一. 爬取所有银行的银行名称和官网地址,并写入数据库。
import re
from urllib.request import urlopen
from urllib import request
import pymysql
def get_content(url):
"""
获取网页内容
:param url:
:return:
"""
user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0"
req = request.Request(url, headers={'User-Agent': user_agent})
content = urlopen(req).read().decode('utf-8')
return content
def parser_get_add_url(content):
"""
解析银监会官网内容,获取所有银行官网地址
:param content:
:return:123.com.cn
"""
pattern = r'<a href="([^\s+]*\:\/\/[^\s+]*)" target="_blank" style="color:#08619D">\s+([^\s+]*)\s+</a>'
bankUrl = re.findall(pattern, content.replace('\n', ' '))
return bankUrl
def main():
conn = pymysql.connect(user='root', password='westos', charset='utf8', autocommit=True, db='bankurl')
CBRCurl = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
content = get_content(CBRCurl)
urlLi = parser_get_add_url(content)
print(urlLi)
with conn:
cur = conn.cursor()
create_table = 'CREATE TABLE bankurl(bank_name VARCHAR (30),url VARCHAR(40));'
cur.execute(create_table)
for url in urlLi:
insert_url = 'INSERT INTO bankurl VALUES ("%s", "%s");' % (url[1], url[0])
cur = conn.cursor()
res = cur.execute(insert_url)
print(res)
main()
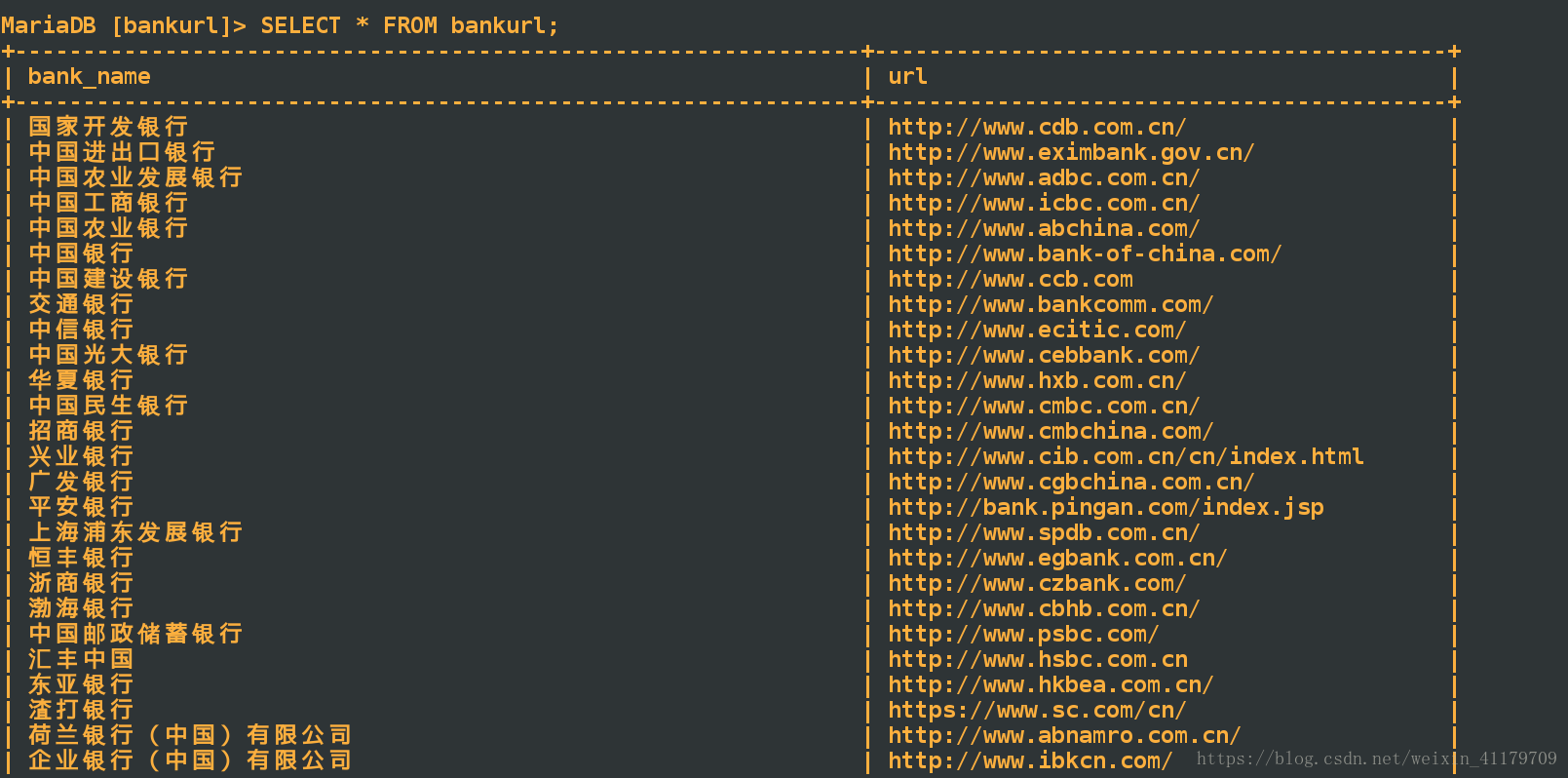
存入数据库结果:
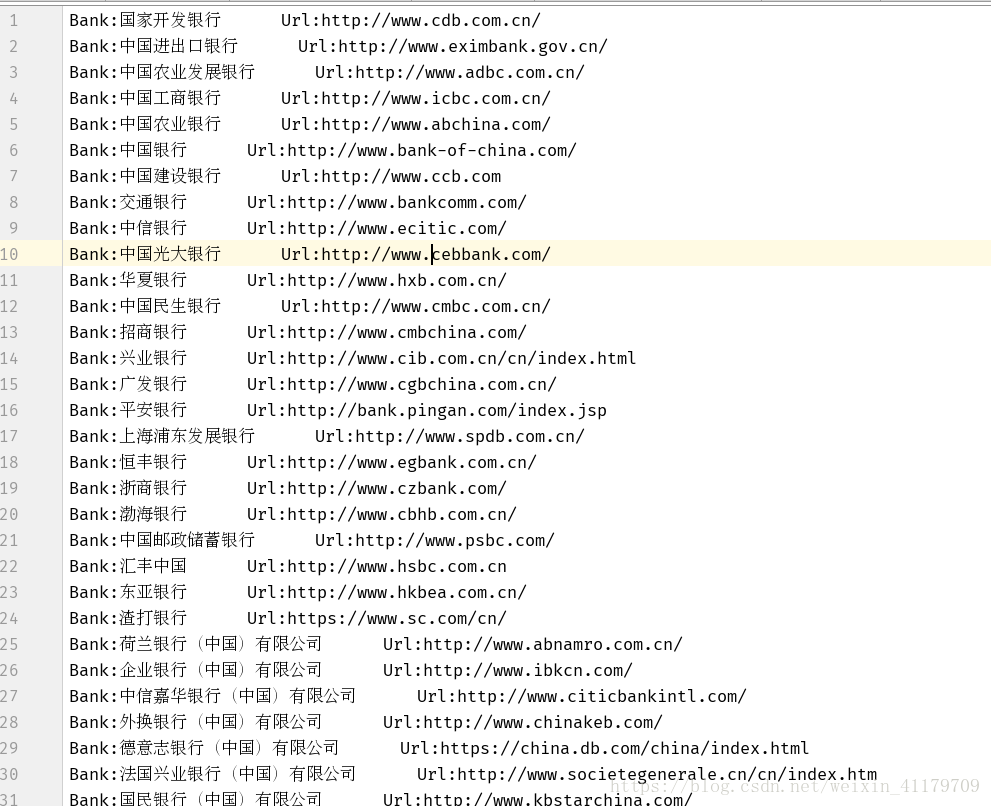
存入文件中:
1. 爬取内容: 电影名称,主演, 上映时间,图片url地址保存到mariadb数据库中;
import re
from urllib.request import urlopen
from urllib import request
import pymysql
def get_content(url):
"""
获取网页内容
:return:
"""
user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0"
req = request.Request(url, headers={'User-Agent': user_agent})
content = urlopen(req).read().decode('utf-8')
return content
def parser_all_page():
FilmInfo = []
conn = pymysql.connect(user='root', password='westos', charset='utf8', autocommit=True, db='FilmInfo')
with conn:
cur = conn.cursor()
create_table = 'CREATE TABLE FilmInfo(FilmName VARCHAR (30),FilmStar VARCHAR(40),ReleaseTime VARCHAR(40));'
cur.execute(create_table)
for i in range(10):
url = 'http://maoyan.com/board/4?offset=%d' %(i*10)
print("正在爬取第%d页" %(i+1))
content = get_content(url)
pattern = r'<div class="movie-item-info">\s+<p class="name"><a href="/films/\d+" title="\w+" data-act="boarditem-click" data-val="{movieId:\d+}">([^\s+]*)</a></p>\s+<p class="star">\s+主演:([^\s+]*)\s+</p>\s+<p class="releasetime">上映时间:([^\s+]*)</p>\s+</div>'
Info = re.findall(pattern,content)
print(Info)
for film in Info:
insert_url = 'INSERT INTO FilmInfo VALUES ("%s", "%s" ,"%s");' % (film[0], film[1],film[2])
cur = conn.cursor()
res = cur.execute(insert_url)
FilmInfo.append(Info)
return FilmInfo
def main():
parser_all_page()
main()
运行结果

存入数据库:

2.所有的图片保存到本地/mnt/maoyan/电影名.png(未完待续)