我们知道sparkSQL跟hive是兼容的,他支持hive的元数据库,sql语法,多种类型的UDF,
而且还支持hive的序列化和反序列化方式,意思就是hive写的自定义函数,spark拿过来就能用。

最重要的就是MetaStore元数据库,以后一旦我们使用hive的MetaStore,那么他以前建的表我们就可以使用了。
那么我们写的SQL就可以直接从hive的仓库中查询数据了。
所谓hive的仓库其实就是一个元数据库和hdfs
元数据库中指定了有哪些表,表中有哪些字段。每个字段叫什么名字,分别是什么类型。还有这张表对应的存放在hdfs的哪个目录下。以后我们执行sparksql的时候就可以根据元数据信息到hdfs中找对应的数据了。
元数据库中存放的是描述信息,hdfs中存放的是真正需要计算的信息。
接下来我们来整合hive,其实整合hive就是整合hive的元数据库,hive的sql,UDF,还有序列化
假设我们以前用过hive或者没用过hive,我们都可以将他整合进来。如果有的话就直接拿过来用,没有的话就新建一个。
我们之前使用hive的时候,如果配置了mysql的元数据库,一执行任务就会在mysql中创建。
所以当我们使用sparkSQL的时候,如果还没有创建元数据库,sparkSQL就会帮我们创建。
--------------------------------------------------------------------------------------------------------------------------------------
接下来我们就来整合hive,我们知道,玩hive的话,首先要启动hdfs,所以我们需要先将需要的环境先启动起来。
接下来的步骤:
1.安装hive(可选),我们可以选择安装或者不安装hive,这时候有人就会问了,不安装hive怎么将spark整合hive?
其实我们用hive只是用的hive的元数据库,我们都不用他的jar包。如果这个元数据库以前有,那更好,我们可以直接拿过来用。
如果hive没有元数据库怎么办?我们可以让spark帮我们创建一个。
sparkSQL在第一次启动的时候他会找元数据库。会在我们指定的mysql的位置看看有没有我们指定的相应的元数据库。
有的话就用原来的,没有的话就创建一个。
其实sparkSQL也会创建一个元数据库。和hive创建的是一样的。
2.在mysql中创建用户并赋予权限:
create user 'root'@'%' identified by '123456';
grant all privileges on hivedb.* to 'root'@'%';
flush privileges;第二步完成之后,前期准备就已经准备好了。
3.将配置好的hive-site.xml放入$SPARK-HOME/conf目录下
注意:整合hive他唯一需要的其实就是一个hive配置文件。
