一般当你的爬虫程序爬起来以后,出现这种情况就是因为你要爬取的网站对爬虫进行了限制。
真小气!!!
直接用火狐浏览器去查看他的User-Agent就可以了
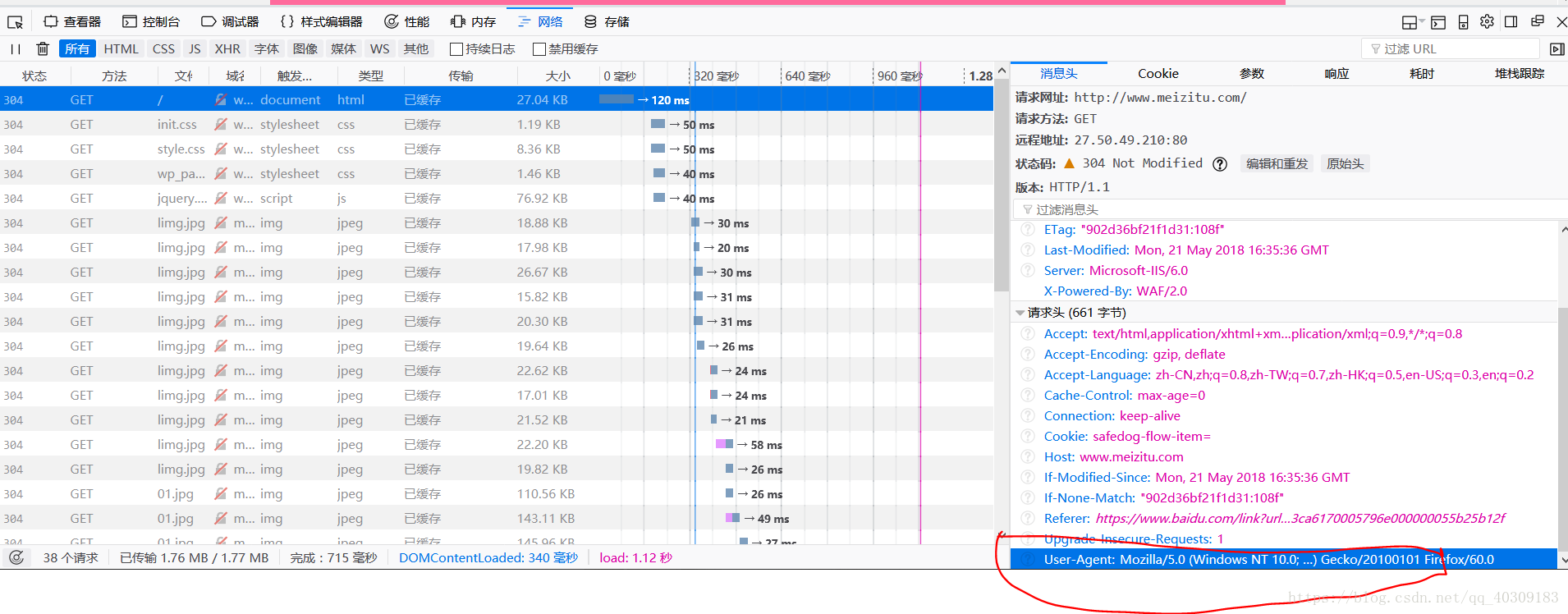
然后:
def getHtml(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
page1=urllib.request.Request(url,headers=headers)
page=urllib.request.urlopen(page1)
html=page.read()
这样就可以了