版权声明:本文为博主原创文章,未经博主允许不得转载。作为分享主义者(sharism),本人所有互联网发布的图文均采用知识共享署名 4.0 国际许可协议(https://creativecommons.org/licenses/by/4.0/)进行许可。转载请保留作者信息并注明作者Jie Qiao专栏:http://blog.csdn.net/a358463121。商业使用请联系作者。 https://blog.csdn.net/a358463121/article/details/82903957
在机器学习中,我们常常需要用一个分布Q去逼近一个目标分布P,我们希望能够找到一个目标函数
D
(
Q
,
P
)
D( Q,P)
D ( Q , P ) 没有 距离的对称性(
d
(
x
,
y
)
=
d
(
y
,
x
)
d(x,y)=d(y,x)
d ( x , y ) = d ( y , x )
d
(
x
,
y
)
≤
d
(
x
,
z
)
+
d
(
z
,
y
)
d(x,y) \leq d(x,z)+d(z,y)
d ( x , y ) ≤ d ( x , z ) + d ( z , y )
在机器学习中,最常见的散度就是KL散度了(它还有很多名字,比如:relative entropy, relative information。),那么KL散度究竟是何方神圣?它的著名到底是历史的原因还是因为它本身优良的性质呢?
用一句话来说,KL散度可以理解为,用来衡量在同一份数据P下,使用P的编码方案和Q的编码方案的平均编码长度的差异 。
为了理解这个问题,我们先从熵讲起。一个随机变量X的概率密度函数为
p
(
x
)
p( x)
p ( x )
H
(
X
)
=
−
∑
x
p
(
x
)
log
2
p
(
x
)
H( X) =-\sum _{x} p( x)\log_{2} p( x)
H ( X ) = − x ∑ p ( x ) log 2 p ( x ) 平均 比特数。
例子 :考虑一个服从均匀分布且有32种可能结果的随机变量。为了确定一个结果,我们需要5个比特的编码来告诉我们到底出现了哪种可能。该随机变量的熵恰好为:
H
(
X
)
=
−
∑
i
=
1
32
1
32
log
2
1
32
=
5
比
特
H( X) =-\sum ^{32}_{i=1}\frac{1}{32}\log_{2}\frac{1}{32} =5\ 比特
H ( X ) = − i = 1 ∑ 3 2 3 2 1 log 2 3 2 1 = 5 比 特
例子: 有8匹马参加赛马比赛。8匹马的胜率分布为:
P
=
{
1
2
,
1
4
,
1
8
,
1
16
,
1
64
,
1
64
,
1
64
,
1
64
}
P=\left\{\frac{1}{2} ,\frac{1}{4} ,\frac{1}{8} ,\frac{1}{16} ,\frac{1}{64} ,\frac{1}{64} ,\frac{1}{64} ,\frac{1}{64}\right\}
P = { 2 1 , 4 1 , 8 1 , 1 6 1 , 6 4 1 , 6 4 1 , 6 4 1 , 6 4 1 }
H
(
X
)
=
−
1
2
log
2
1
2
−
1
4
log
2
1
4
−
1
8
log
2
1
8
−
1
16
log
2
1
16
−
4
∗
1
64
log
2
1
64
=
2
比
特
H( X) =-\frac{1}{2}\log_{2}\frac{1}{2} -\frac{1}{4}\log_{2}\frac{1}{4} -\frac{1}{8}\log_{2}\frac{1}{8} -\frac{1}{16}\log_{2}\frac{1}{16} -4*\frac{1}{64}\log_{2}\frac{1}{64} =2\ 比特
H ( X ) = − 2 1 log 2 2 1 − 4 1 log 2 4 1 − 8 1 log 2 8 1 − 1 6 1 log 2 1 6 1 − 4 ∗ 6 4 1 log 2 6 4 1 = 2 比 特
此时,假定我们要把哪匹马会获胜的消息发送出去, 其中一个策略是发送胜出马的编号。 这样, 对任何一匹马, 描述需要3比特。 但由于获胜的概率不是均等的, 因此, 明智的方法是对获胜可能性较大的马使用较短的描述, 而对获胜可能性较小的马使用较长的描述。 这样做, 我们会获得一个更短的平均描述长度。 例如,使用以下的一组二元字符串来表示8匹马:0, 10, 110, 1110, 111100, 111101, 111110,111111。 此时, 平均描述长度为2比特, 比使用等长编码时所用的3比特小。可以证明任何随机变量的熵必为表示这个随机变量所需要的平均比特数的一个下界。注意到这里的
−
log
2
1
2
=
1
,
−
log
2
1
4
=
2...
