
编译:狗小白、李佳、张弛、魏子敏
没人否认,维基百科是现代最令人惊叹的人类发明之一。
几年前谁能想到,匿名贡献者们的义务工作竟创造出前所未有的巨大在线知识库?维基百科不仅是你写大学论文时最好的信息渠道,也是一个极其丰富的数据源。
从自然语言处理到监督式机器学习,维基百科助力了无数的数据科学项目。
维基百科的规模之大,可称为世上最大的百科全书,但也因此稍让数据工程师们感到头疼。当然,有合适的工具的话,数据量的规模就不是那么大的问题了。
本文将介绍“如何编程下载和解析英文版维基百科”。
在介绍过程中,我们也会提及以下几个数据科学中重要的问题:
1、从网络中搜索和编程下载数据
2、运用Python库解析网络数据(HTML, XML, MediaWiki格式)
3、多进程处理、并行化处理

这个项目最初是想要收集维基百科上所有的书籍信息,但我之后发现项目中使用的解决方法可以有更广泛的应用。这里提到的,以及在Jupyter Notebook里展示的技术,能够高效处理维基百科上的所有文章,同时还能扩展到其它的网络数据源中。
本文中运用的Python代码的笔记放在GitHub,灵感来源于Douwe Osinga超棒的《深度学习手册》。前面提到的Jupyter Notebooks也可以免费获取。
GitHub链接:
https://github.com/WillKoehrsen/wikipedia-data-science/blob/master/notebooks/Downloading%20and%20Parsing%20Wikipedia%20Articles.ipynb
免费获取地址:
https://github.com/DOsinga/deep_learning_cookbook
编程搜索和下载数据
任何一个数据科学项目第一步都是获取数据。我们当然可以一个个进入维基百科页面打包下载搜索结果,但很快就会下载受限,而且还会给维基百科的服务器造成压力。还有一种办法,我们通过dumps.wikimedia.org这个网站获取维基百科所有数据的定期快照结果,又称dump。
用下面这段代码,我们可以看到数据库的可用版本:
import requests# Library for parsing HTMLfrom bs4 import BeautifulSoupbase_url = 'https://dumps.wikimedia.org/enwiki/'index = requests.get(base_url).textsoup_index = BeautifulSoup(index, 'html.parser')# Find the links on the pagedumps = [a['href'] for a in soup_index.find_all('a') if a.has_attr('href')]dumps['../', '20180620/', '20180701/', '20180720/', '20180801/', '20180820/', '20180901/', '20180920/', 'latest/']
这段代码使用了BeautifulSoup库来解析HTML。由于HTML是网页的标准标识语言,因此就处理网络数据来说,这个库简直是无价瑰宝。
本项目使用的是2018年9月1日的dump(有些dump数据不全,请确保选择一个你所需的数据)。我们使用下列代码来找到dump里所有的文件。
dump_url = base_url + '20180901/'# Retrieve the htmldump_html = requests.get(dump_url).text# Convert to a soupsoup_dump = BeautifulSoup(dump_html, 'html.parser')# Find list elements with the class filesoup_dump.find_all('li', {'class': 'file'})[:3][
- enwiki-20180901-pages-articles-multistream.xml.bz2 15.2 GB
- ,
- enwiki-20180901-pages-articles-multistream-index.txt.bz2 195.6 MB