那么这个文件我们放到什么地方呢?是放到所有机器还是放到一台机器?
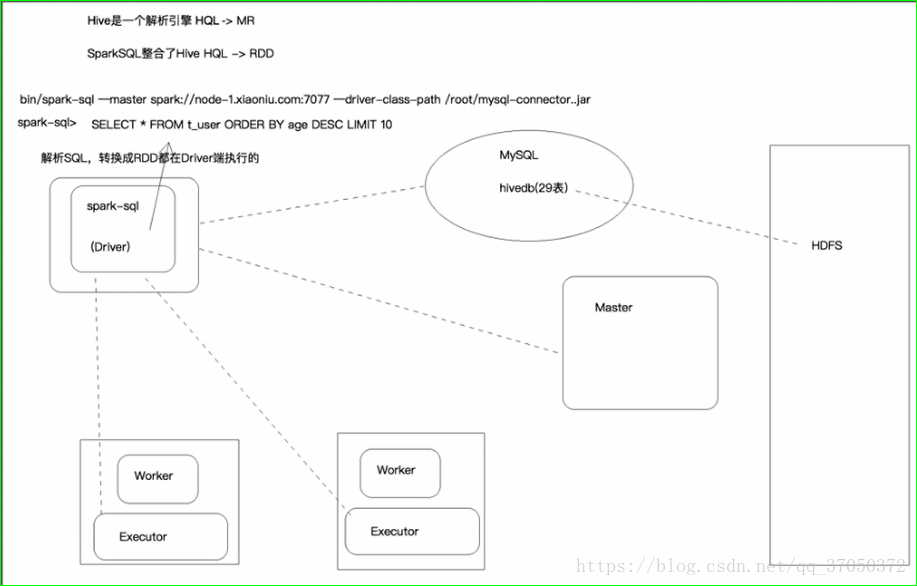
以前我们用hiveshell其实他只要安装一台机器就可以了。他就是一个sql解析引擎,他是一个客户端,他会把我们的sql解析成MapReduce。通过客户端提交到集群上。
sparkSQL也是一样的,他只要安装一台就可以了。他可以将我们写的sql转换成RDD然后再把它提交到集群。
那么这个sparkSQL也相当于是一个客户端。
4.将hadoop的core-site.xml和hdfs-site.xml都放入spark的conf目录下
这个时候问题就来了,我们为什么需要这两个配置文件?
因为以后我们执行hivesql的时候他需要将hiveSQL转换成RDD在集群当中执行。那么以后他需要在hdfs当中读取数据。
要读取数据就需要知道namenode在哪里。而namenode的一些信息就放在core-site.xml当中
如果我们配置的是高可用集群的话,那么hdfs-site.xml当中也有namenode的信息。
5.然后启动hdfs,接下来启动spark
6.执行spark-sql并指定mysql连接驱动位置
接下来我们想让他帮我们创建一个元数据库,我们第一次不启动sparkshell,
我们启动sparksql
bin/spark-sql \
--master spark://marshal:7077 \
--driver-class-path /root/mysql-connector-java-5.1.21-bin.jar这里的命令sparkSQL需要指定master的地址。
指定driver-class-path是因为sparkSQL需要连接元数据库,这个时候就用到了mysql的连接驱动。
其实这里我们这样启动,是会报错的,因为它还要找hadoop的配置文件。而我们把那些配置文件放入conf目录,它也是找不到的。这个时候我们就需要在etc/profile中配置一下HADOOP_CONF_DIR:
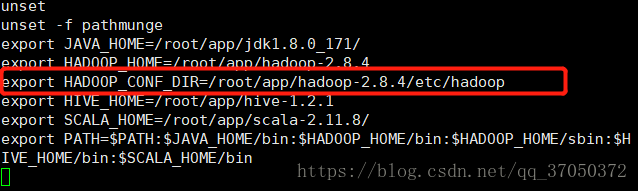
配置完这个之后启动sparkSQL的时候就可以知道hdfs所有的配置文件了。
然后我们将原来的元数据库删掉。
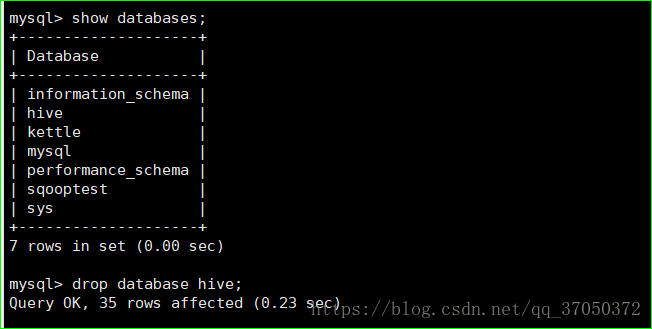
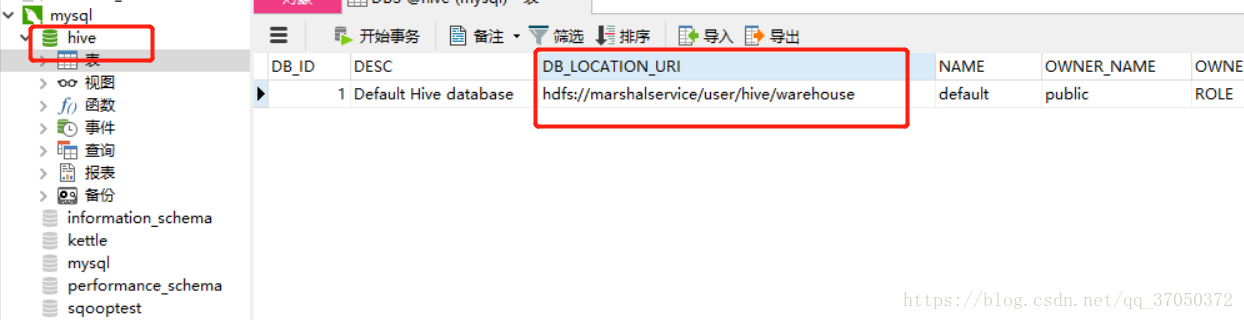
之后执行命令就可以看到数据库中生成了hive的元数据库,而且DBs表中DB_LOCATION_URI应该是hdfs的路径而不是本地。
这个参数说明了hive的数据库在hdfs中的位置
成功截图:
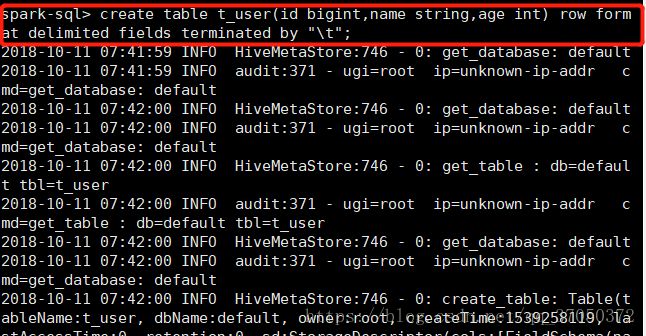
接下来我们尝试在sparkSQL中创建一张表
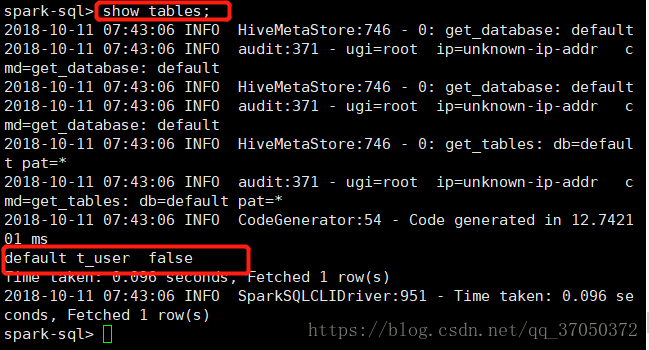
我们创建的表在数据库中的TBL表中即可查看:

所以我们发现,现在我们在sparkSQL中就可以写hive的语句了。
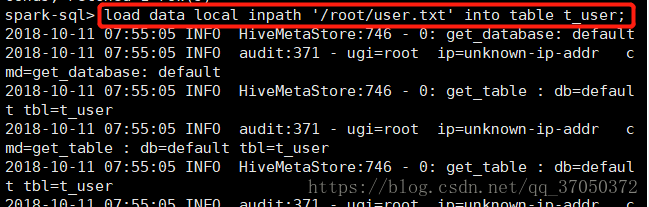
于是我们尝试使用load将数据写入hdfs上再通过语句查询出来,首先我们来造一下数据:

然后加载数据到hdfs:
然后我们在hdfs中查看一下:

接下来我们查询一下:
这个时候有人就会产生疑问,我们现在使用的这些语句和Hive一模一样啊
包括我们刚才创建hive的表,load数据的语法和hive一模一样啊。
那么我们使用sparksql和hive有什么区别呢?
其实是执行引擎换了,原来我们的执行引擎是用mapreduce运行的。而现在使用的是spark,底层是RDD。
执行结果如下:

接着我们可以写程序去访问,在写程序之前,我们需要将配置文件放入resources目录:
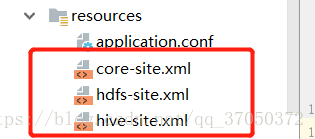
代码如下:
package com.test.SparkSQL
import org.apache.spark.sql.SparkSession
object SparkSQLHive {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("SparkSQLHive")
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
spark.sql("select * from t_user").show()
}
}执行结果如下:

sparksql还可以整合hive的自定义函数:
我们先来写一个自定义函数:
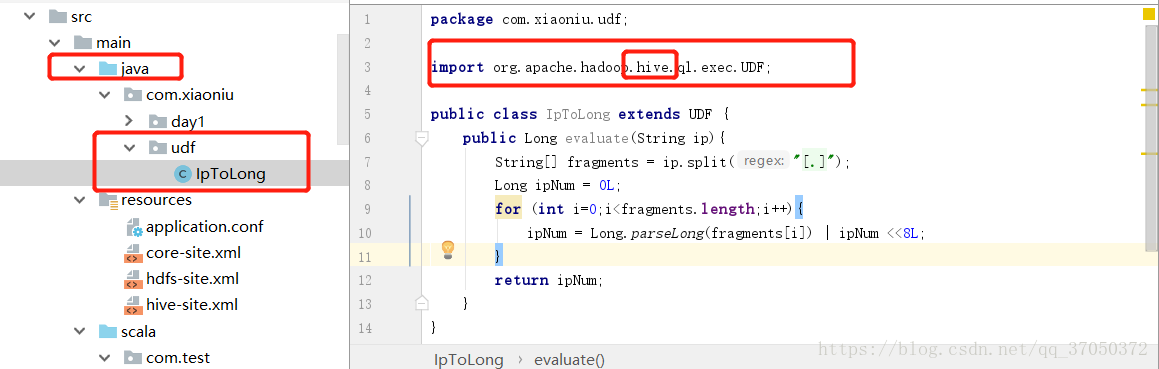
然后造数据,并加载到hive表中
首先创建表:

然后造数据:

接着加载数据:

然后在代码中使用自定义函数:
代码如下:
package com.test.SparkSQL
import org.apache.spark.sql.SparkSession
object SparkSQLHive {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("SparkSQLHive")
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
// spark.sql("select * from t_user").show()
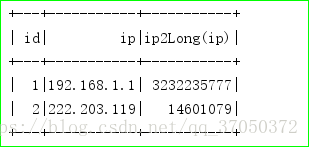
spark.sql("create temporary function ip2Long as 'com.xiaoniu.udf.IpToLong'")
spark.sql("select id,ip,ip2Long(ip) from access_log").show()
}
}运行结果如下: