一、分析音频下载相关链接地址
1. 分析专辑音频列表页面
在 PC端用 Chrome 浏览器中打开 喜马拉雅 网站,打开 Chrome开发者工具,随意打开一个音频专辑页面,Chrome开发者工具中返回如下图结果:
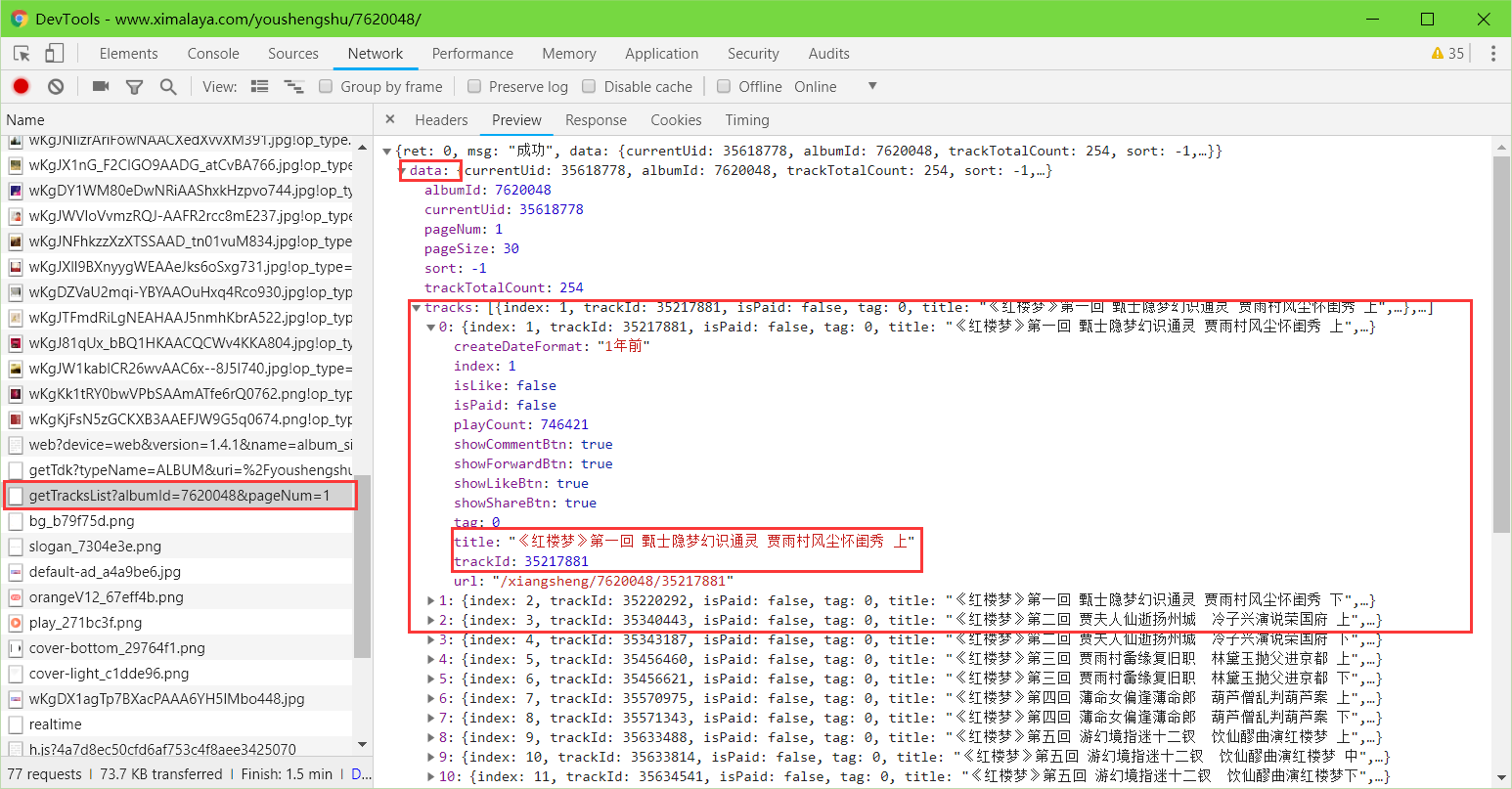
经过分析专辑音频列表地址为
https://www.ximalaya.com/revision/album/getTracksList?albumId=12378382&pageNum=1
其中:
- albumId 专辑ID
- pageNum 页号
返回的页面内容是 json 格式,相比于 html 源码,json 还是很容易处理的,下载音频只需要用到如下参数:
- tracks 音频信息列表
- tracks -> title 音频标题
- tracks -> trackId 音频ID
