一、n-gram模型概念
n-gram模型也称为n-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面n-1个词相关,可以表示为:
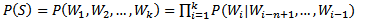
当n取1、2、3时,n-gram模型分别称为unigram、bigram和trigram语言模型。n-gram模型的参数就是条件概率P(Wi|Wi-n+1,...,Wi-1)。假设词表的大小为100,000,那么n-gram模型的参数数量为100,000n。n越大,模型越准确,也越复杂,需要的计算量越大。最常用的是bigram,其次是unigram和trigram,n取≥4的情况较少。
二、n-gram模型的参数估计
模型的参数估计也称为模型的训练,n-gram模型的参数的估计表达式如下:

一般采用最大似然估计(Maximum Likelihood Estimation,MLE)的方法对模型的参数进行估计:

举个例子来说明一下,IBM Brown利用366M英语语料训练trigram,结果在测试语料中,有14.7%的trigram和2.2%的bigram在训练中没有出现;根据博士期间所在的实验室统计结果,利用500万字人民日报训练bigram模型,用150万字人民日报作为测试语料,结果有23.12%的bigram没有出现。这种问题也被称为数据稀疏(Data Sparseness),解决数据稀疏问题可以通过数据平滑(Data Smoothing)技术来解决。
三、平滑算法
数据平滑是对频率为0的n元对进行估计,典型的平滑算法有加法平滑、Good-Turing平滑、Katz平滑、插值平滑等。
3.1 加法平滑
3.1.1 Laplace法则(加1平滑)

通过给每个n元组都加1,实现将一小部分概率转移到未知事件上,公式如下:
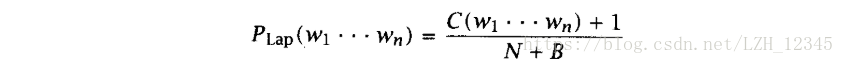


3.2 Good-Turing估计







