本文旨在抓取电影的评论,包括电影评论者的昵称、来自的城市、评论内容、评分以及评论的时间,并将这些内容抓取下来保存到txt文本里面,并对其中的评论内容去重,并生成词云。
导入库
from urllib.error import HTTPError,URLError---异常处理
from collections import defaultdict---创建列表
from wordcloud import WordCloud---词云的创建
import json---数据处理
import requests---抓取网页
import time---休眠
from os import path---找出项目的路径
from PIL import Image---导入要生成词云的图片
import numpy as np---数据转换
import jieba---分词分割
爬取的网页
从网页源码中看到这些评论的数据并没有出现,也仅仅是看到10条评论信息,其他的看不多,这是猫眼电影的一大反爬防护,通过netword去分析也没有找到,最终通过切换为移动端去查看网页才发现了数据的接口,只要把数据的接口给下载了,再去解析 接口文件里面的数据就可以找到我们想要的数据了。
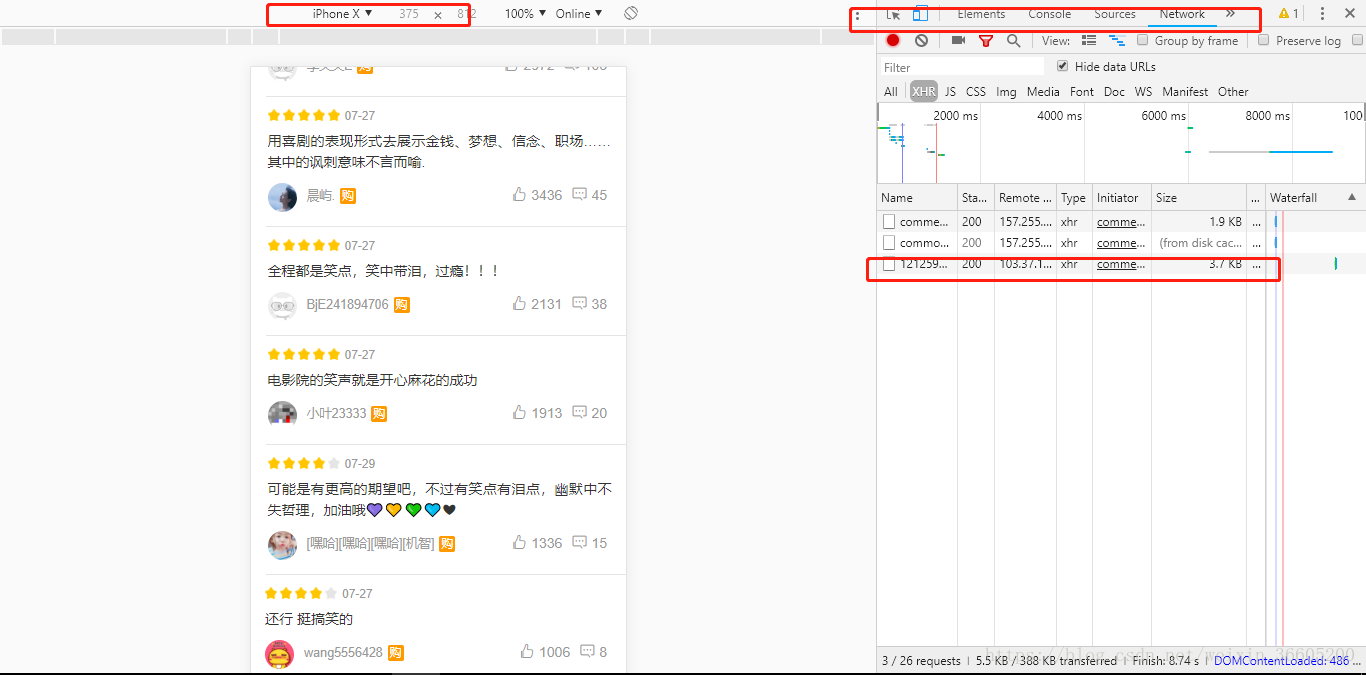
可以发现每次加载评论数据的时候都会出现一个json接口,http://m.maoyan.com/mmdb/comments/movie/1212592.json?_v_=yes&offset=0&startTime=0 (第一次评论数据加载),且最多加载到1000页。每次只需要替换offset参数的值即可得到下一页的评论数据
开始提取数据
利用requests库的get方法来下载数据
# 打开网页
def open_network(tomato_url):
# 设置请求头,防止无法爬取下去(可以查看自己的浏览器里面的请求头)
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
try:
# get方法下载数据
html=requests.get(tomato_url,headers=headers)
except (HTTPError,URLError) as hu:
print(hu)
return None
else:
return html.content
# 获取网页的内容
def get_page_content(tomato_url,cmts):
message=[]
time.sleep(1)
html_content=open_network(tomato_url)
if html_content != None:
html_content=html_content.decode('utf-8')
# 转换为Python能处理的数据
jsonObj=json.loads(html_content)
if cmts in jsonObj:
# 评论信息主要存在key为cmts的键里面
data_cmts=jsonObj[cmts]
for data_cmt in data_cmts:
try:
# 数据添加到一个列表中
message.append({
# 昵称、城市、评论内容、评分、日期
'nickName':data_cmt['nickName'],
'city':data_cmt['cityName'],
'content':data_cmt['content'],
'star':data_cmt['score'],
'date':data_cmt['time']
}
)
except KeyError as ke:
print(ke)
continue
else:
print('不存在这个key')
