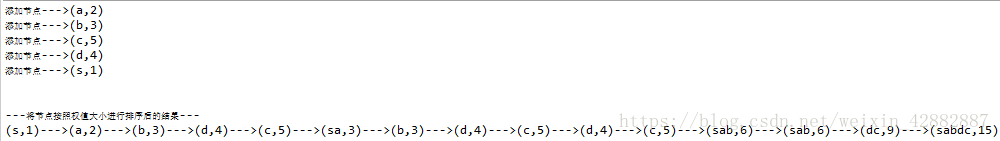在介绍哈夫曼树前先举一个小例子。
引例
设学生的成绩分为了四个等级:A,B,C,D。每个等级代表的分数和各等级人数如下所示:

现在有算法A,和算法B来求所有等级分数的总和。
算法A:
int score = 0;
if A score += 5;
else if B score +=4;
else if C score +=3
else score+=0;
算法B:
int score = 0;
if B score += 4;
else if C score +=3;
else if A score +=5
else score+=0;
分析以上两个算法:
算法A中,确定A等级需要判断1次,确定B等级需要判断2次,确定C等级需要判断3次,确定D等级也需要判断3次。
总的判断次数是:101+502+403+103 = 260次
算法B中,确定A等级需要判断3次,确定B等级需要判断1次,确定C等级需要判断2次,确定D等级也需要判断3次。
总的判断次数是:
103+501+402+103 = 190次
明显B算法比A算法的判断次数要少,即判断效率较高。
通常,将效率最高的判别树称之为哈夫曼树,也叫最优树。
基本概念
路径和路径长度:在一棵树中,从一个节点往下可以达到的孩子或孙子节点之间的通路,称为路径。通路中分支的数目成为路径长度。若规定跟节点的层数为1,则从根节点到L层节点的路径长度为L-1.
节点的权及带权路径长度:若将树种节点赋给一个有着某种含义的数值,则这个数值称为该节点的权。节点的带权路径的长度为:从跟节点到该节点之间的路径长度与该点的权的乘积。
树的带权路径长度:树的带权路径长度规定为所有叶子节点的带权路径长度之和,记为WPL。
带权路径长度WPL最小的二叉树称为哈夫曼树或最优二叉树。
哈夫曼二叉树的构建
将上面的引例简化为:
有5个节点a,b,c,d,s权值分别为2,3,8,9,1,现在来构造以该5个节点为叶子节点的二叉树。
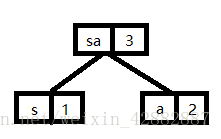
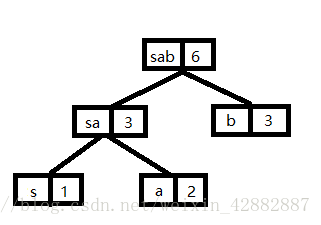
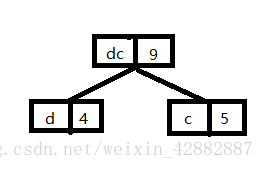
首先从这5个节点中取出权值最小的两个节点,这里是节点s和节点a,将这两个节点作为左右子树构造一棵新的二叉树,且置新的二叉树的根节点的权值为左右子树根节点的权值之和。现在有新节点,c,d,s这4个节点,重复上述步骤即可。图示如下:(注意这里都是取的是新节点和剩余节点权值进行排序之后的较小的两个节点进行新节点的建立)
最后这张图就是建好的哈夫曼树啦
可以知道哈夫曼树的一些特点:
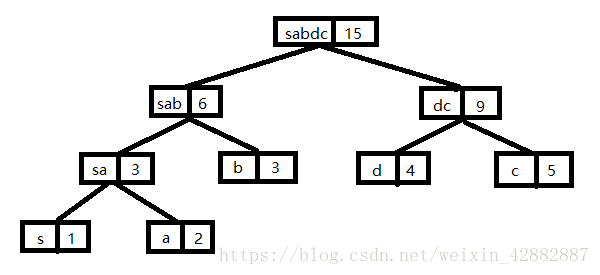
- 哈夫曼树中权值越大的叶子离根越近;
- 哈夫曼树 的节点读书为0或2,没有度数为1的节点;
- 包含n棵树的森林要经过n-1次合并才能形成哈夫曼树,共产生n-1个新节点;
哈夫曼编码
哈夫曼树的应用很广,哈夫曼编码就是它在通信中的应用之一。它广泛地用于数据文件压缩,压缩率通常在20%~90%之间。在通信业务中,通常用二进制编码来表示字母或其他字符。
实际应用中各字符出现频度不相同,用短编码表示频率大小地字符,使得编码序列的总长度最小,所需空间量少。
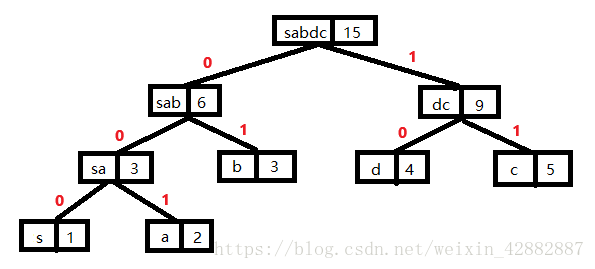
在哈夫曼树的编码过程中:将二叉树引向左孩子的分支标记为"0",右孩子的分支标记为"1",这样每个字符的编码即为从根到每个叶子的路径上得到的0,1序列。这样得到的是二进制前缀编码。
上面所画的二叉树加上编码之后得到:
最终得到的结果是:
叶子节点s的编码:000;
叶子节点a的编码:001;
叶子节点b的编码:01;
叶子节点d的编码:10;
叶子节点c的编码:11。
哈夫曼压缩
进行哈夫曼的压缩的步骤:
1.首先将字符串编码过程中的那些单个字符代表的编码按一定的格式存入文件中去
(s,1)–叶子节点编码是–>000
(a,2)–叶子节点编码是–>001
(b,3)–叶子节点编码是–>01
(d,4)–叶子节点编码是–>10
(c,5)–叶子节点编码是–>11
这样首先存入文件中的内容是编码表:s3000a3001b201d210c211
2.再将以上字符串编码之后的内容以8个单位进行分组,最后不足8个单位的用0来补(需要做好标记补了几个0)
将字符串aabbbcccccdddds进行编码之后是–>001001010101111111111110101010000
这样分组是:00100101 01011111 11111110 10101000 0,最后剩的这个0用0来补齐为8个
分组的最终结果是:00100101 01011111 11111110 10101000 00000000,将它们变为字符串存入一个list中去
现在调用public static int parseInt(String s,2),使用第二个参数指定的基数,将字符串参数解析为有符号的整数,返回得到的整数值
将每个组中的八个单元构成的字符s用以上方法变为整数,转换为整数是:37,95,254,168,0
再将该整数强制转换为byte类型存入一个byte类型的数组中去(注意:这里的整数范围是0~256)
紧接着编码表存入文件中的是最后一个分组中的补零的个数,再将list中的内容接着这个补零个数存入文件中去
哈夫曼解压
进行哈夫曼解压的步骤:
首先需要读取刚刚存储的文件
将前面的编码表读出来,得到每个字符所对应的编码,后面需要根据这些编码来进行解压
再将后面的byte数组中的内容一个一个读出来,读出来的byte类型又转换为01表示(注意这里需要将最后补零项去掉)
再对照之前读出来的编码表,将字符一个一个比对翻译出来,至此,解压完成
所有功能的代码实现
定义的节点类代码:
package 哈夫曼二叉树;
/**
* 哈夫曼二叉树
* 定义节点类
* @author HP
*
*/
public class Node {
private Object data;//数据项
private Node left;
private Node right;
private Node parent;
