mysql的john用法总结
左”的笛卡尔积和“右”的笛卡尔积
根据mysql join 连接的方式我把它归为两类,“左”的笛卡尔积和“右”的笛卡尔积。
假设有两个表A和B,分别有m行和n行
1、“左”的笛卡尔积就是我们通常的笛卡尔积,也就A的所有元素依次连接B的第一个元素,然后A的所有元素依次连接B的第二个元素,依此类推,这样最终得到的表就有m*n行;“左”的笛卡尔积有Inner join、Left join、Cross join(除了right join外的都是)
下面具体说明,我们先创建两个表
create table tbl_name (ID int,mSize varchar(100));
insert into tbl_name values(1,'tiny,small,big');
insert into tbl_name values(2,'small,medium');
insert into tbl_name values(3,'tiny,big');
结果如下tbl_name :
| ID | mSize |
|---|---|
| 1 | tiny,small,big |
| 2 | small,medium |
| 3 | tiny,big |
第二个表
create table incre_table (AutoIncreID int);
insert into incre_table values(1);
insert into incre_table values(2);
insert into incre_table values(3);
如果如下incre_table :
| AutoIncreID |
|---|
| 1 |
| 2 |
| 3 |
先看Inner join
select * from
tbl_name a
INNER JOIN
incre_table b
运行结果如下:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 3 |
再看Left join
select * from
tbl_name a
LEFT JOIN
incre_table b
on 1=1
说明,left join和right join都必须有on条件,其他连接可以选择不写on条件,这里用on 1=1,使所有结果满足要求,结果如下:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 3 |
再看Cross join
select * from
tbl_name a
CROSS JOIN
incre_table b
运行结果如下:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 3 |
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 1 | tiny,small,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 1 |
| 2 | small,medium | 2 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 1 |
| 3 | tiny,big | 2 |
| 3 | tiny,big | 3 |
筛选条件
on 后面的条件是从上面的结果中筛选符合条件的结果。
一般情况下我们都会用A表中的某个字段与B表中相同的字段作为筛选条件。
这里我们比较特殊,用on b.AutoIncreID <=(length(a.mSize) -length(replace(a.mSize,’,’,’’))+1)来筛选mSize中单词个数不小于AutoIncreID的结果,下面逐一查看。
select * from
tbl_name a
INNER JOIN
incre_table b
on (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
select * from
tbl_name a
LEFT JOIN
incre_table b
on (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
select * from
tbl_name a
CROSS JOIN
incre_table b
on (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果也是一样的
select * from
tbl_name a
RIGHT JOIN
incre_table b
on (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 1 | tiny,small,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 1 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 1 |
| 3 | tiny,big | 2 |
以上是从mysql运行结果来看逻辑过程的,但具体在实现的时候是不是按这个过程来执行,我没有做进一步探讨,因为这里涉及数据库底层实现,内存优化这些,有兴趣的话可以进一步研究。
最小规模
都是以某一共同的字段作为on成立的条件
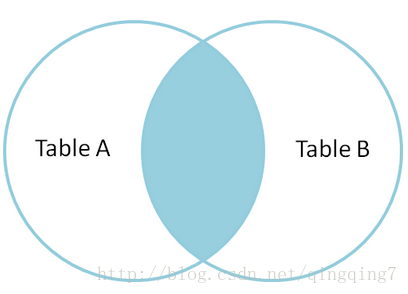
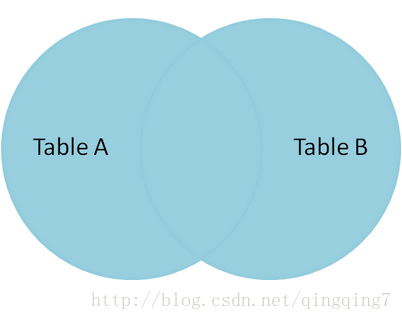
Inner Join: 得到的结果行数可以小于被连接的两个两个表的行数,关系如下所示
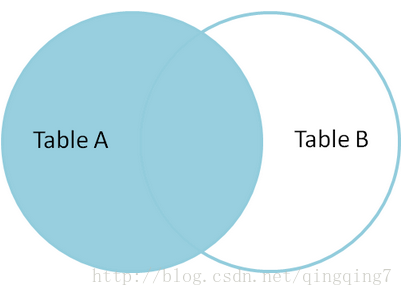
Left Join: 左边的表各行得到保留,如果匹配不到右边,则右侧为NULL,关系如下
cross Join: 在mysq中与Inner join一致
right Join: 与左连接相反,匹配不到左侧,则左侧为NULL
full join: mysql中没有全连接,通过left join Union right join实现,关系如下
mysql的UNION及UNION ALL用法总结
UNION: 用于合并两个或多个select语句的结果集,并消去重复的值;
注意:
1、合并后的结果集的列名总为第一个select语句结果的列名;
2、被合并的select子集必须有相同的列数,各列的数据类型列的类型可以不一样但要相似,列的顺序必须一致
SELECT column_name FROM table1
UNION
SELECT column_name FROM table2
UNION ALL: 不去除重复值
SELECT column_name FROM table1
UNION ALL
SELECT column_name FROM table2
mysql实现交集和差集
mysql中不能直接实现该功能,需要通过组合的方式来达到该效果。
交集:
思路就是将两张表union起来,然后进行计数,由于同时出现在两张表中才是交集的元素,该元素在计数时个数必然大于1。
SELECT *,COUNT(*) as inter_flag FROM
(
SELECT name1,name2 from table_1
UNION
SELECT name1,name2 from table_2
) as table_temp
GROUP BY name1,name2
HAVING inter_flag>1
差集:
思路就是将两张表left join,当某一行数据在左表中且在右表中时,左连接后的大表的右半部分不为NULL,去掉这些不为NULL的行即可。
SELECT table_temp1.* FROM
(
SELECT * from table_1
) as table_temp1
LEFT JOIN
(
SELECT * from table_2
) as table_temp2
ON table_temp1.name1=table_temp2.name1
WHERE table_temp2.name1 IS NOT NULL
上面是以字段name1作为某一行是否同时在两个表中的标志,实际上可能是多个字段要同时相等才表示某一行同时在两个表中,可以在where语句中加入多个条件来实现。