web编程基础知识
HTML基础格式
HTML文件以开头,以结束。
head部分,HTML的头部,定义网页的标题及其他的一些属性。
body是网页的核心内容部分
所以格式大纲为:
CSS基础格式
selector {property: value}
css规则由两个主要的部分构成:选择器以及一条或者多条申明
选择器通常是您需要改变的HTML的样式
每条申明由一个属性和一个值构成
理解HTML和CSS之间的关系
HTML超文本标记语言,是描述网页文档的一种标记语言。
CCS(Cascading Style Sheet)可译为叠层样式表或者级联样式表,它定义如何显示HTML的元素,控制Web的外观
一个书写内容,一个装扮
样式表定义如何显示HTML元素,样式通常保存在外部的.css文件中,通过仅仅编辑一个简单的css文档,外部样式表使你有能力同时改变站点中的所有页面的布局和外观
作为一个网页开发者,你可以为每个元素定义样式,并将之应用于你希望的任意多的页面中。如需进行全局的更新,你只需要简单的改变样式,然后网站中的所有元
如何打开电脑开发者工具
笔者电脑windows chrome
打开chrome,用快捷键Fn+F12打开(重新按上面快捷键组合可以取消)
或者用快捷键(ctrl + shift +I)也可以打开开发者工具
查看开发者工具中的Elements对应的HTML。如果需要在web抓取程序中解析HTML,这很有帮助。得到HTML信息之后,你需要弄清楚,那部分对应于页面上你感兴趣的信息。然后截取信息,做相应的代码处理
如何找到HTML对应的网页的感兴趣的信息
举例说明:打开http://weather.gov/天气查询网站,然后查询邮政编码94105多对应的天气信息。
- 进入网站并打开开发者工具
- 定位网页中感兴趣的信息在HTML的位置
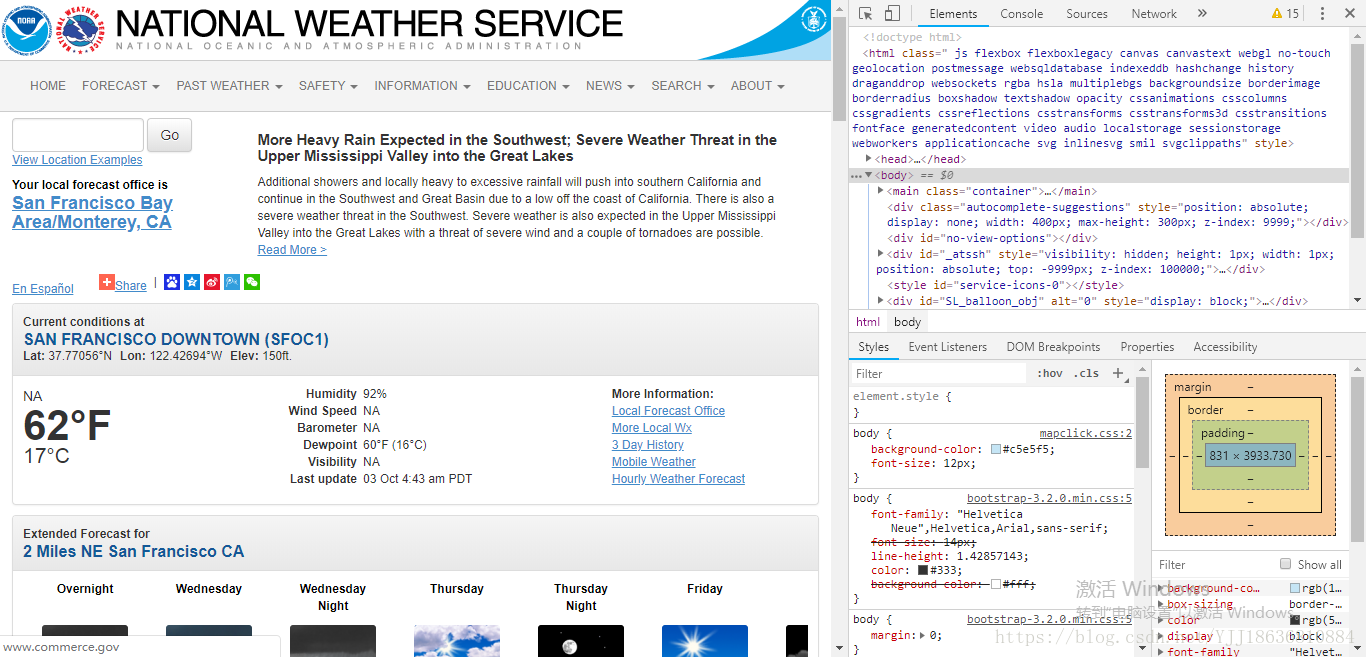
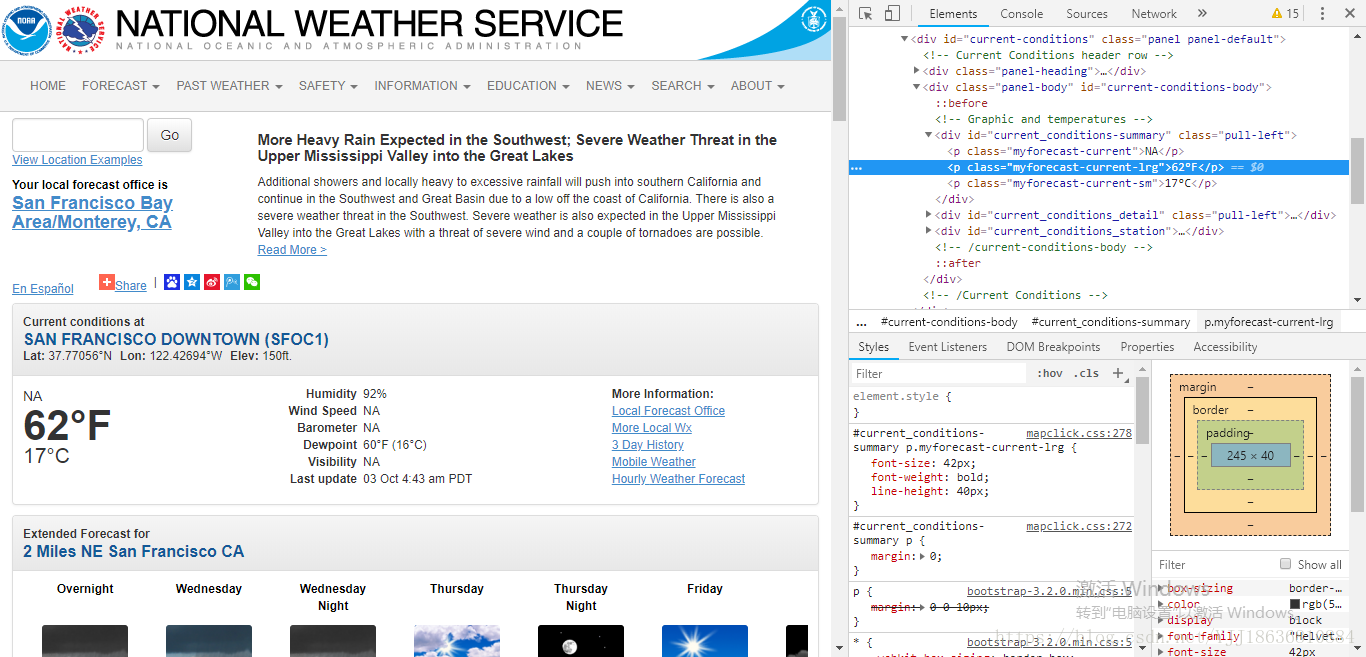
通过开发者工具,我们看到网页中负责气温部分的HTML是
“class=“myforecast-current-lrg”>62°F”,说明:气温包含在上述元素中,带有myforecast-current-lrq 类,接下来就可以用Python中的BeattifulSoup模块找到相应的信息
下面实例需要用到Python模块:requests, webbrowser, bs4
Python实例1:
#用requests.get()函数下载并保存网页内容
import requests
res = requests.get("'http://www.gutenberg.org/cache/epub/1112/pg1112.txt")
#检查下载是否正确
res.raise_for_status()
#将下载的文件保存到硬盘
playFile = open('RomeoAndJuliet.txt', "wb") #注意:这儿必须用“wb”格式打开
for chunk in res.iter_content(100000): #这是为了确保及时下载巨大的文件,也不会消耗太多的内存
playFile.write(chunk)
playFile.close()
Python实例2:
“I feeling lucky”Google 查找
我们在浏览器中查看一个主题的时候,我们一般不会只看一个查询结果,我们会查询前几个链接,然后综合比对整合前几个搜索结果的信息;我们希望这能够成为一个自动工作,输入查找主题词,就能让计算机自动打开浏览器,显示前几项查询
任务要做的事情:
从命令行参数中获取查询关键字
取得查询结果页面
为每个结果打开一个浏览器选项卡
伪代码:
从sys.argv中读取命令行参数
用requests模块取得查询结果页面
找到每个查询结果的链接(search)
调用webbrowser.open()函数打开web浏览器
代码:
#! python 3
#lucky.py - Opens several Google search results
import requests, sys, webbrowser, bs4
print('Googling ...') #display text while downloading the google page
res = requests.get('http://google.com/search?/q' + ' '.join(sys.argv[1:]))
res.raise_for_status()
#Retrieve top search result links
soup = bs4.BeautifulSoup(res.text)
#Open a browser tab for each result
linkElems = soup.select('.r a') #我们搜寻的结果的储存在r类中<a>元素中
numopen = min(5, len(linkElems))
for i in range(numopen):
webbrowser.open('http://google.com' + linkElems[i].get('href'))
附录说明:
如何在windows中命令行中运行Python代码
- 安装Python之后将运行目录添加到path变量中
- win+R打开命令行环境,切换到Python运行的文件夹中
- 输入python * .py 运行Python文件,实例如下:
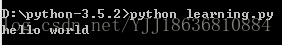
参考文档
(https://wenwen.sogou.com/z/q325973198.htm)
参考书籍
《Python编程快速上手——让繁琐工作自动化》