- ,
- enwiki-20180901-pages-meta-history1.xml-p10p2101.7z 320.6 MB
- ]
我们再一次使用BeautifulSoup来解析网络找寻文件。我们可以在https://dumps.wikimedia.org/enwiki/20180901/页面里手工下载文件,但这就不够效率了。网络数据如此庞杂,懂得如何解析HTML和在程序中与网页交互是非常有用的——学点网站检索知识,庞大的新数据源便触手可及。
考虑好下载什么
上述代码把dump里的所有文件都找出来了,你也就有了一些下载的选择:文章当前版本,文章页以及当前讨论列表,或者是文章所有历史修改版本和讨论列表。如果你选择最后一个,那就是万亿字节的数据量了!本项目只选用文章最新版本。
所有文章的当前版本能以单个文档的形式获得,但如果我们下载解析这个文档,就得非常费劲地一篇篇文章翻看,非常低效。更好的办法是,下载多个分区文档,每个文档内容是文章的一个章节。之后,我们可以通过并行化一次解析多个文档,显著提高效率。
“当我处理文档时,我更喜欢多个小文档而非一个大文档,这样我就可以并行化运行多个文档了。”
分区文档格式为bz2压缩的XML(可扩展标识语言),每个分区大小300~400MB,全部的压缩包大小15.4GB。无需解压,但如果你想解压,大小约58GB。这个大小对于人类的全部知识来说似乎并不太大。
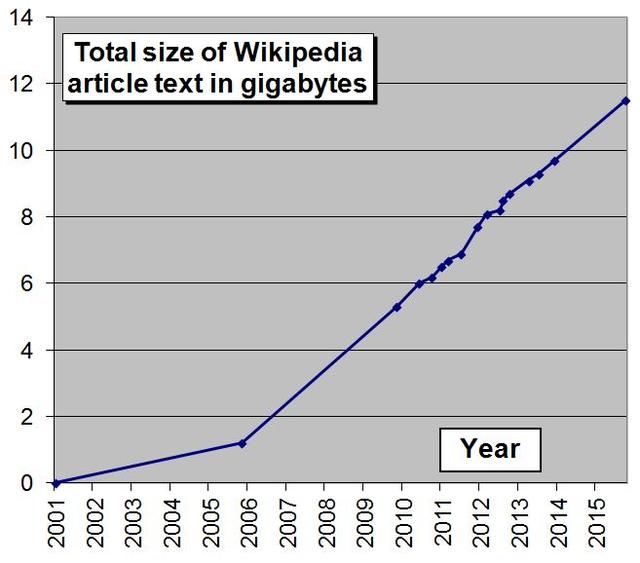
维基百科压缩文件大小
下载文件
Keras 中的get_file语句在实际下载文件中非常好用。下面的代码可通过链接下载文件并保存到磁盘中:
from keras.utils import get_filesaved_file_path = get_file(file, url)
下载的文件保存在~/.keras/datasets/,也是Keras默认保存设置。一次性下载全部文件需2个多小时(你可以试试并行下载,但我试图同时进行多个下载任务时被限速了)
解析数据
我们首先得解压文件。但实际我们发现,想获取全部文章数据根本不需要这样。我们可以通过一次解压运行一行内容来迭代文档。当内存不够运行大容量数据时,在文件间迭代通常是唯一选择。我们可以使用bz2库对bz2压缩的文件迭代。
不过在测试过程中,我发现了一个更快捷(双倍快捷)的方法,用的是system utility bzcat以及Python模块的subprocess。以上揭示了一个重要的观点:解决问题往往有很多种办法,而找到最有效办法的唯一方式就是对我们的方案进行基准测试。这可以很简单地通过%%timeit Jupyter cell magic来对方案计时评价。
迭代解压文件的基本格式为:
data_path = '~/.keras/datasets/enwiki-20180901-pages-articles15.xml-p7744803p9244803.bz2# Iterate through compressed file one line at a timefor line in subprocess.Popen(['bzcat'], stdin = open(data_path), stdout = subprocess.PIPE).stdout: # process line
如果简单地读取XML数据,并附为一个列表,我们得到看起来像这样的东西:

维基百科文章的源XML
上面展示了一篇维基百科文章的XML文件。每个文件里面有成千上万篇文章,因此我们下载的文件里包含百万行这样的语句。如果我们真想把事情弄复杂,我们可以用正则表达式和字符串匹配跑一遍文档来找到每篇文章。这就极其低效了,我们可以采取一个更好的办法:使用解析XML和维基百科式文章的定制化工具。
解析方法
我们需要在两个层面上来解析文档:
1、从XML中提取文章标题和内容
2、从文章内容中提取相关信息
好在,Python对这两个都有不错的应对方法。
解析XML
解决第一个问题——定位文章,我们使用SAX(Simple API for XML) 语法解析器。BeautifulSoup语句也可以用来解析XML,但需要内存载入整个文档并且建立一个文档对象模型(DOM)。而SAX一次只运行XML里的一行字,完美符合我们的应用场景。