−
log
2
1
64
=
6
-\log_{2}\frac{1}{2} =1,-\log_{2}\frac{1}{4} =2...-\log_{2}\frac{1}{64} =6
− log 2 2 1 = 1 , − log 2 4 1 = 2 . . . − log 2 6 4 1 = 6
log
2
p
(
x
)
\log_{2} p( x)
log 2 p ( x ) 编码长度 。
那么如果,我们换一套编码方案去表示这场比赛会怎样 ?假设另外一场赛马比赛的胜率分布为均匀分布:
Q
=
{
1
8
,
1
8
,
1
8
,
1
8
,
1
8
,
1
8
,
1
8
,
1
8
}
Q=\left\{\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8} ,\frac{1}{8}\right\}
Q = { 8 1 , 8 1 , 8 1 , 8 1 , 8 1 , 8 1 , 8 1 , 8 1 }
(
1
2
+
1
4
+
1
8
+
1
16
+
1
64
+
1
64
+
1
64
+
1
64
)
∗
3
=
3
\left(\frac{1}{2} +\frac{1}{4} +\frac{1}{8} +\frac{1}{16} +\frac{1}{64} +\frac{1}{64} +\frac{1}{64} +\frac{1}{64}\right) *3=3
( 2 1 + 4 1 + 8 1 + 1 6 1 + 6 4 1 + 6 4 1 + 6 4 1 + 6 4 1 ) ∗ 3 = 3
K
L
(
P
∥
Q
)
=
1
KL( P\| Q) =1
K L ( P ∥ Q ) = 1
K
L
(
P
∥
Q
)
=
∑
x
P
(
x
)
log
2
P
(
x
)
Q
(
x
)
=
1
KL( P\| Q) =\sum _{x} P( x)\log_{2}\frac{P( x)}{Q( x)} =1
K L ( P ∥ Q ) = x ∑ P ( x ) log 2 Q ( x ) P ( x ) = 1
此外,KL散度还可以写作:
K
L
(
P
∥
Q
)
=
∑
x
P
(
x
)
log
2
P
(
x
)
−
∑
x
P
(
x
)
log
2
Q
(
x
)
KL( P\| Q) =\sum _{x} P( x)\log_{2} P( x) -\sum _{x} P( x)\log_{2} Q( x)
K L ( P ∥ Q ) = ∑ x P ( x ) log 2 P ( x ) − ∑ x P ( x ) log 2 Q ( x )
下面介绍3个公理,注意,只有KL距离能够满足下面所有的公理。
Locality. 该性质可以认为该距离是一个关于“点”的距离,通过比较每个点的距离从而得到整个分布的距离,即,相对信息可以写成:
D
(
Q
,
P
)
=
∫
f
(
q
(
x
)
,
p
(
x
)
,
x
)
d
x
D( Q,P) =\int f( q( x) ,p( x) ,x) dx
D ( Q , P ) = ∫ f ( q ( x ) , p ( x ) , x ) d x
q
(
x
)
,
p
(
x
′
)
q( x) ,p( x')
q ( x ) , p ( x ′ )
x
=
x
′
x=x'
x = x ′
D
(
Q
,
P
)
=
∫
f
(
q
(
x
)
,
p
(
x
)
,
x
,
∇
q
(
x
)
,
∇
p
(
x
)
)
d
x
D( Q,P) =\int f( q( x) ,p( x) ,x,\nabla q( x) ,\nabla p( x)) dx
D ( Q , P ) = ∫ f ( q ( x ) , p ( x ) , x , ∇ q ( x ) , ∇ p ( x ) ) d x
Coordinate invariance坐标不变性,不管坐标系怎么办,两个分布的散度都应该是不变的,形式化的说,如果x存在一个变换
ϕ
\phi
ϕ
x
~
=
ϕ
(
x
)
\tilde{x} =\phi ( x)
x ~ = ϕ ( x )
D
(
Q
~
,
P
~
)
=
∫
f
(
q
~
(
x
~
)
,
p
(
x
~
)
,
x
~
)
d
x
~
=
∫
f
(
(
q
∘
ϕ
−
1
)
(
x
~
)
∣
det
∂
ϕ
∂
x
∣
,
(
q
∘
ϕ
−
1
)
(
x
~
)
∣
det
∂
ϕ
∂
x
∣
,
ϕ
−
1
(
x
~
)
)
d
x
~
=
D
(
Q
,
P
)
D\left(\tilde{Q} ,\tilde{P}\right) =\int f\left(\tilde{q}\left(\tilde{x}\right) ,p\left(\tilde{x}\right) ,\tilde{x}\right) d\tilde{x} =\int f\left(\frac{\left( q\circ \phi ^{-1}\right)\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} ,\frac{\left( q\circ \phi ^{-1}\right)\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} ,\phi ^{-1}\left(\tilde{x}\right)\right) d\tilde{x} =D( Q,P)
D ( Q ~ , P ~ ) = ∫ f ( q ~ ( x ~ ) , p ( x ~ ) , x ~ ) d x ~ = ∫ f ( ∣ det ∂ x ∂ ϕ ∣ ( q ∘ ϕ − 1 ) ( x ~ ) , ∣ det ∂ x ∂ ϕ ∣ ( q ∘ ϕ − 1 ) ( x ~ ) , ϕ − 1 ( x ~ ) ) d x ~ = D ( Q , P )
Subsystem independence,如果存在子系统相互独立,那么考虑
p
(
x
1
,
x
2
)
p( x_{1} ,x_{2})
p ( x 1 , x 2 )
p
(
x
1
)
p
(
x
2
)
p( x_{1}) p( x_{2})
p ( x 1 ) p ( x 2 )
实际上,如果不需要满足或部分满足上面的公理,我们就能得到各种各样不同的divergence。但是,违反公理2会导致梯度的计算有偏,违反公理3会导致计算开销很大。这也从侧面反应出,KL距离是表示相对信息最合理的一个。
f-divergences,
D
f
(
Q
,
P
)
=
∫
f
(
q
(
x
)
p
(
x
)
)
p
(
x
)
d
x
D_{f}( Q,P) =\int f\left(\frac{q( x)}{p( x)}\right) p( x) dx
D f ( Q , P ) = ∫ f ( p ( x ) q ( x ) ) p ( x ) d x
f
≠
x
log
x
f\neq x\log x
f ̸ = x log x
Stein divergence,
D
(
Q
,
P
)
=
sup
f
∈
F
E
q
[
∇
log
p
(
x
)
f
(
x
)
+
∇
f
(
x
)
]
2
D( Q,P) =\sup _{f\in \mathcal{F}} E_{q}[ \nabla \log p( x) f( x) +\nabla f( x)]^{2}
D ( Q , P ) = sup f ∈ F E q [ ∇ log p ( x ) f ( x ) + ∇ f ( x ) ] 2
E
p
[
∇
log
p
(
x
)
f
(
x
)
+
∇
f
(
x
)
]
=
0
E_{p}[ \nabla \log p( x) f( x) +\nabla f( x)] =0
