错误原因:主要是由于该网站禁止爬虫导致的,可以在请求加上头信息,伪装成浏览器访问User-Agent。
新增user-agent信息:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
req = request.Request(Spider.url, headers=Spider.headers)
# 获取到的html的信息
htmls = request.urlopen(req).read()
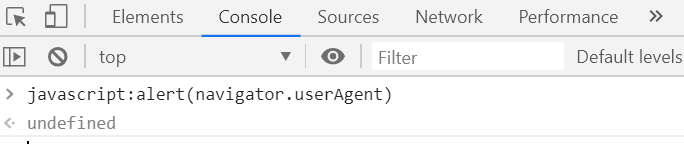
谷歌的user-agent查看方法:按F12打开调试工具,在控制台写:javascript:alert(navigator.userAgent),user-agent信息就会弹出