return message数据存储
写进txt文件里面,在打开一个文件时,需要设置好编码格式防止乱码。
# 热评写进txt文件
def create_content_txt(datas,fileName,i=0):
with open('评论文件/西虹市首富'+fileName+str(i)+'.txt','w',encoding='utf-8')as f:
for data in datas:
if '\n' in data['content']:
data['content']=data['content'].replace('\n','')
f.write('昵称:'+data['nickName']+',城市:'+data['city']+',评论:'+data['content']+',星级:'+str(data['star'])+',日期:'+str(data['date'])+'\n')
print('文件'+str(i)+'写入成功!')评论内容去重并存储
由于评论的内容存在重复性,所以把重复的内容去除,并把新的评论内容存储到txt文件里面去,方便给词云生成提供数据。利用set集合的无重复性,每次把数据存到有del_datas=set()的全局变量里面去,可以实现去重
# 评论去重
def delete_data(datas):
global del_datas
for data in datas:
del_datas.add(data['content'])词云生成
# 生成词云
def create_wordCloud():
# 该程序的路径
d=path.dirname(__file__)
# 读取词云文件的内容
text=open(path.join(d,'wordcloud.txt'),encoding='utf-8').read()
# 进行分词
text=jieba.cut(text)
text=''.join(text)
# 将PIL image图片转化为数组
tomato=np.array(Image.open(path.join(d,'xin.png')))
# 指定中文字体文件的路径、背景颜色、图片的宽高、最大词云数目、指定生成形状
wc = WordCloud(font_path="C:/Windows/Fonts/simsun.ttc",background_color="white",width=627,height=834, max_words=2000, mask=tomato)
# 生成词云
wc.generate(text)
#保存到本地
wc.to_file(path.join(d, "shen_teng.png"))程序入口
# 数据写进多个文件中
def write_data():
i=0
global cmts
while i<=1000:
data_cmts=get_page_content('http://m.maoyan.com/mmdb/comments/movie/1212592.json?_v_=yes&offset='+str(i)+'&startTime=0','cmts')
# 文件写入
create_content_txt(data_cmts,'短评',i)
# 去重
delete_data(data_cmts)
i+=1
# 去重写进文件,用于生成词云
with open('wordcloud.txt','w',encoding='utf-8')as f:
for del_data in del_datas:
f.write(del_data+'\n')
# 词云
create_wordCloud()效果

源码链接:https://pan.baidu.com/s/1xwxzehI4CzeMcL-YiKXFxg 密码:qcdl