E p [ ∇ log p ( x ) f ( x ) + ∇ f ( x ) ] = 0
Craner/energy distance
D
(
Q
,
P
)
=
2
E
[
∥
x
−
y
∥
]
−
E
[
∥
x
−
x
′
∥
]
−
E
[
∥
y
−
y
′
∥
]
D( Q,P) =2E[ \| x-y\| ] -E[ \| x-x'\| ] -E[ \| y-y'\| ]
D ( Q , P ) = 2 E [ ∥ x − y ∥ ] − E [ ∥ x − x ′ ∥ ] − E [ ∥ y − y ′ ∥ ]
x
,
x
′
∼
P
x,x'\sim P
x , x ′ ∼ P
y
,
y
′
∼
Q
y,y'\sim Q
y , y ′ ∼ Q
Wasserteub dustabce
D
p
(
Q
,
P
)
=
[
inf
ρ
∫
d
x
d
x
′
∥
x
−
x
′
∥
p
ρ
(
x
,
x
′
)
]
1
p
D_{p}( Q,P) =\left[\inf_{\rho }\int dxdx'\| x-x'\| ^{p} \rho ( x,x')\right]^{\frac{1}{p}}
D p ( Q , P ) = [ inf ρ ∫ d x d x ′ ∥ x − x ′ ∥ p ρ ( x , x ′ ) ] p 1
ρ
:
R
d
×
R
d
→
R
+
\rho :\mathbb{R}^{d} \times \mathbb{R}^{d}\rightarrow \mathbb{R}^{+}
ρ : R d × R d → R +
ρ
(
x
)
=
q
(
x
)
,
ρ
(
x
′
)
=
p
(
x
)
\rho( x) =q( x) ,\rho ( x') =p( x)
ρ ( x ) = q ( x ) , ρ ( x ′ ) = p ( x )
ρ
\rho
ρ
∣
∣
∣
∣
||\ ||
∣ ∣ ∣ ∣
Fisher distance
D
(
Q
,
P
)
=
E
p
[
∥
∇
x
ln
p
(
x
)
−
∇
x
ln
q
(
x
)
∥
2
]
D( Q,P) =E_{p}\left[ \| \nabla _{x}\ln p( x) -\nabla _{x}\ln q( x) \| ^{2}\right]
D ( Q , P ) = E p [ ∥ ∇ x ln p ( x ) − ∇ x ln q ( x ) ∥ 2 ]
Max-min distance (MMD)
D
(
Q
,
P
)
=
sup
f
(
E
[
f
]
Q
−
E
[
f
]
P
)
D( Q,P) =\sup _{f}( E[ f]_{Q} -E[ f]_{P})
D ( Q , P ) = sup f ( E [ f ] Q − E [ f ] P )
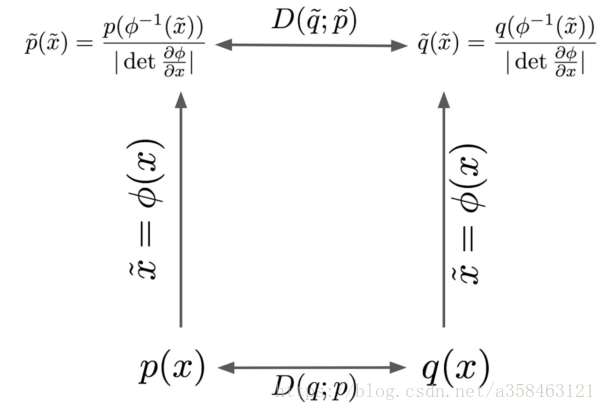
当数据的坐标系发生变换后,两个分布的散度还是一样的吗?如果不能他会变成怎样?这一节就是为了探索这个问题。
在上图x是没有变换的坐标系,而
x
~
=
ϕ
(
x
)
\tilde{x} =\phi ( x)
x ~ = ϕ ( x )
根据表格的公式,我们可以发现两个有趣的事实
即使坐标发生了变化,但是密度与测度的乘积是不变的:
p
~
(
x
~
)
d
x
~
=
p
∘
ϕ
−
1
(
x
~
)
∣
det
∂
ϕ
∂
x
∣
∣
det
∂
ϕ
∂
x
∣
d
x
=
p
(
x
)
d
x
\tilde{p}\left(\tilde{x}\right) d\tilde{x} =\frac{p\circ \phi ^{-1}\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |} |\det\frac{\partial \phi }{\partial x} |dx=p( x) dx
p ~ ( x ~ ) d x ~ = ∣ det ∂ x ∂ ϕ ∣ p ∘ ϕ − 1 ( x ~ ) ∣ det ∂ x ∂ ϕ ∣ d x = p ( x ) d x
概率密度的比率也是不变的:
p
~
(
x
~
)
q
~
(
x
~
)
=
\frac{\tilde{p}\left(\tilde{x}\right)}{\tilde{q}\left(\tilde{x}\right)} =
q ~ ( x ~ ) p ~ ( x ~ ) =
p
∘
ϕ
−
1
(
x
~
)
∣
det
∂
ϕ
∂
x
∣
\frac{p\circ \phi ^{-1}\left(\tilde{x}\right)}{|\det\frac{\partial \phi }{\partial x} |}
∣ det ∂ x ∂ ϕ ∣ p ∘ ϕ − 1 ( x ~ )
∣
det
∂
ϕ
∂
x
∣
q
∘
ϕ
−
1
(
x
~
)
=
p
(
x
)
q
(
x
)
\frac{|\det\frac{\partial \phi }{\partial x} |}{q\circ \phi ^{-1}\left(\tilde{x}\right)} =\frac{p( x)}{q( x)}
q ∘ ϕ − 1 ( x ~ ) ∣ det ∂ x ∂ ϕ ∣ = q ( x ) p ( x )
性质2恰恰说明了为什么在统计学中为什么似然比率这么常见,因为对于比率来说,他对数据的坐标系是不敏感的 。同时这也说明了为什么散度只有在
D
(
P
,
Q
)
=
∫
f
(
p
(
x
)
,
q
(
x
)
,
x
)
d
x
=
∫
f
(
p
(
x
)
q
(
x
)
)
p
(
x
)
d
x
D( P,Q) =\int f( p( x) ,q( x) ,x) dx=\int f\left(\frac{p( x)}{q( x)}\right) p( x) dx
D ( P , Q ) = ∫ f ( p ( x ) , q ( x ) , x ) d x = ∫ f ( q ( x ) p ( x ) ) p ( x ) d x
如果散度中包含梯度,想要满足invariant的性质就更加困难了,因为梯度经过变换后是会形成一个张量的,想要有不变性,我们必须把这个张量给消除掉(乘一个逆)。举个例子,对于
(
∇
x
ln
p
(
x
)
)
T
∇
x
ln
p
(
x
)
( \nabla _{x}\ln p( x))^{T} \nabla _{x}\ln p( x)
( ∇ x ln p ( x ) ) T ∇ x ln p ( x )
(
∇
x
ln
p
(
x
)
)
T
G
−
1
∇
x
ln
p
(
x
)
( \nabla _{x}\ln p( x))^{T} G^{-1} \nabla _{x}\ln p( x)
( ∇ x ln p ( x ) ) T G − 1 ∇ x ln p ( x )
L
2
L_{2}
L 2
MMD:
D
(
Q
,
P
)
=
sup
f
∈
F
(
E
[
f
]
Q
−
E
[
f
]
P
)
D( Q,P) =\sup _{f\in \mathcal{F}}( E[ f]_{Q} -E[ f]_{P})
D ( Q , P ) = f ∈ F sup ( E [ f ] Q − E [ f ] P )
∥
1
m
∑
i
=
1
m
ϕ
(
x
i
)
−
1
n
∑
j
=
1
n
ϕ
(
y
i
)
∥
H
2
=
<
1
m
∑
i
=
1
m
ϕ
(
x
i
)
−
1
n
∑
j
=
1
n
ϕ
(
y
i
)
,
1
m
∑
i
=
1
m
ϕ
(
x
i
)
−
1
n
∑
j
=
1
n
ϕ
(
y
i
)
>
=
1
m
2
<
∑
i
=
1
m
ϕ
(
x
i
)
,
1
m
∑
i
=
1
m
ϕ
(
x
i
)
>
+
.
.
.
=
1
m
2
∑
i
=
1
m
∑
j
=
1
m
k
(
x
i
,
x
j
)
+
1
n
2
∑
i
=
1
n
∑
j
=
1
n
k
(
y
i
,
y
j
)
−
2
m
n
∑
i
=
1
m
∑
j
=
1
n
k
(
x
i
,
y
j
)
\begin{aligned} \| \frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) -\frac{1}{n}\sum ^{n}_{j=1} \phi ( y_{i}) \| ^{2}_{\mathcal{H}} & =< \frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) -\frac{1}{n}\sum ^{n}_{j=1} \phi ( y_{i}) ,\frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) -\frac{1}{n}\sum ^{n}_{j=1} \phi ( y_{i}) >\\ & =\frac{1}{m^{2}} < \sum ^{m}_{i=1} \phi ( x_{i}) ,\frac{1}{m}\sum ^{m}_{i=1} \phi ( x_{i}) >+...\\ & =\frac{1}{m^{2}}\sum ^{m}_{i=1}\sum ^{m}_{j=1} k( x_{i} ,x_{j}) +\frac{1}{n^{2}}\sum ^{n}_{i=1}\sum ^{n}_{j=1} k( y_{i} ,y_{j}) -\frac{2}{mn}\sum ^{m}_{i=1}\sum ^{n}_{j=1} k( x_{i} ,y_{j}) \end{aligned}\\
∥ m 1 i = 1 ∑ m ϕ ( x i ) − n 1 j = 1 ∑ n ϕ ( y i ) ∥ H 2 = < m 1 i = 1 ∑ m ϕ ( x i ) − n 1 j = 1 ∑ n ϕ ( y i ) , m 1 i = 1 ∑ m ϕ ( x i ) − n 1 j = 1 ∑ n ϕ ( y i ) > = m 2 1 < i = 1 ∑ m ϕ ( x i ) , m 1 i = 1 ∑ m ϕ ( x i ) > + . . . = m 2 1 i = 1 ∑ m j = 1 ∑ m k ( x i , x j ) + n 2 1 i = 1 ∑ n j = 1 ∑ n k ( y i , y j ) − m n 2 i = 1 ∑ m j = 1 ∑ n k ( x i , y j )
ϕ
(
x
)
=
x
\phi ( x) =x
ϕ ( x ) = x
ϕ
(
x
)
=
[
x
x
2
]
\phi ( x) =\left[ x\ x^{2}\right]
ϕ ( x ) = [ x x 2 ]
该补充来自:https://zhuanlan.zhihu.com/p/25071913 ,是一篇非常棒的文章
W
(
P
r
,
P
g
)
=
inf
γ
∼
Π
(
P
r
,
P
g
)
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
W(P_r, P_g) = \inf_{\gamma \sim \Pi (P_r, P_g)} \mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
W ( P r , P g ) = γ ∼ Π ( P r , P g ) inf E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ]
Π
(
P
r
,
P
g
)
\Pi (P_r, P_g)
Π ( P r , P g )
P
r
P_r
P r
P
g
P_g
P g
Π
(
P
r
,
P
g
)
\Pi (P_r, P_g)
Π ( P r , P g )
P
r
P_r
P r
P
g
P_g
P g
γ
\gamma
γ
(
x
,
y
)
∼
γ
(x, y) \sim \gamma
( x , y ) ∼ γ
∣
∣
x
−
y
∣
∣
||x-y||
∣ ∣ x − y ∣ ∣
γ
\gamma
γ
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
\mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ]
inf
γ
∼
Π
(
P
r
,
P
g
)
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
\inf_{\gamma \sim \Pi (P_r, P_g)} \mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
inf γ ∼ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ]
直观上可以把
E
(
x
,
y
)
∼
γ
[
∣
∣
x
−
y
∣
∣
]
\mathbb{E}_{(x, y) \sim \gamma} [||x - y||]
E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ]
γ
\gamma
γ
P
r
P_r
P r
P
g
P_g
P g
W
(
P
r
,
P
g
)
W(P_r, P_g)
W ( P r , P g )
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
[1] Cover, Thomas M., and Joy A. Thomas. Elements of information theory. John Wiley & Sons, 2012.short notes on divergence measures CCN2018 tutorial : Deep Generative Models