private int weight;//权值
//增加代表节点编码的code项
private String code = "";
public Node() {
}
public Node(Object data,int weight) {
super();
this.data = data;
this.weight = weight;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
public void setParent(Node parent) {
this.parent = parent;
}
public Node getParent() {
return parent;
}
}
哈夫曼树的构建&&哈夫曼编码&&哈夫曼压缩
package 哈夫曼二叉树;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
/**
* 哈夫曼二叉树多了一个权值
* 例如:有一串字符,它的权值就可以使字符串中每个字符出现的次数
*/
import java.util.ArrayList;
public class Huffman_Tree {
private Node root;
//存放权值weight的数组(这里的权值是每个字符出现的次数)
//这里选用128的原因是ASCII码的值分布在0~127
private byte[] count = new byte[128];
//存字符的ascii码对象
ArrayList<Object> numlist = new ArrayList<Object>();
//存哈夫曼树的节点
ArrayList<Node> list_tree = new ArrayList<Node>();
//存储编码后的8个单元的字符
ArrayList<String> code_8 = new ArrayList<String>();
//存储8个单元字符转换后的数字(0~256)
ArrayList<Byte> num_8 = new ArrayList<Byte>();
//存储节点
ArrayList<Node> list = new ArrayList<Node>();
private String str;
//第一步,统计字符串中每个字符出现的次数,并且生成节点
public void classify(String str) {
this.str = str;//将str传递到类的属性中去
//统计str字符串中每个字符出现的次数
//将每个字符的ASCII码存放在num权值数组中去
for(int i=0;i<str.length();i++) {
char ch = str.charAt(i);
int n = ch;//将取出来的单个字符转换为ASCII码
//将数组num在ascii这个位置(也代表字符)的次数加1;
count[n]++;
}
//统计完后根据这些权值生成节点
for(int i=0;i<count.length;i++) {
if(count[i] != 0) {//如果num中没有存值,表示没有这个字符
//获取字符
char ch = (char)i;
String data = ch+"";
//获取该字符出现的次数
int times = count[i];
//Node(Object data,int weight)
//调用构造函数,将字符ch设为节点的数据项,字符出现的次数作为权值------>经常用于文件的压缩
Node node = new Node(data,times);
System.out.println("添加节点--->"+"("+node.getData()+","+node.getWeight()+")");
list.add(node);
//list_tree.add(node);
}
}
System.out.println();
System.out.println();
//注意添加节点之后再次进行排序
System.out.println("---将节点按照权值大小进行排序后的结果---");
sort();
}
//第二步根据每个字符的权值进行排序(出现次数从小到大)
public void sort() {
//System.out.println("------将刚刚添加进去的节点按照权值进行从小到大的排序------");
for(int i = 0;i<list.size();i++) {
for(int j =i+1;j<list.size();j++) {
//比较两个节点的权值大小
if(list.get(i).getWeight() > list.get(j).getWeight()) {
//交换两个节点的位置
Node node = list.get(i);
list.set(i, list.get(j));
list.set(j, node);
}
}
}
//这里将排序后的结果进行输出
//将节点list种的内容全部输出的时候判断条件是list.size()
for(int i=0;i<list.size();i++) {
System.out.print("("+list.get(i).getData()+","+list.get(i).getWeight()+")"+"--->");
}
}
public void create_tree(String str) {
classify(str);
//第三步,取权值最小的两个节点,构建一个新节点,并放回系放回节点列表中去
//第四步,重复第三步骤,直到只剩一个节点(这个可以在第三步写的方法中使用递归方法)
//注意这里是在list中最终只剩下一个节点的时候退出循环
while(list.size()>1) {
//因为是按权值从小到大进行排序,那么取出前面两个权值最小的节点组成一个新的节点
Node left = list.remove(0);
Node right = list.remove(0);
//将取出来的数据项变为String类型
//这里的 ---(String)left.getData()---可以换为---left.getData().toString ---
Node newnode = new Node((String)left.getData()+(String)right.getData(),left.getWeight()+right.getWeight());
//设置刚刚取出来的两个节点为新建节点的左右节点
newnode.setLeft(left);
newnode.setRight(right);
//将新节点作为左右子节点的父节点
left.setParent(newnode);
right.setParent(newnode);
//将刚刚生成的节点加入到list中的第一个位置去
list.add(0, newnode);
//将节点添加进去之后还应该将list中的节点按照权值大小重新排序
sort();
}
//最后list中只有一个节点,这个节点为根节点
root = list.get(0);
}
public void show() {
//这里选择先序遍历该生成的二叉树
//node与list注意区分,这里是将节点node存入list中去,list中有多少节点和有多少个node不一样
System.out.println();
System.out.println();
System.out.println();
System.out.println("------先序遍历二叉树------");
PreOrder(root);
}
//进行哈夫曼编码,在这一步需要在节点中添加一项代表节点编码的code项
//首先需要遍历这个哈夫曼树,将叶子节点找出来
public void huffman() {
huffman_code(root);
}
private Node node1;
public void huffman_code(Node node) {
if(node.getLeft() != null) {
//System.out.println("节点--"+node.getWeight()+"---的编码是--->"+node.getCode());
node1 = node.getLeft();
node1.setCode(node.getCode()+"0");
huffman_code(node1);
}
if(node.getRight() != null) {
node1 = node.getRight();
node1.setCode(node.getCode()+"1");
huffman_code(node1);
}
//将叶子节点加入一个list_tree中去
if(list_tree.contains(node1))
{}else {
System.out.println();
list_tree.add(node1);
}
//System.out.println("节点--"+node1.getWeight()+"---的编码是--->"+node1.getCode());
}
//先序遍历哈夫曼树
public void PreOrder(Node node) {
huffman_code(root);
System.out.println("("+node.getData()+","+node.getWeight()+")"+"--节点编码是-->"+node.getCode());
if(node.getParent() !=null) {
System.out.println("节点"+node.getWeight()+"的父类是"+node.getParent().getWeight());
}
if(node.getLeft() != null) {
PreOrder(node.getLeft());
}
if(node.getRight() != null) {
PreOrder(node.getRight());
}
}
//找到哈夫曼树的叶子节点
public void leaf_node_find() {
System.out.println("叶子节点的个数是-->"+list_tree.size());
for(int i=0;i<list_tree.size();i++) {
System.out.println("("+list_tree.get(i).getData()+","+list_tree.get(i).getWeight()+")"+"--叶子节点编码是-->"+list_tree.get(i).getCode());
}
}
//将之前输入的字符进行编码输出
private String str_code = "";//str_code存储的是编码字符之后的
public void code_str() {
for(int i=0;i<str.length();i++) {
char ch = str.charAt(i);
String ch_ = ch+"";
//从字符串中找到与叶子节点的数据项相同的字符,进行编码
//(其实不用特意找到叶子节点,毕竟在这里只有叶子节点的数据项才可能为单个字符)
//System.out.println("ch-->"+ch);
for(int j=0;j<list_tree.size();j++) {
//System.out.println("list_tree-->"+list_tree.get(j).getData().toString());
if(ch_.equals(list_tree.get(j).getData().toString())) {
str_code += list_tree.get(j).getCode();
//System.out.println("现在的编码是"+str_code);
break;
}
}
}
System.out.println("将字符串"+str+"进行编码之后是--->"+str_code);
}
//====================================================================
private String code_table = "";
private String s;
private int length;//补0的个数
//现在进行压缩文件咯
public void compression() {
//编码表的制作
for(int i=0;i<list_tree.size();i++){
//code_table;
Node node = list_tree.get(i);
String character = node.getData().toString();
String code = node.getCode();
length = code.length();
code_table += "@"+character+length+code;
}
System.out.println(code_table);
System.out.println();
System.out.println("2.--将字符串编码后的内容进行八个单元分组--");
System.out.println("原来的字符串编码内容是-->"+str_code);
//将字符串进行分组
System.out.println(str_code.length());
for(int i=0;i<str_code.length();i+=8) {
s = "";
for(int j=i;j<8+i && j<str_code.length();j++) {
char ch = str_code.charAt(j);
s += ch;
}
System.out.println(s);
code_8.add(s);
}
//从code_8中取出最后一个存储的字符进行判断和补零
if(code_8.get(code_8.size()-1).length() < 8) {
String s1 = code_8.get(code_8.size()-1) ;
//补0的个数
length = 8-s1.length();
System.out.println("最后一组补0的个数--->"+length);
for(int i=0;i<length;i++) {
s1 += "0";
}
System.out.println(s1);
code_8.remove(code_8.size()-1);
code_8.add(s1);
}
System.out.println();
System.out.println("--分好组并且补好0后的结果--");
for(int i=0;i<code_8.size();i++) {
System.out.print(code_8.get(i)+"--转换为整数-->");
//进行数字的转换
int num = Integer.parseInt(code_8.get(i), 2);
System.out.println(num);
byte n = (byte) num;
num_8.add(n);//将数字转换为byte类型存入,再将其存入文件中去
}
//将以上的编码表,补零个数,num_8中的整数存入文件中去
String filepath = "C:\\Users\\HP\\Desktop\\compression.txt";
File file = new File(filepath);
//创建流
try {
OutputStream out = new FileOutputStream(file);
byte buffer1[] = code_table.getBytes();
//1.首先写入编码表
System.out.println("buffer1-->"+code_table);
out.write(buffer1);
byte buffer2[] = {(byte)length};
//写入分隔符@
//out.write("@".getBytes());
out.write("*".getBytes());
//2.再写入补0长度
System.out.println("buffer2-->"+length);
out.write(buffer2);
//写入分隔符@
out.write("#".getBytes());
//将num_8中的数字加入byte数组再写入文件
byte buffer3[] = new byte[num_8.size()];
for(int i=0;i<num_8.size();i++) {
buffer3[i] = num_8.get(i);
}
//3.将数字写入
System.out.println("buffer3-->"+buffer3[2]);
out.write(buffer3);
out.flush();
out.close();
} catch ( IOException e) {
e.printStackTrace();
}
}
}
哈夫曼解压(注意这是重新定义的,与前面的类无关系,完全可以在另一个包中进行解压的操作)
首先另外定义一个节点类:
package 哈夫曼二叉树;
public class Node_compression {
private Object data;//数据项
private Node left;
private Node right;
private Node parent;
private String code;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
private int weight;//权值
public Node_compression(Object data) {
this.data = data;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
public Node getParent() {
return parent;
}
public void setParent(Node parent) {
this.parent = parent;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
进行解压过程
package 哈夫曼二叉树;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
/**
* @author HP
*
*/
public class Decompression {
ArrayList<Node_compression> list = new ArrayList<Node_compression>();
ArrayList list_str = new ArrayList();
private int length_0 = 0;
private int sign_number = 0;
private int max_code = 0;
private String str_binary = "";
private String str1;
public void decompression() {
String filepath = "C:\\Users\\HP\\Desktop\\compression.txt";
//创建流
try {
InputStream in = new FileInputStream(filepath);
byte[] buffer = new byte[in.available()];
in.read(buffer);
int sign = 64;//@字符的ASCII码
int sign1 = 42;//*字符的ASCII码
int sign2 = 35 ;//#字符的ASCII码
ArrayList<Integer> l = new ArrayList<Integer>();
System.out.println("将文件中的ASCII码转换为字符");
int b=0;
String str = new String(buffer);
System.out.println(str);
for(int i=0;i<buffer.length;i++) {
if(buffer[i] == sign) {//如果碰到@不处理
l.add(i);
}
}
System.out.println();
//System.out.println("l****>"+l);l中的内容表示分隔符@的位置
//读取各个字符的编码
for(int i=0;i<l.size();i++) {
int index = l.get(i);//获取每个@的位置处的下标
System.out.println("index-->"+index);
if(index+1 <buffer.length) {
char s = (char)buffer[index+1];
Node_compression node = new Node_compression(s);//index+1位置处存放的是字符
list.add(node);
char c1 = (char)buffer[index+2];//index+2处存放的是该字符编码的长度
int length = Integer.parseInt(c1+"");//得到编码的长度
String code = "";
for(int k=index+3;k<index+3+length;k++) {
code += (char)buffer[k];
}
System.out.println("解得到的"+node.getData()+"编码是"+code);
node.setCode(code);
}
}
System.out.println("恢复出来的编码表:");
System.out.println("==============");
for(int i=0;i<list.size();i++) {
System.out.println(list.get(i).getData()+"--->"+list.get(i).getCode());
}
System.out.println("==============");
//----------------------------------------------------------------------------------------
System.out.println();
System.out.println();
//接下来读取补零的个数
for(int i=0;i<buffer.length ;i++) {
if(buffer[i] == sign1&& i+1<buffer.length) {
length_0 = Integer.parseInt(buffer[i+1]+"");
break;
}
}
System.out.println("补0的个数为"+length_0);
//接下来读取数字然后将数字转变为01表示的二进制
for(int i=0;i<buffer.length ;i++) {
if(buffer[i] == sign2) {
sign_number = i;
}
}
for(int i=sign_number+1;i<buffer.length;i++) {
if(buffer[i]<0) {
//读取数字
int num = (int)(buffer[i]+256);
System.out.println(num);
//将数字转换为二进制01表示
String binary_num = Integer.toBinaryString(num);
System.out.println("原来的"+binary_num);
String s = "";
while(binary_num.length()<8) {
int g = 8-binary_num.length();
String zero = "0";
binary_num = zero + binary_num;
}
System.out.println("读取到数字是"+num+",该数字对应的二进制表示是"+binary_num);
str_binary += binary_num;
}else {
int num = (int)buffer[i];
System.out.println(num);
//将数字转换为二进制01表示
String binary_num = Integer.toBinaryString(num);
System.out.println("原来的"+binary_num);
String s = "";
while(binary_num.length()<8) {
int g = 8-binary_num.length();
