版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_15014327/article/details/83095411
Hadoop中的文件格式大致上分为面向行和面向列两类:
-
面向行:同一行的数据存储在一起,即连续存储。SequenceFile,Avro Datafile。采用这种方式,如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。
- 面向列:整个文件被切割为若干列数据,每一列数据一起存储。RCFile,ORCFile。面向列的格式使得读取数据时,可以跳过不需要的列,适合于只处于行的一小部分字段的情况。但是这种格式的读写需要更多的内存空间,因为需要缓存行在内存中(为了获取多行中的某一列)。同时不适合流式写入,因为一旦写入失败,当前文件无法恢复,而面向行的数据在写入失败时可以重新同步到最后一个同步点,所以Flume采用的是面向行的存储格式。
1.SequenceFile
根据是否压缩,以及采用记录压缩还是块压缩,存储格式有所不同:
- 不压缩:按照记录长度、Key长度、Value程度、Key值、Value值依次存储。长度是指字节数。采用指定的Serialization进行序列化。
- Record压缩:只有value被压缩,压缩的codec保存在Header中。
- Block压缩:多条记录被压缩在一起,可以利用记录之间的相似性,更节省空间。Block前后都加入了同步标识。Block的最小值由io.seqfile.compress.blocksize属性设置。
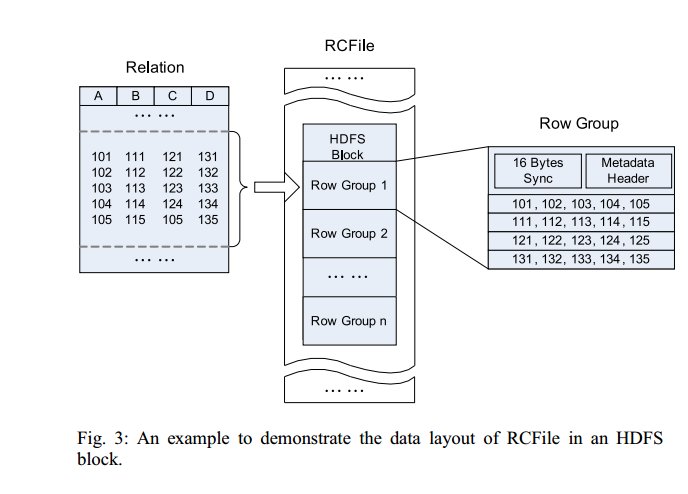
2.RCFile
Hive的Record Columnar File,这种类型的文件先将数据按行划分成Row Group,在Row Group内部,再将数据按列划分存储。ORCFile是一种比RCFile更加高效的文件格式。RCFile结构如下:
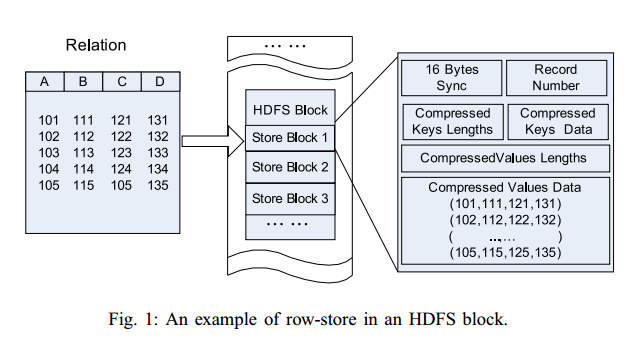
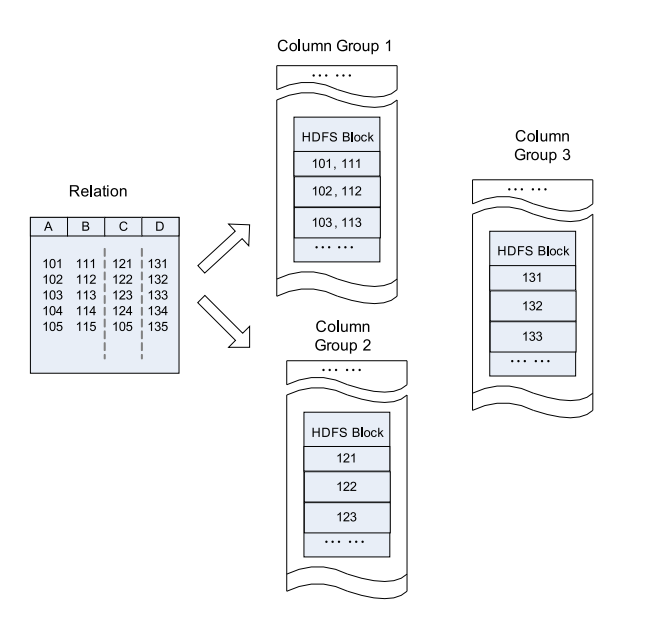
单纯的面向行和列分别是这样的:
3.文件格式总结
| 面向行/列 |
类型名称 |
是否可切分 |
优点 |
缺点 |
| 面向行 |
文本文件格式(.txt) |
是 |
查看便编辑简单 |
无压缩占空间大、传输压力大、数据解析开销大 |
| 面向行 |
sequenceFile序列文件格式(.seq) |
是 |
原生支持、二进制kv存储、支持行和块压缩 |
本地查看不方便:小文件合并成kv结构后不易查看内部数据 |
| 面向列 |
rcfile文件格式(.rc) |
是 |
数据加载快、查询快、空间利用率高、高负载能力 |
每一项都不是最高 |
| 面向列 |
orcfile文件格式(.orc) |
是 |
兼具了rcfile优点,进一步提高了读取、存储效率、新数据类型的支持 |
每一项都不是最高 |
4.压缩格式总结
1) Gzip压缩
- 优点:压缩率比较高,压缩/解压速度也比较快,hadoop本身支持。
- 缺点:不支持分片。
- 应用场景:当每个文件压缩之后在1个block块大小内,可以考虑用gzip压缩格式。
2) lzo压缩
- 优点:压缩/解压速度也比较快,合理的压缩率,支持分片,是Hadoop中最流行的压缩格式,支持Hadoop native库。
- 缺点:压缩率比gzip要低一些,Hadoop本身不支持,需要安装,如果支持分片需要建立索引,还需要指定inputformat改为lzo格式。
- 应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越明显。
3) snappy压缩
- 优点:支持Hadoop native库,高速压缩速度和合理的压缩率。
- 缺点:不支持分片,压缩率比gzip要低,Hadoop本身不支持,需要安装。
- 应用场景:当MapReduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式。
4) bzip2压缩
- 优点:支持分片,具有很高的压缩率,比gzip压缩率都高,Hadoop本身支持,但不支持native。
- 缺点:压缩/解压速度慢,不支持Hadoop native库。
- 应用场景:适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式,输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况。