通过特定的方法将数据转换成算法要求的数据
-
数值型数据:
1.归一化
2.标准化
3.处理缺失值 -
类别型数据:
ont-hot编码
所有的对数据处理的API都放在sklearn.preprocessing里
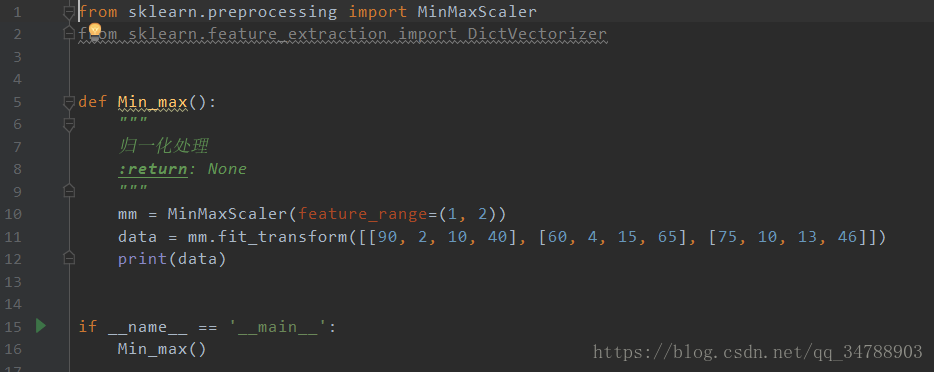
归一化
API:sklearn.preprocessing.MinMaxScaler(feature_range=指定缩放范围)
特点:通过原始数据的变换,把数据映射到莫热门的0~1之间,当然这个范围可以通过feature_range指定
MinMaxScaler(x),x为numpy array数组类型,返回shape相同的array
为什么要做归一化处理呢:
归一化除了能够提高求解速度,还可能提高计算精度。
比如:计算样本距离时,如果特征向量取值范围相差很大,如果不进行归一化处理,则值范围更大的特征向量对距离的影响更大,实际情况是,取值范围更小的特征向量对距离影响更大,这样的话,精度就会收到影响。
运行结果如下
可以看到,我们把结果数组映射到了1~2之间。
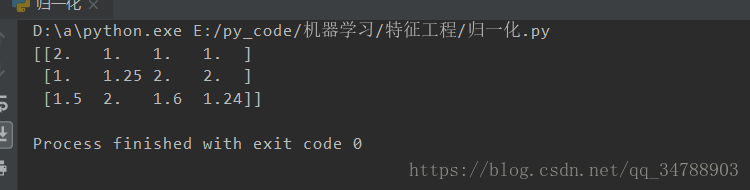
归一化的总结:
特定场景下最大最小值是变化的,如果有异常点,则影响很大,因此这只适用于高精度小数据,归一化的鲁棒性较差
(最后写一点:对于目标是算法工程师的同学来说,需要搞清楚其中的数学原理,但是我的目标仅仅是研发工程师,和我一样的同学,我们需要做的是了解数学原理,运用算法API)
标准化
前面我们说到归一化的鲁棒性较差,实际上我在后面的写代码的过程中用到归一化的情景也不多,一些算法都是要求对数据进行标准化处理
目的:使某一个特征不会对结果造成更大的影响
方差考量的是数据的稳定性。对于标准化来说,少量的异常点对平均值的影响较小,误差较小
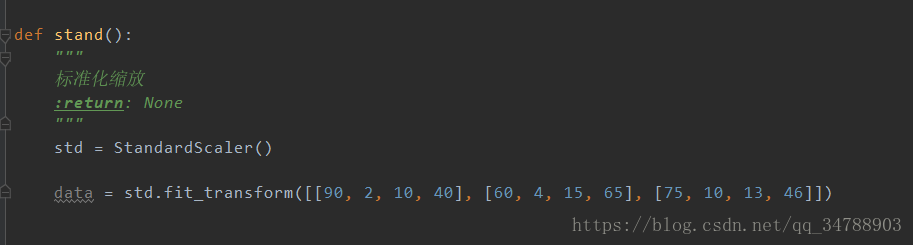
API:sklearn.preprocessing.StandandScaler
运行结果
这里看不懂没关系,后面我们只需要把数据处理,然后得到这些标准化后的数据放到算法里去计算就可以了
标准化总结:
稳定性强,适合噪音多的大数据环境,以后大部分第一选择都是标准化。
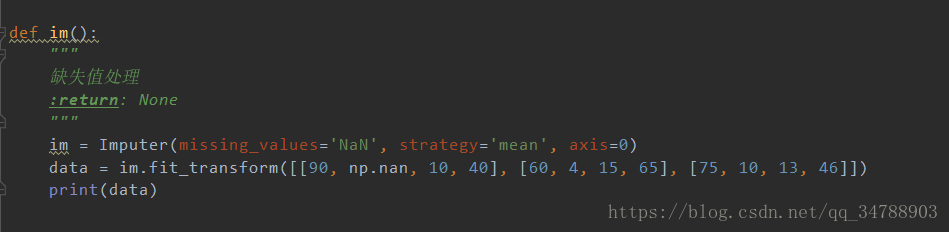
缺失值处理
数据缺失是收集数据中很常见的现象,比如物联网的传感器收集的数据很可能缺失很多,这个时候我们就需要对缺失值进行处理了
对缺失值进行处理的方法一般有两种,一个是删除,也就是直接删除数据缺失的样本,一个是填补,用行或者列的平均值或者中位数来填补缺失的数据
这里需要学习一些numpy的知识,比如numpy.dropna()就是删除np.nan类型的数据行或者列(axis指定)。numpy.fillna()就是填充
当然我们sklearn里也有处理处理缺失值的API
*sklearn.preprocessing.Imputer(missing_values=“Nan”,straegy=“mean”,axis=0)*代表的是:把nan用列的平均值填充