一、卡尔曼滤波的方程推导
直接从数学公式和概念入手来考虑卡尔曼滤波无疑是一件非常枯燥的事情。为了便于理解,我们仍然从一个现实中的实例开始下面的介绍,这一过程中你所需的预备知识仅仅是高中程度的物理学内容。
假如现在有一辆在路上做直线运动的小车(如下所示),该小车在 t 时刻的状态可以用一个向量来表示,其中pt 表示他当前的位置,vt表示该车当前的速度。当然,司机还可以踩油门或者刹车来给车一个加速度ut,ut相当于是一个对车的控制量。显然,如果司机既没有踩油门也没有踩刹车,那么ut就等于0。此时车就会做匀速直线运动。

如果我们已知上一时刻 t-1时小车的状态,现在来考虑当前时刻t 小车的状态。显然有
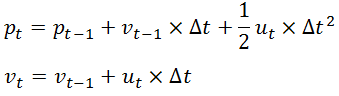
易知,上述两个公式中,输出变量都是输入变量的线性组合,这也就是称卡尔曼滤波器为线性滤波器的原因所在。既然上述公式表征了一种线性关系,那么我们就可以用一个矩阵来表示它,则有
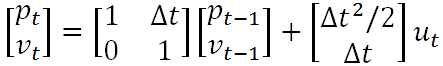
如果另其中的
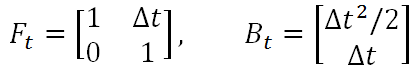
则得到卡尔曼滤波方程组中的第一条公式——状态预测公式,而F就是状态转移矩阵,它表示我们如何从上一状态来推测当前状态。而B则是控制矩阵,它表示控制量u如何作用于当前状态。
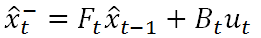
上式中x顶上的hat表示为估计值(而非真实值)。等式左端部分的右上标“-”表示该状态是根据上一状态推测而来的,稍后我们还将对其进行修正以得到最优估计,彼时才可以将“-”去掉。
既然我们是在对真实值进行估计,那么就理应考虑到噪声的影响。实践中,我们通常都是假设噪声服从一个0均值的高斯分布,即Noise~Guassian(0,σ)。例如对于一个一维的数据进行估计时,若要引入噪声的影响,其实只要考虑其中的方差σ即可。当我们将维度提高之后,为了综合考虑各个维度偏离其均值的程度,就需要引入协方差矩阵。
回到我们的例子,系统中每一个时刻的不确定性都是通过协方差矩阵 Σ 来给出的。而且这种不确定性在每个时刻间还会进行传递。也就是说不仅当前物体的状态(例如位置或者速度)是会(在每个时刻间)进行传递的,而且物体状态的不确定性也是会(在每个时刻间)进行传递的。这种不确定性的传递就可以用状态转移矩阵来表示,即(注意,这里用到了前面给出的关于协方差矩阵的性质)
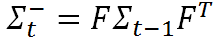
但是我们还应该考虑到,预测模型本身也并不绝对准确的,所以我们要引入一个协方差矩阵 Q 来表示预测模型本身的噪声(也即是噪声在传递过程中的不确定性),则有
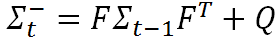
这就是卡尔曼滤波方程组中的第二条公式,它表示不确定性在各个时刻间的传递关系。
继续我们的小汽车例子。你应该注意到,前面我们所讨论的内容都是围绕小汽车的真实状态展开的。而真实状态我们其实是无法得知的,我们只能通过观测值来对真实值进行估计。所以现在我们在路上布设了一个装置来测定小汽车的位置,观测到的值记为V(t)。而且从小汽车的真实状态到其观测状态还有一个变换关系,这个变换关系我们记为h(•),而且这个h(•)还是一个线性函数。此时便有(该式前面曾经给出过)
Y(t) = h[X(t)] + V(t)
其中V(t)表示观测的误差。既然h(•)还是一个线性函数,所以我们同样可以把上式改写成矩阵的形式,则有
Yt=Hxt + v
就本例而言,观测矩阵 H = [1 0],这其实告诉我们x和Z的维度不一定非得相同。在我们的例子中,x是一个二维的列向量,而Z只是一个标量。此时当把x与上面给出的H相乘就会得出一个标量,此时得到的Y 就是x中的首个元素,也就是小车的位置。同样,我们还需要用一个协方差矩阵R来取代上述式子中的v来表示观测中的不确定性。当然,由于Z是一个一维的值,所以此时协方差矩阵R也只有一维,也就是只有一个值,即观测噪声之高斯分布的参数σ。如果我们有很多装置来测量小汽车的不同状态,那么Z就会是一个包含所有观测值的向量。
接下来要做的事情就是对前面得出的状态估计进行修正,具体而言就是利用下面这个式子
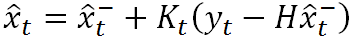
直观上来说,上式并不难理解。前面我们提到,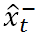

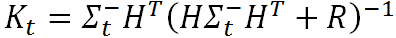
上式的推导比较复杂,有兴趣深入研究的读者可以参阅文献【2】(P35~P37)。如果有时间我会在后面再做详细推导。但是现在我们仍然可以定性地对这个系数进行解读:滤波增益阵首先权衡预测状态协方差矩阵Σ和观测值矩阵R的大小,并以此来觉得我们是更倾向于相信预测模型还是详细观测模型。如果相信预测模型多一点,那么这个残差的权重就会小一点。反之亦然,如果相信观察模型多一点,这个残差的权重就会大一点。不仅如此,滤波增益阵还负责把残差的表现形式从观测域转换到了状态域。例如本题中观测值Z 仅仅是一个一维的向量,状态 x 是一个二维的向量。所以在实际应用中,观测值与状态值所采用的描述特征或者单位都有可能不同,显然直接用观测值的残差去更新状态值是不合理的。而利用卡尔曼系数,我们就可以完成这种转换。例如,在小车运动这个例子中,我们只观察到了汽车的位置,但K里面已经包含了协方差矩阵P的信息(P里面就给出了速度和位置的相关性),所以它利用速度和位置这两个维度的相关性,从位置的残差中推算出了速度的残差。从而让我们可以对状态值 x 的两个维度同时进行修正。
最后,还需对最优估计值的噪声分布进行更新。所使用的公式为
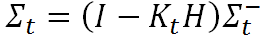
至此,我们便获得了实现卡尔曼滤波所需的全部五个公式,我在前面分别用(1)~(5)的标记进行了编号。我现在把它们再次罗列出来:

我们将这五个公式分成预测组和更新组。预测组总是根据前一个状态来估计当前状态。更新组则根据观测信息来对预测信息进行修正,以期达到最优估计之目的。