2. 分析音频下载链接地址
随意播放一个音频,在Chrome开发者工具中返回如下图结果:
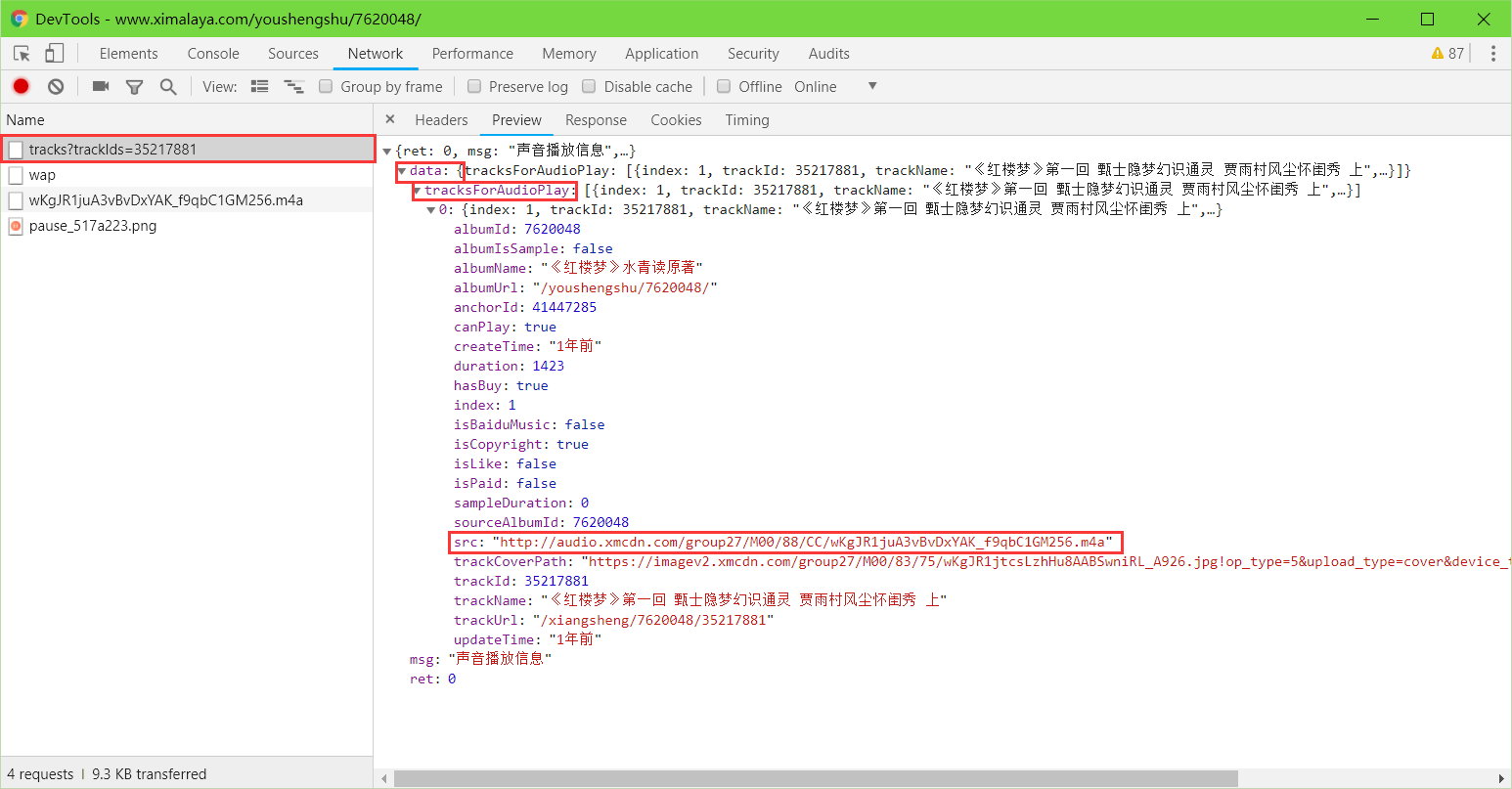
经过分析专辑音频下载链接为
其中
- trackIds 音频ID
返回的页面内容也是 JSON 格式,其中 tracksForAudioPlay 字段包含了音频的相关信息,其 src 就是音频下载地址。
- src 音频下载链接
- trackName 音频名称
- trackId 音频ID
二、编写代码
1. 安装相关依赖模块
本程序使用 requests 访问 web 页面,因此需要安装 requests 模块
pip install requests
2. 编写代码
提取专辑内的音频列表信息,如下:

提取音频下载地址,如下:

下载音频文件,如下:

完整源码:
