性能度量
根据任务需求,需要有不同的性能度量方式,常规度量方式如下:
| _ | 真 | 假 |
|---|---|---|
| 认为真 | true positive(TP) | false positive(FP) |
| 认为假 | false negative(FN) | true negative(TN) |

准确率:
精确率:
召回率:
PR曲线:
F1分数:
覆盖:
IoU:
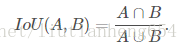
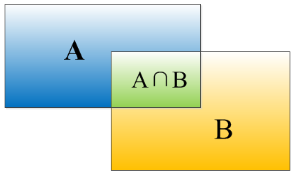
ROC:曲线是以假正率(FP_rate)和真正率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC
默认的基准模型
根据任务类型,选择默认的基准模型
序列一般就是LSTM和GRU,结构化一般就是卷积,其中激活函数一般是ReLU或其变种。
优化算法一般使用Adam,
初始一般不使用批标准化,如果优化出现问题再使用。
一般包含温和正则,如提前终止earlystop和dropout。dropout和batchnormalize一般不同时使用,会有冲突。
如果已有近似领域的研究,可以使用迁移学习。
项目开始时考虑是否使用无监督学习。
觉得是否收集更多参数
首先确定训练集上的性能是否可接受,可接受再增加模型规模调整超参数来看训练效果,如果增大模型和调优效果不佳,可能是数据质量问题,可能需要重新收集训练集。如果测试集性能比训练集差很多,那主要考虑多收集数据。考虑收集数据的代价以及需要多少数据,可通过绘制数据量和泛化曲线之间的关系来得到。
选择超参数
手动设置:
当只有实践调整一个超参数时,首选学习率。一般是u型曲线。
调整其他参数时,需同时监控训练误差和测试误差,判断是否过拟合或欠拟合。
训练集误差大于测试集:增加模型能力。
训练集误差小于测试集:添加正则化
网格搜索:
对数尺度中搜索,不断缩小搜索范围。效率较低
随机搜索:
无需离散化超参数值,且效率较高
贝叶斯超参数优化:
TPE:
SMAC:
调试策略
可视化计算值模型的行为;
可视化最严重的错误:在最容易出错的地方着手修改。通过矩阵列出出错项。
根据训练和测试误差检测:通过看两者的曲线来判断过拟合或者欠拟合。
拟合极小的数据集:先从小数据集开始搞。
比较反向传播导数和数值导数:看梯度是否正常,反向传播导数和数值导数差值如何。
监控激活函数值和梯度直方图;