什么是决策树?
如何构建决策树?
ID3
C4.5
CART
决策树的优缺点及改进
什么是决策树?
决策树是运用于分类的一种树结构,其本质是一颗由多个判断节点组成的树,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,而叶节点代表某个类或类的分布。
属于有监督学习
核心思想:
分类决策树的核心思想就是在一个数据集中找到一个最优特征,根据这个最优特征将数据集分为两个子数据集,然后递归上述操作,直到满足指定条件为止。
决策树的构建步骤:
1. 开始,所有记录看作一个节点
2. 遍历每个特征的每一种分裂方式,找到最好的分裂特征(分裂点)
3. 分裂成两个或多个节点
4. 对分裂后的节点分别继续执行2-3步,直到每个节点足够“纯”为止
如何评估分裂点的好坏?如果一个分裂点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分裂点。 具体实践中,到底选择哪个特征作为当前分裂特征,常用的有下面三种算法:
ID3:使用信息增益g(D,A)进行特征选择
C4.5:信息增益率 =g(D,A)/H(A)
CART:基尼系数一个特征的信息增益(或信息增益率,或基尼系数)越大,表明特征对样本的熵的减少能力更强,这个特征使得数据由不确定性到确定性的能力越强。
ID3:
ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。



ID3的缺陷:
突出的缺陷是信息增益的计算依赖于特征水平较多的特征,而属性取值最多的属性并不一定最优
它只能处理那些分类的特征,对于连续值特征毫无办法


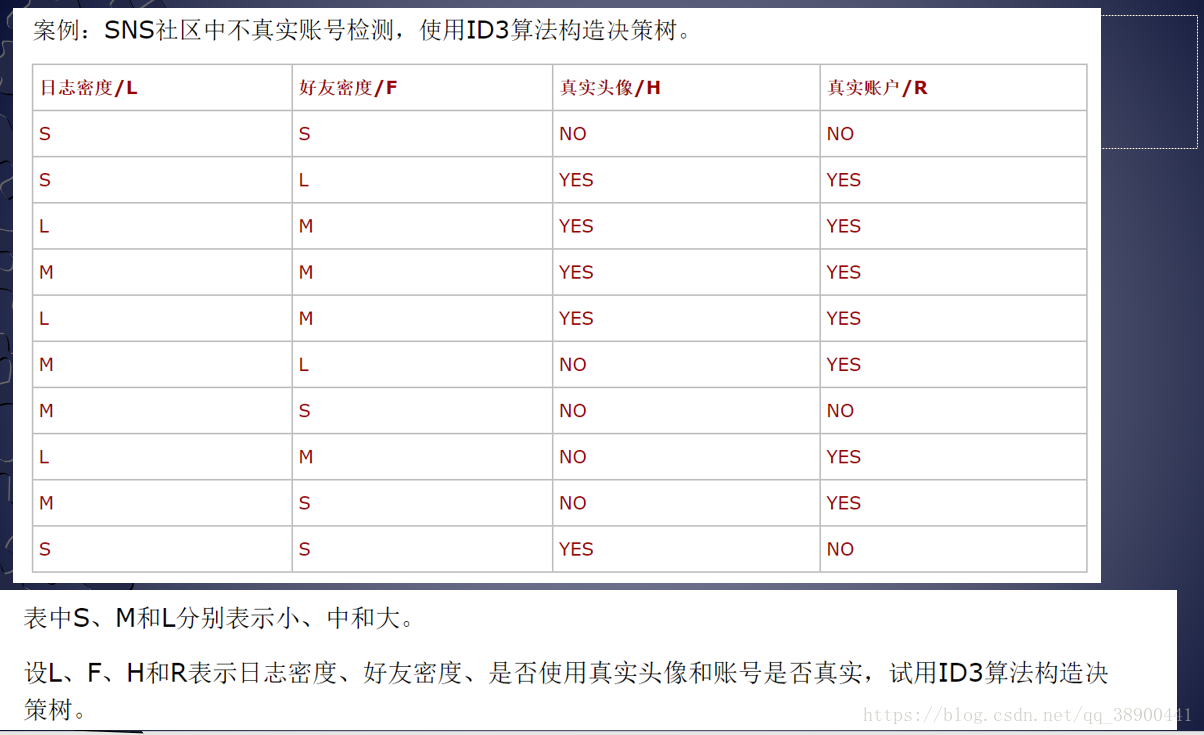
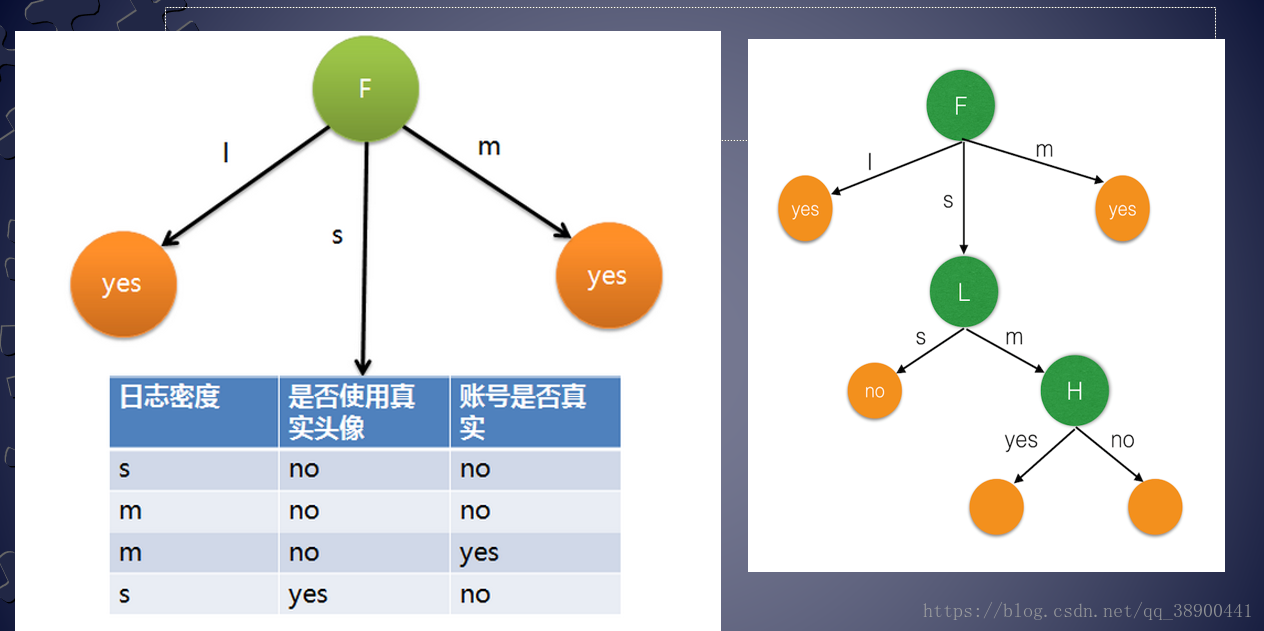
由上述计算结果可知“好友密度”在属性中具有最大的信息增益比,取“好友密度”为分割属性,引出一个分枝,样本按此划分。对引出的每一个分枝再用此分类法进行分类,再引出分枝。
某属性的信息增益除以分裂信息,消除了特征水平数量多少的影响,使得分裂属性的选择更加合理。

决策树的优点:
1)可以自学习。在学习过程中不需要使用者了解过多的背景知识,只需要对训练数据进行较好的标注,就能进行学习。 2)决策树模型可读性好,具有描述性,有助于人工分析; 3)效率高,决策树只需要一次构建,就可以反复使用,每一次预测的最大计算次数不超过决策树的深度。
存在问题:
决策树容易产生过拟合现象
比较好的解决方法:
随机森林
可参考ppt: https://download.csdn.net/download/qq_38900441/10714599