3 N-gram和数据平滑
3.1 语言建模
语言建模:对于一个服从某个未知概率分布P的语言L,根据给定的语言样本估计P的过程被称作语言建模。
语言建模技术首先在语音识别研究中提出,后来陆续用到OCR、,手写体识别,机器翻译,信息检索等领域。
在语音识别中,如果识别结果有多个,则可以根据语言模型计算每个识别结果的可能性,然后挑选一个可能性 较大的识别结果。
对于给定句子s= w1w2w3…,使用链式规则计算P(s)。
P(s)=P(w1)P(w2|w1)P(w3|w2w1)…
3.2 n-gram
由于语言的规律性,句子中前面出现的词 对后面可能出现的词有很强的预示作用。
n-gram:为了便于计算,一般只考虑前面n-1个词构成的历史即P(wi|wi-n+1…wi-1)。
n较大时:提供了更多的语境信息,语境更具区别性,但是参数个数多,计算代价大,训练语料需要多,参数估计不可靠。
n较小时:语境信息少,不具区别性。但是参数个数少,计算代价小,训练语料无需太多,参数估计可靠。
n=1:p(wi) 若语言中有20000个词,则需要估计20000个参数。
n=1:p(wi|wi-1) 若语言中有20000个词,则需要估计20000的平方个参数。
n=3:p(wi|wi-2wi-1) 若语言中有20000个词,则需要估计20000的立方个参数
建立过程:
1.数据准备:确定训练语料,对语料进行tokenization或切分,增加作为句子边界。
2.参数估计:利用训练语料,估计模型参数。
最大似然估计:选择一组参数,使得训练样本的概率最大。选择能使训练样本取得最大概率值的分布作为总体分布。
句子的概率表现为若干bigram参数的乘积,若句子 太长,计算时,会引起下溢(underflow),可以采用 取对数并相加的方式。
由于训练样本不足而导致所估计的分布不可靠的问题,称为数据稀疏问题。
在NLP领域中,数据稀疏问题永远存在,不太可能有一个足够大的训练语料,因为语言中的大部分词都属于低频词。
3.3 Zipf定律
Zipf 定律描述了词频以及词在词频表中的位置之间的关系。
针对某个语料库,若某个词w的词频是f,并且该词在词频表中的序号为r(即w是所统计的语料中第r常用词),则
f × r = k (k是一个常数),若wi在词频表中排名50,wj在词频表中排名150,则wi 的出现频率大约是wj的频率的3倍。(有例外前3个最常用的词,r = 100 时。)对汉语而言也大致成立。
Zipf定律告诉我们,语言中只有很少的常用词,语言中大部分词都是低频词(不常用的词)。
大部分词是低频词,3993 (50%) 词(word types)仅仅出现了一次。
常用词极为常用,前100个高频词占了整个文本的51% (word tokens)。
3.4 数据稀疏问题
用150万词的训练语料训练trigram模型,同样来源的测试语料中有23%的trigram没有在训练语料中出现过。
对于语言而言,由于数据稀疏的存在,MLE不是一种很好的参数估计办法。
解决办法: 平滑技术,把在训练样本中出现过的事件的概率适当减小 ,把减小得到的概率密度分配给训练语料中没有出现过的事件,这个过程有时也称为discounting(减值)。
3.4.1 Add-one平滑
Add-one平滑:规定任何一个n-gram在训练语料至少出现一次(即规定没有出现过的n-gram在训练语料中出现了一次)。
P(w1w2w3…)=(C(w1w2w3…)+1)/(N+V)
N: 训练语料中所有的n-gram的数量(token)
V: 所有的可能的不同的n-gram的数量(type)
没有出现过的n-gram的概率不再是0,而是一个大于0的较小的概率值。
但由于未出现n-gram数量太多,平滑后,所有未出现的n-gram占据了整个概率分布中的很大的比例。
因此,Add-one给训练语料中没有出现过的n-gram分配了太多的概率空间。
此外,认为所有未出现的n-gram概率相同,是否合理?,出现在训练语料中的那些n-gram,都增加同样的频度值,是否公平?
3.4.2 Add-delta平滑
Add-delta 平滑:不是加 1,而是加一个小于1的正数 λ,通常λ等于0.5,效果比Add-one好,但是仍然不理想。
P(w1w2w3…)=(C(w1w2w3…)+λ)/(N+λV)
留存估计:把训练语料分为训练语料和留存语料。
训练语料用于初试的频率估计。
留存语料用于改善最初的频率估计。
如果训练语料不多,可以使用删除估计。
删除估计:分为两个部分,双向交叉验证(训练和留存交换)。
3.4.3 Good-Turing平滑
Good-Turing平滑:利用高频率n-gram的频率调整低频的n-gram的频率。
分配给所有未出现的n-gram的概率空间。
在估计频度为r的 n-gram的概率pr时,如果数据集中没有频度为r+1的n-gram怎么办?此时, Nr+1=0导致pr=0。
解决办法:对Nr进行平滑,S®是Nr的平滑值。
如何选择S()?
3.4.4 组合估计
组合估计:到目前为止,所有未出现的 n-gram 概率估计值均相等。但是实际上,并不是这样。
判断依据:unigram model数据稀疏问题比bigram model小,bigram model数据稀疏问题比trigram model小。
高阶n-gram的概率估计可以求助于低阶n-gram的 概率估计值。
因此可以把不同阶的n-gram 模型组合起来产生一 个更好的模型。
3.4.5 简单线性插值
简单线性插值:把不同阶别的n-gram模型线形加权组合。
Pli(wn|wn-2,wn-1) = λ1P(wn) + λ2P(wn|wn-1) + λ3P(wn|wn-2,wn-1)
其中 0≤ λi ≤1 , Σi λi =1。
λi可以根据试验凭经验设定。也可以通过应用某 些算法确定,例如EM算法(最大期望算法)。
在简单线形插值法中,权值λi 是常量不管高阶模型的估计是否可靠,低阶模型均以同样的权重被加入模型,这并不合理。解决办法是让λi 成为历史的函数。
3.4.6 Jelinek-Mercer平滑
Jelinek-Mercer平滑:使用参数训练算法得到λ。
3.4.7 回退模型
回退模型基本思想:在高阶模型可靠时,尽可能的使用高阶模型,必要时,使用低阶模型。
回退模型的一般形式:

3.4.8 Katz平滑
引入折扣率dr,不同的r具有不同的折扣率。
以bigram为例,Katz平滑模型可描述为:
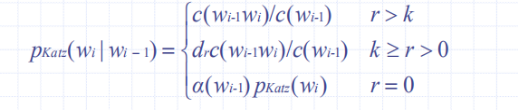
3.5 小结
在回退模型和线形插值模型中,当高阶n-gram未出现时,使用低阶n-gram估算高阶n-gram的概率分布。
在回退模型中,高阶n-gram一旦出现,就不再使用低阶n-gram进行估计。
在线形插值模型中,无论高阶n-gram是否出现,低阶n-gram都会被用来估计高阶n-gram的概率分布。