前言
眼睛看惯了文字,累了 ,转而用耳朵去聆听这世界。喜马拉雅FM,这里有我们想听的,用爬虫去抓取我们想要的音频!这次要抓取的是关于旅游篇当中的玩转西藏【旅游攻略】,去感受高原的风土人情,废话并不多说啦。
环境
win10+python3.7+sublime text
导包
import requests---->网页的请求和数据抓取
import json--->数据格式转换
from multiprocessing.pool import pool---->线程池的使用
网页分析
https://www.ximalaya.com/lvyou/5656303/,该网址对应上面图片的,是下面是我们要查看内容的地址,我们主要是把这些音频全部抓取下来,然后保存在本地,但是我们并不从该地址去抓取有关音频的src,而是直接在旅游篇目上点击播放玩转西藏【旅行攻略】,在这个过程上面去用浏览器的开发者工具去抓包来获取相关信息的一个json数据,tracksAudioPlay字段包含我们想要所有音频数据,下面就需要编码实现就行了。

实现过程
- 网页获取
定义一个类,在这个类中初始化请求头和请求的资源url,再使用requests对象里面的get()方法,因为该网页的请求方式是get方式,然后判断相应的状态码,若是200表示请求成功,则把获取到的内容进行解码。
def __init__(self,num,id):
self.headers={
'Host': 'www.ximalaya.com',
'Referer': 'https://www.ximalaya.com/lvyou/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
# albumId=5656303是该收听节目的id,页码:pageNum,一页多少条:pageSize=30
self.url='https://www.ximalaya.com/revision/play/album?albumId='+str(id)+'&pageNum='+str(num)+'&pageSize=30'
def get_content(self):
response=requests.get(url=self.url,headers=self.headers)
# 判断响应的状态码
if response.status_code==200:
# 解码
return response.content.decode()- 解析数据
把获取到字符串数据转换为字典格式,方便去获取里面具体的内容,并获取到相关的音频数据
def get_tracks(self,content):
try:
if content:
# 字符串转换为字典:json.loads()
# print(json.loads(content)['data']['tracksAudioPlay']),测试输出
return json.loads(content)['data']['tracksAudioPlay']
except Exception as e:
print(e)
pass- 下载音频
根据音频的连接src来重新去请求资源,并下载到本地,其中trackName字段的数据作为每一个音频的名称,并对字符串进行拼接,把扩展名改为.m4a的格式,而且在Windows系统中文件的命名不能存在一些特殊的字符串,比如|等的特殊字符,所以需要对trackName字段的字符串数据进行特殊字符的替换。
def down_from_src(self,src,trackName):
response=requests.get(url=src)
if response.status_code==200:
# 去除特殊符号,因为windows的文件不能出现这些特殊字符
trackName=trackName.replace('|','').replace('?','').replace(':','').replace(' ','')
with open(trackName+'.m4a','wb') as f:
f.write(response.content)- 程序入口
需要对url进行判断,因为针对于vip的音频来讲,这里的url是空的,不存在,所以就无法直接去抓取数据了。
# 程序主入口
def main(i):
sipder=xizangSipder(i,5656303)
for tracksAudioPlay in sipder.get_tracks(sipder.get_content()):
try:
src,trackName=tracksAudioPlay['src'],tracksAudioPlay['trackName']
if src:
sipder.down_from_src(src,trackName)
except Exception as e:
print(e)
pass- 开启线程池
if __name__=='__main__':
# 创建线程池
pool=Pool(5)
# 第一个参数是函数,第二个参数是一个迭代器,把迭代器的数字作为参数传进去
pool.map(main,[x for x in range(1,7)])
# 关闭线程池
pool.close()
# 主线程阻塞等待子线程的退出
pool.join()
实现效果
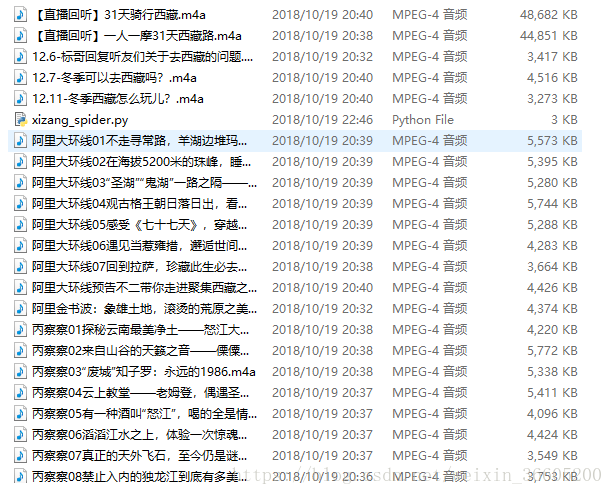
总结:程序相对简单,只要知道资源的连接在哪里,就能通过资源url来抓取,通过线程池来提高了程序的效率。vip版音频下载没有实现,下一步加油实现(不过这样破解别人的vip是犯法的,需谨慎!)
项目链接:链接:https://pan.baidu.com/s/1hEQAzZWYWn5CEO1ez_Ed3Q 提取码:b78t