Python爬虫练习
工作需要学习Python,随手找了个小说网站,写了个下载小说的功能
小说网站:www.tianxiabachang.cn

选择第一个小说: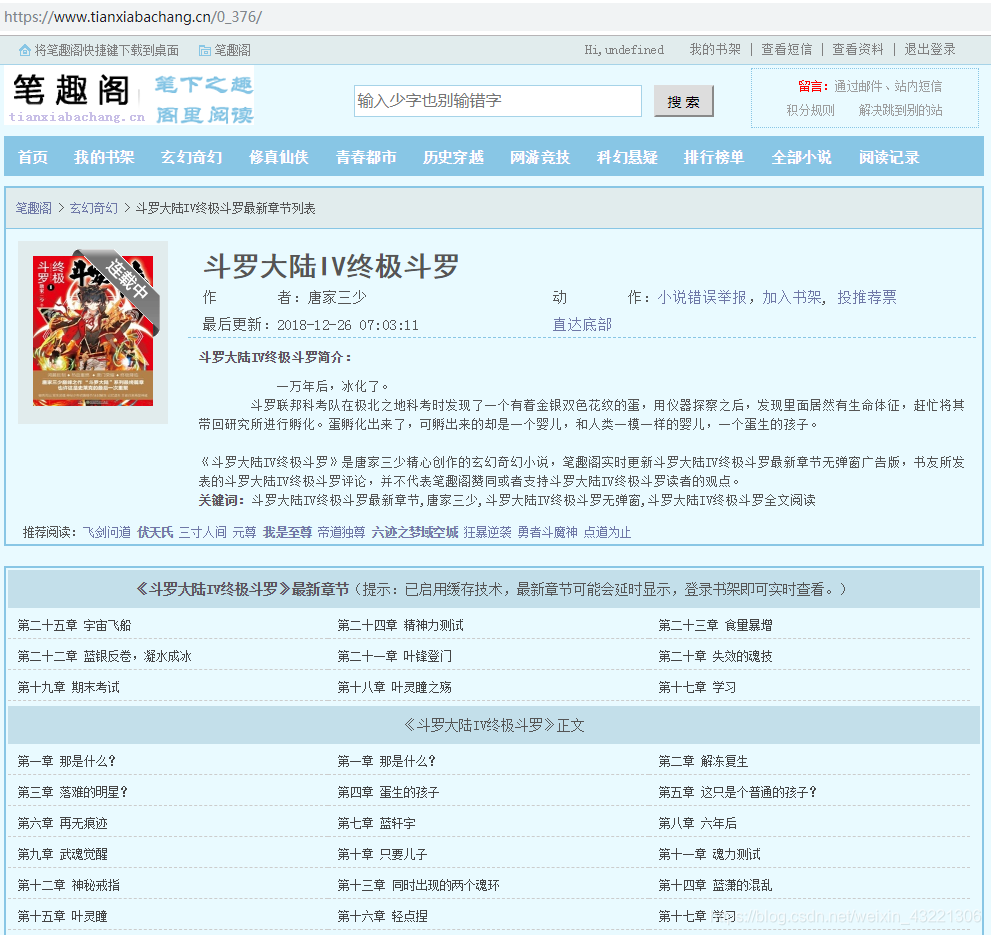
1、可以发现网站是使用“0_376”来标记这本小说,根据这个标号提供下载功能。
2、查看网页源代码:
<div id="maininfo">
<div id="info">
<h1>斗罗大陆IV终极斗罗</h1>
<p>作 者:唐家三少</p>
<p>动 作:<a href="/newmessage.php?tosys=1&title=小说《斗罗大陆IV终极斗罗》错误举报!&content=举报原因如下:缺少第( )章;第( )章没内容;其他原因:" target="_blank" rel="nofollow">小说错误举报</a>,<a href="javascript:;" onClick="showpop('/modules/article/addbookcase.php?bid=376&ajax_request=1');">加入书架</a>, <a href="javascript:;" onClick="showpop('/modules/article/uservote.php?id=376&ajax_request=1');">投推荐票</a></p>
<p>最后更新:2018-12-26 07:03:11</p>
<p><a href="#footer">直达底部</a></p>
</div>
<div id="intro">
<b>斗罗大陆IV终极斗罗简介:</b>
<p> 一万年后,冰化了。
<br/> 斗罗联邦科考队在极北之地科考时发现了一个有着金银双色花纹的蛋,用仪器探察之后,发现里面居然有生命体征,赶忙将其带回研究所进行孵化。蛋孵化出来了,可孵出来的却是一个婴儿,和人类一模一样的婴儿,一个蛋生的孩子。
<br/>
<br/>《斗罗大陆IV终极斗罗》是唐家三少精心创作的玄幻奇幻小说,笔趣阁实时更新斗罗大陆IV终极斗罗最新章节无弹窗广告版,书友所发表的斗罗大陆IV终极斗罗评论,并不代表笔趣阁赞同或者支持斗罗大陆IV终极斗罗读者的观点。<br/></p>
<b>关键词:</b>斗罗大陆IV终极斗罗最新章节,唐家三少,斗罗大陆IV终极斗罗无弹窗,斗罗大陆IV终极斗罗全文阅读 </div>
</div>
可以发现书籍名称被包含在h1 书籍名 /h1之中,编写对应的正则表达式直到只剩一个结果。
正则表达式结果:(?<=h1>).*(?=<)
3、继续查看网页代码:
<dd><a href="/0_376/2014050.html">第一章 那是什么?</a></dd>
<dd><a href="/0_376/2014052.html">第一章 那是什么?</a></dd>
<dd><a href="/0_376/2014280.html">第二章 解冻复生</a></dd>
<dd><a href="/0_376/2014932.html">第三章 落难的明星?</a></dd ```
可以看到这个页面包含了所有我们需要的章节的链接,对代码进行处理,最后适用的正则表达式:/%s/[0-9]+.html(?=")
4、上一步完成后就得到了所有章节的链接,接下来就是在章节的展示页面爬去小说的标题和内容了:
# 小说标题
<h1> 第一章 那是什么?</h1>
# 和书籍名使用相同的正则表达式即可
# 小说内容
<div id="content"> 圆饼状的全天候魂导侦察机掠过海面缓缓行进,远处,已经可以见到白皑皑的雪线。<br />
<br />
“所长,即将抵达极北之地。”清脆的声音响起,一身白色军装的南澄向坐在副机长位置的蓝潇报告。<br />
<br />
他们是一支来自于斗罗联邦科学研究院天斗分院旗下的古魂兽研究所的科考队。自从斗罗联邦大约在九千年前完成了第一次太空之旅后,人类就开始了对太空不停的探索。不断的探索、不断的发现,让人类对宇宙的浩瀚有了越来越多的了解。<br />
<br />
伴随着人口的增多以及一些其他问题,人类开始尝试星际移民。经过数千年的不懈努力,终于在一千多年前完成了第一颗行星的移民。之后千余年来,人类已经完成了对七颗行星的移民计划,并且开发。<br />
<br />
自从万年前魂兽险些带来覆灭的灾难之后,被誉为斗罗联邦和平之母的那一代议长墨蓝宣布人类与魂兽和平共处。禁止一切对于魂兽的杀戮行为。<br />
<br />
联邦在进行第三颗行星殖民的时候,就将这颗星球赠与了魂兽,由当...
# 每段由4个空格符开头,<br />结尾
# 最后测试好的正则表达式:(?<= ).*(?=<br \/>|<\/div>)
OK,基本所需要的正则表达式完成。
最后的代码:
# -*- coding: utf-8 -*-
import urllib
import sys
import re
import os
# 爬虫自练习
# 获取网页内容
def getHtmlCode(url):
page = urllib.urlopen(url)
html = page.read()
# 将gbk转换成utf-8
str1 = html.decode('gbk')
str2 = str1.encode('utf-8')
return str2
# 获取章节目录
def getChapterUrl(url,id,file):
# 每一章节的链接,id为书籍编号
reg = r'/%s/[0-9]+.html(?=")' % id
# 章节目录
# reg1 = r'(?<=">)[0-9]{3}\b[^</.>]*(?=<)'
patt = re.compile(reg)
# 获取所有章节链接
lineStr = re.findall(patt,getHtmlCode(url))
for str in lineStr:
txtUrl = 'https://www.tianxiabachang.cn' + str
getText(txtUrl,file)
return
# 获取文本内容
def getText(url,file):
str = getHtmlCode(url)
# 匹配标题
titleReg = r'(?<=h1>).*(?=</h1)'
titlePatt = re.compile(titleReg)
title = re.findall(titlePatt,str)
print "写入[%s]中" % title[0]
file.write(title[0])
file.write("\n")
# 匹配内容
txtReg = r'(?<= ).*(?=<br \/>|<\/div>)'
txtPatt = re.compile(txtReg)
txt = re.findall(txtPatt,str)
for t in txt:
file.write(" " + t)
file.write("\n")
file.write("\n")
return
print u"登陆www.tianxiabachang.cn,搜索书籍"
print u'请输入书籍编号:',
id = raw_input()
if id:
reg = r'[0-9]_[0-9]{1,4}'
idPatt = re.compile(reg)
if re.match(idPatt,id):
url = 'https://www.tianxiabachang.cn/%s/' % id
# 获取书籍名
nameReg = r'(?<=h1>).*(?=<)'
namePatt = re.compile(nameReg)
print '获取书籍中。。。。'
names = re.findall(namePatt, getHtmlCode(url))
print '链接成功!'
os.chdir(r"D:\novel")
print "开始下载书籍《%s》" % names[0]
# 打开书籍名.txt
file = open( names[0].decode('utf-8') + '.txt', 'a')
# 写入
getChapterUrl(url,id,file)
file.close()
print "下载书籍成功!请查看"
os.chdir(r"D:\PythonTool\PythonSpace")
else:
print "编号出错"
大功告成,测试结果:
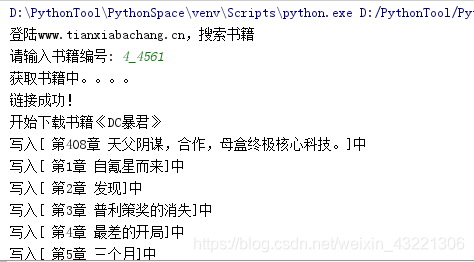
可爱的小说已经在等着我们了:
