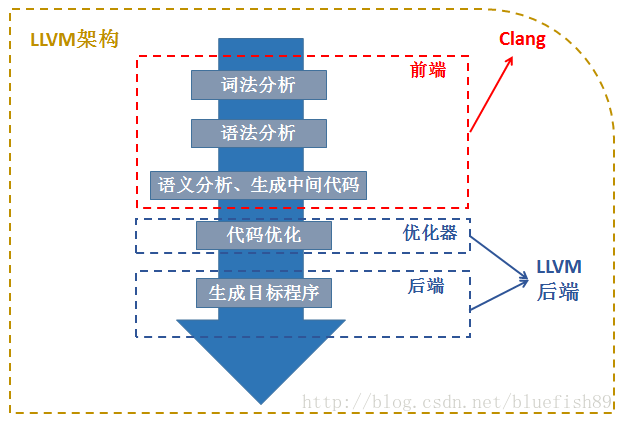
我们可以把LLVM认为是一个完整的编译器架构,或者是一个用于开发编译器、解释器的库。
理解LLVM时,我们可以分为狭义的LLVM 和 广义的LLVM
- 广义的LLVM : 指整个LLVM编译器架构,包括前端、优化器、后端、函数库
- 狭义的LLVM:后端功能(代码优化、生成)的一系列模块和库
这里我们先摆出一个操作文件main.m
#include <stdio.h>
#import <Foundation/Foundation.h>
int main() {
NSLog(@"%@", [@5 description]);
return 0;
}一、前端clang
Xcode 的默认编译器是 clang,clang 的功能是首先对 Objective-C 代码做预处理,分析检查,然后将其转换为低级的类汇编代码:LLVM Intermediate Representation(LLVM 中间表达码)。
1.预处理:
每当编源译文件的时候,编译器首先做的是一些预处理工作。比如预处理器会处理源文件中的宏定义,将代码中的宏用其对应定义的具体内容进行替换。
执行可查看宏展开:
clang -E max.m这个过程的处理包括宏的替换,头文件的导入。下面这些代码也会在这步处理。
“#define”
“#include”
“#indef”
注释
“#pragma”
2.词法语义分析:
词法分析:
预处理完成以后,每一个 .m 源文件里都有一堆的声明和定义。这些代码文本都会从 string 转化成特殊的标记流
利用 clang 命令 clang -Xclang -dump-tokens hello.m 来将上面代码的标记流导出,类似:
int 'int' [StartOfLine] Loc=<hello.m:4:1>
identifier 'main' [LeadingSpace] Loc=<hello.m:4:5>
l_paren '(' Loc=<hello.m:4:9>
r_paren ')' Loc=<hello.m:4:10>
l_brace '{' [LeadingSpace] Loc=<hello.m:4:12>
identifier 'NSLog' [StartOfLine] [LeadingSpace] Loc=<hello.m:5:3>每一个标记都包含了对应的源码内容和其在源码中的位置,注意这里的位置是宏展开之前的位置,这样一来,如果编译过程中遇到什么问题,clang 能够在源码中指出出错的具体位置。
语义分析:
词法无错误后,标记流将会被解析成一棵抽象语法树 (abstract syntax tree – AST)。
可执行clang -Xclang -ast-dump -fsyntax-only hello.m 查看,类似:
@interface World- (void) hello;
@end
@implementation World
- (void) hello (CompoundStmt 0x10372ded0 <hello.m:8:15, line:10:1>
(CallExpr 0x10372dea0 <line:9:3, col:24> 'void'
(ImplicitCastExpr 0x10372de88 <col:3> 'void (*)(NSString *, ...)' <FunctionToPointerDecay>
(DeclRefExpr 0x10372ddd8 <col:3> 'void (NSString *, ...)' Function 0x1023510d0 'NSLog' 'void (NSString *, ...)'))
(ObjCStringLiteral 0x10372de38 <col:9, col:10> 'NSString *'
(StringLiteral 0x10372de00 <col:10> 'char [13]' lvalue "hello, world"))))
@end一旦编译器把源码生成了抽象语法树,编译器可以对这棵树做分析处理,以找出代码中的错误,比如类型检查、消息发送等分析检查
3.代码生成
clang 完成代码的标记,解析和分析后,将 AST 转换为更低级的中间码 (LLVM IR)
CodeGen 会负责将语法树自顶向下遍历逐步翻译成 LLVM IR,IR 是编译过程的前端的输出后端的输入。
clang -S -fobjc-arc -emit-llvm main.m -o main.ll二、优化器
这里 LLVM 会去做些优化工作,设置优化级别-01,-03,-0s,如下,输出中间码(绝大多数情况下是二进制码格式):
clang -O3 -S -fobjc-arc -emit-llvm main.m -o main.bc接着可用另一个命令来查看刚刚生成的二进制文件:
llvm-dis < main.bc | less如果开启了 bitcode 苹果会做进一步的优化,有新的后端架构还是可以用这份优化过的 bitcode 去生成。
clang -emit-llvm -c main.m -o main.bc三、生成目标程序
汇编器将可读的汇编代码转换为机器代码。它会创建一个目标对象文件,一般简称为 对象文件。这些文件以 .o 结尾。如果用 Xcode 构建应用程序,可以在工程的 derived data 目录中,Objects-normal 文件夹下找到这些文件。
生成汇编
clang -S -fobjc-arc main.m -o main.s生成目标对象文件
clang -fmodules -c main.m -o main.o一个可执行文件包含多个段,也就是多个 section。可执行文件不同的部分将加载进不同的 section,并且每个 section 会转换进某个 segment 里。这个概念对于所有的可执行文件都是成立的。
来看看 main.o 二进制中的 section。我们可以使用 size 工具来观察:
$ size -x -l -m main.o
Segment __PAGEZERO: 0x100000000 (vmaddr 0x0 fileoff 0)
Segment __TEXT: 0x1000 (vmaddr 0x100000000 fileoff 0)
Section __text: 0x37 (addr 0x100000f30 offset 3888)
Section __stubs: 0x6 (addr 0x100000f68 offset 3944)
Section __stub_helper: 0x1a (addr 0x100000f70 offset 3952)
Section __cstring: 0xe (addr 0x100000f8a offset 3978)
Section __unwind_info: 0x48 (addr 0x100000f98 offset 3992)
Section __eh_frame: 0x18 (addr 0x100000fe0 offset 4064)
total 0xc5
Segment __DATA: 0x1000 (vmaddr 0x100001000 fileoff 4096)
Section __nl_symbol_ptr: 0x10 (addr 0x100001000 offset 4096)
Section __la_symbol_ptr: 0x8 (addr 0x100001010 offset 4112)
total 0x18
Segment __LINKEDIT: 0x1000 (vmaddr 0x100002000 fileoff 8192)
total 0x100003000如上有 4 个 segment。有些 segment 中有多个 section。
当运行一个可执行文件时,虚拟内存 (VM - virtual memory) 系统将 segment 映射到进程的地址空间上。映射完全不同于我们一般的认识,如果你对虚拟内存系统不熟悉,可以简单的想象虚拟内存系统将整个可执行文件加载进内存 – 虽然在实际上不是这样的。VM 使用了一些技巧来避免全部加载。
__TEXTsegment:包含了被执行的代码。它被以只读和可执行的方式映射。进程被允许执行这些代码,但是不能修改。这些代码也不能对自己做出修改,因此这些被映射的页从来不会被改变
__textsection:包含了编译所得到的机器码__stubs和__stub_helper:是给动态链接器 (dyld) 使用的
__DATAsegment:包含了将会被更改的数据,以可读写和不可执行的方式映射。
_nl_symbol_ptr和__la_symbol_ptr:它们分别是 non-lazy 和 lazy 符号指针,用于可执行文件中调用未定义的函数
__PAGEZEROsegment :它的大小为 4GB。这 4GB 并不是文件的真实大小,但是规定了进程地址空间的前 4GB 被映射为 不可执行、不可写和不可读。这就是为什么当读写一个 NULL 指针或更小的值时会得到一个 EXC_BAD_ACCESS
错误。这是操作系统在尝试防止引起系统崩溃
生成可执行文件,这样就能够执行看到输出结果
clang main.o -o main执行生成文件可直接运行出计算打印出结果
./main链接器
链接器解决了多个目标文件和库之间的链接。
比如现在还有有一个类文件Obj.m ,执行 clang -c Obj.m 编译出目标文件 Obj.o
为了生成一个可执行文件,我们需要将这两个目标文件和 Foundation framework 链接起来
xcrun clang main.o Obj.o -Wl,`xcrun --show-sdk-path`/System/Library/Frameworks/Foundation.framework/Foundation这里我们可输出最终可执行文件 a.out
可直接运行
$ ./a.outPS:Xcode相关
xcrun
来看一些基础性的东西:这里使用了一个名为 xcrun 的命令行工具。看起来可能会有点奇怪,不过它非常的出色。这个小工具用来调用别的一些工具。原先,我们在终端执行如下命令:
$ clang -v现在我们用下面的命令代替:
$ xcrun clang -v在这里 xcrun 做的是定位到 clang,并执行它,附带输入 clang 后面的参数。
我们为什么要这样做呢?看起来没有什么意义。不过 xcode 允许我们:
(1) 使用多个版本的 Xcode,以及使用某个特定 Xcode 版本中的工具。
(2) 针对某个特定的 SDK (software development kit) 使用不同的工具。如果你有 Xcode 4.5 和 Xcode 5,通过 xcode-select 和 xcrun 可以选择使用 Xcode 5 中 iOS SDK 的工具,或者 Xcode 4.5 中的 OS X 工具。在许多其它平台中,这是不可能做到的。查阅 xcrun 和 xcode-select 的主页内容可以了解到详细内容。不用安装 Command Line Tools,就能使用命令行中的开发者工具。
下面是Xcode完整步骤:
编译信息写入辅助文件,创建文件架构 .app 文件
处理文件打包信息
执行 CocoaPod 编译前脚本,checkPods Manifest.lock
编译.m文件,使用 CompileC 和 clang 命令
链接需要的 Framework
编译 xib
拷贝 xib ,资源文件
编译 ImageAssets
处理 info.plist
执行 CocoaPod 脚本
拷贝标准库
创建 .app 文件和签名