String zero = "0";
binary_num = zero + binary_num;
}
System.out.println("读取到数字是"+num+",该数字对应的二进制表示是"+binary_num);
str_binary += binary_num;
}
}
System.out.println();
System.out.println();
System.out.println("读取到的数字所组成的二进制字符串为:"+str_binary);
//根据读取的补零长度来减掉这些个0
str1 = str_binary.substring(0, str_binary.length()-length_0);
System.out.println("二进制字符串去掉补的0--->"+str1);
//根据前面读取的编码表将字符还原出来
//list当中存的节点含有节点的编码信息
//将还原出来的二进制字符串和list中的node进行比对,然后找出对应的字符
//找到所有字符编码中最长的
for(int i=0;i<list.size();i++) {
Node_compression node = list.get(i);
if(max_code <= node.getCode().length()) {
max_code = node.getCode().length();
}
System.out.println(node.getData()+"--->"+node.getCode());
}
System.out.println("max_code--->"+max_code);
System.out.println("原来字符串经过编码之后:str_code--->"+str1);
System.out.println();
System.out.println();
System.out.println("========================================");
System.out.println("对照编码表找出编码字符串中所对应的字符");
//将编码从大到小与二进制字符串中的内容进行比对
String string = str1;
int i = 0;
int t = 0;
for(int h = 0;h<buffer.length;h++) {
for(i = max_code;i>0 && string.length()>0;i--) {
System.out.println(string+"-->string现在的值");
String s = string.substring(0, i);
System.out.println(s+"-->取出的一部分字符");
//循环找到匹配的字符编码
for(int j=0;j<list.size();j++) {
if(s.equals(list.get(j).getCode())) {
t = 1;
System.out.println(list.get(j).getData()+"--->"+list.get(j).getCode());
list_str.add(list.get(j).getData());
string = string.substring(i,string.length());
System.out.println(string+"-->减掉匹配后的字符string");
}
}
System.out.println("i "+i);
}
}
//打印出还原的字符串内容
//aabbbcccccdddds
//aabbbcccccddddss
for(int j=0;j<list_str.size();j++) {
System.out.print(list_str.get(j));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
最后定义一个测试类,测试哈夫曼树的构建,哈夫曼编码,哈夫曼压缩以及解压
package 哈夫曼二叉树;
public class Test {
public static void main(String[] args) {
Huffman_Tree ht = new Huffman_Tree();
String str = "aabbbcccccdddds";
ht.create_tree(str);
ht.show();
System.out.println();
System.out.println("哈夫曼编码测试");
ht.huffman();
ht.leaf_node_find();
ht.code_str();
System.out.println();
System.out.println("============================");
System.out.println("-----------压缩文件-----------");
System.out.println("============================");
System.out.println("1.-----------编码表-----------");
ht.compression();
System.out.println();
System.out.println("============================");
System.out.println("-----------解压文件-----------");
System.out.println("============================");
Decompression dc = new Decompression();
dc.decompression();
// String str3 = "absdefg";
//
// String str4 = str3.substring(0,2);//测试,好像是左加右不加
// System.out.println(str4);
}
}
输入一串字符:aabbbcccccdddds
这里将以上每一步划分为更细的输出结果进行展示
最终得到的哈夫曼树:
进行哈夫曼编码后:
压缩文件:
解压文件: