本次的内容为python的应用,关于文件、字典、统计应用,均多应用列表、字典。
习题一
读入文件pmi_days.csv,完成以下操作:
1.统计质量等级对应的天数,例如:
优:5天
良:3天
中度污染:2天
2.找出PMI2.5的最大值和最小值,分别指出是哪一天。
以下是代码内容:
import csv
z1 = 0
z2 = 0
z3 = 0
z4 = 0
listp = []
listd = []
d1 = 0
with open("pmi_days .csv", 'r') as f:
reader = csv.reader(f)
fieldnames = next(reader) # 获取数据的第一列,作为后续要转为字典的键名 生成器,next方法获取
# print(fieldnames)
csv_reader = csv.DictReader(f,fieldnames=fieldnames) # self._fieldnames = fieldnames # list of keys for the dict 以list的形式存放键名
for row in csv_reader:
dict = {}
for key, value in row.items():
dict[key] = value
if value == '优':
z1 = z1 + 1
if value == '良':
z2 = z2 + 1
if value == '轻度污染':
z3 = z3 + 1
if value == '中度污染':
z4 = z4 + 1
if key == 'PM2.5':
listp.append(int(dict.get("PM2.5")))
listd.append(dict.get("日期"))
for j in range(0, len(listp)):
if listp[j] == max(listp):
d1 = listd[j]
if listp[j] == min(listp):
x1 = listd[j]
print("优:{}天".format(z1))
print("良:{}天".format(z2))
print("轻度污染:{}天".format(z3))
print("中度污染:{}天".format(z4))
print("PM2.5最高:{} PM2.5的值:{}".format(d1,max(listp)))
print("PM2.5最低:{} PM2.5的值:{}".format(x1,min(listp)))
以下是运行结果:

本题更多的是格式上的规划,通过循环,判断控制输入与格式达到,筛选出想要的内容、输出结果,并呈现出想要的格式。
题目不难,更多的是逻辑上要清晰,考虑好条件筛选的内容。
习题二
读入文件1980-2018GDP.csv,完成以下操作:
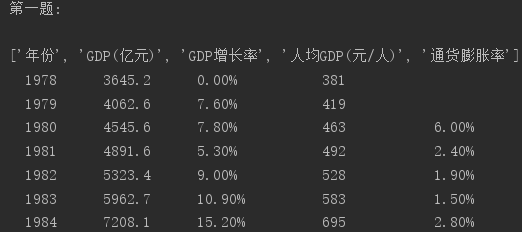
1.按行输出每年GDP数据,表头列名如文件第1行所示。
2.将各年GDP数据转换成字典格式,以年份为keys,其它值为values(数据类型为列表方式),例如:
{
2017:[827121.7,6.8%,60989]
........
}
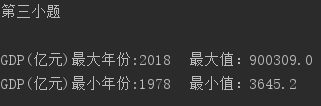
3.遍历字典数据,求出GDP的最小值与最大值,并输出数据与对应的年份。
以下是代码内容:
1
import csv
list=[]
comp_g=[]
comp_y=[]
dict_1={}
with open("1980-2018GDP.csv", 'r') as f:
reader = csv.reader(f)
fieldnames = next(reader)
print("第一题:\n")
print(fieldnames)
for row in reader:
list.append(row)
for i in range(0,len(list)):
print("%6s"%list[i][0],"\t\t%-10s"%list[i][1],"\t%-12s"%list[i][2],"\t%-13s"%list[i][3],list[i][4])
with open("1980-2018GDP.csv", 'r') as f:
reader = csv.reader(f)
fieldnames = next(reader)
csv_reader = csv.DictReader(f, fieldnames=fieldnames)
for row in csv_reader:
dict = {}
for key, value in row.items():
dict[key] = value
if key == 'GDP(亿元)':
comp_g.append(float(dict.get('GDP(亿元)')))
comp_y.append(int(dict.get('年份')))
#如果属性名为'GDP(亿元)'则把对应年份、GDP值放入列表
#供应给最大最小比较之用。
for i in range(0, len(list)):
dict_1[comp_y[i]] = list[i][1:]
#第二题
#将年份作为字典dict_1的键
#将年份对应内容组成的列表设置成值
#即可做到规范输出格式
for j in range(0, len(comp_g)):
if comp_g[j] == max(comp_g):
ma = comp_y[j]
if comp_g[j] == min(comp_g):
mi = comp_y[j]
print("第二题:\n")
print("各年GDP数据字典格式:")
print(dict_1)#输出题目要求的格式
print("第三题:\n")
print("GDP(亿元)最大年份:{}\t最大值:{}".format(ma,max(comp_g)))# 求出GDP的最小值与最大值
print("GDP(亿元)最小年份:{}\t最小值:{}".format(mi,min(comp_g)))# 并输出数据与对应的年份。
以下是运行结果:

本题更多的是在对代码原理的理解后对,数据统计整理的使用。
根据源代码,进行修改,通过增加限制条件,
通过if等判断条件统计中的词汇,来搜索出你想要的对应信息的数据。
第一小题
通过循环,以及形成列表
最终控制输出
第二小题
将年份作为字典dict_1的键
将年份对应内容组成的列表设置成值
即可做到规范输出格式
第三小题
通过与上一题一样的,增加if条件
做到让值的大小比较做索引
来输出年份
本次习题结束。
所以说很多时候不是你不会,只是缺少更多的思考,更多的细心罢了..