refCount == 0)
TNew->destroy();
return T;
}
entry->prev = TNew;
TNew->next = entry;
} while(false);
entry = TNew;
TNew->IsCanonicalized = true;
return TNew;
}而getCanonicalTree()主要在ImmutableMap<>的add()和remove()中使用,如果增减值后创建的新的ImmutableMap<>已经有相同的存在,则返回旧的相同的树,同时如果新创建的树的refCount为0,则会在getCanonicalTree()中将新创建删除(其实也不是删除,而是将其存放在freeNodes)。
至此关于ImmutableMap<>已经介绍完了,ImmutableMap<>在clang static analyzer中很重要的一个数据结构,可以说它是专门为clang static analyzer设计的。clang static analyzer将ImmutableMap<>应用在以下几种场景中:
- ProgramState - Environment
- ProgramState - GenericDataMap
- ProgramState - RegionStore
- ProgramState - TaintRegion
- ProgramState - Constraints
- RetainCountChecker
可以说ImmutableMap<>构成了ProgramState的血与肉,后面我们在介绍clang static analyzer的内存管理和分配时,还会介绍ImmutableMap<>在clang static analyzer中所扮演的重要的角色。
———-后续———–