扫描下方“AI大道理”,选择“关注”公众号
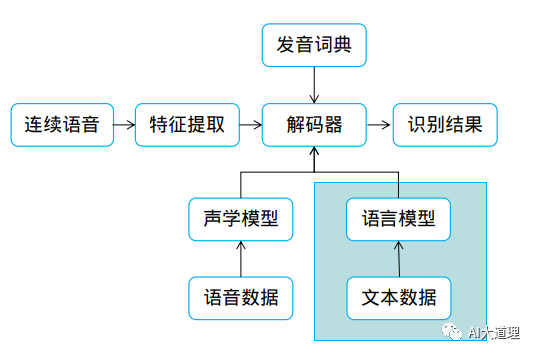
上一专题搭建了一套GMM-HMM系统,来识别连续0123456789的英文语音。
但若不是仅针对数字,而是所有普通词汇,可能达到十几万个词,解码过程将非常复杂,识别结果组合太多,识别结果不会理想。因此只有声学模型是完全不够的,需要引入语言模型来约束识别结果。让“今天天气很好”的概率高于“今天天汽很好”的概率,得到声学模型概率高,又符合表达的句子。
1 语言模型
真面目
定义:对于语言序列词ω1,ω2,ω3,...,ωn,语言模型就是计算该词序列的概率,即P(ω1,ω2,ω3,...,ωn)。
本质:语言模型是对语句的概率分布建模。
通俗:语言模型用来计算一个句子出现的概率,也是判断一句话是否合理的概率。
公式:给定一个词序列S=(w1,w2,w3......wn),它的概率表示为:

其中:
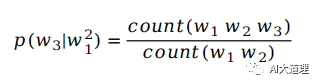
例子:给定一个词序列S=(无数渺小的思考填满了一生)

其中:
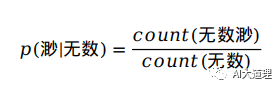
问题:
自由参数问题:模型的自由参数是随着字符串长度的增加而指数级暴增的,这使我们几乎不可能正确的估计出这些参数;
零概率问题(OOV问题):每一个w都具有V种取值,这样构造出了非常多的词对,但实际中训练语料是不会出现这么多种组合的,那么依据最大似然估计,最终得到的概率实际是很可能是0。
2 N-gram语言模型
近似
为了解决自由参数数目过多的问题,引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的n-1个词有关。基于上述假设的统计语言模型被称为N-gram语言模型。
即用前N-1个词作为历史,估计当前(第N个)词。
公式:给定一个词序列S=(w1,w2,w3......wn),它的概率表示为:
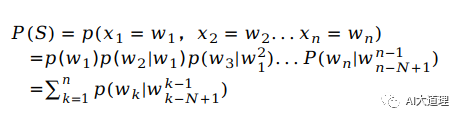
其中:
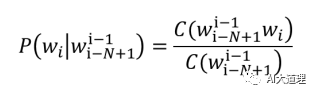
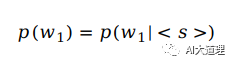
一般用<s>和</s>来标记开头结尾,没有在vocabulary中的词(OOV, out of vocabulary),标记为<UNK>。
当n=1时,即一个词的出现与它周围的词是独立,称为unigram。
当n=2时,即一个词的出现仅与它前面的一个词有关时,称为bigram。
当n=3时,即一个词的出现仅与它前面的两个词有关,称为trigram。
自由参数的数量级是n取值的指数倍。
从模型的效果来看,理论上n的取值越大,效果越好。但随着n取值的增加,效果提升的幅度是在下降的。同时还涉及到一个可靠性和可区别性的问题,参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性。
3 数据平滑算法
为了解决零概率问题,即由于语料的稀疏性,有些词序列找不到,需要对数据进行平滑。
(1)加一平滑(Add-one Smoothing)
思想:将每个计数加一,从而使得任何词序列都有计数,这样的话就可以把本来概率为0结果变为一个很小的值。为了保证所有实例的概率总和为1,将分母增加实例的种类数;即:
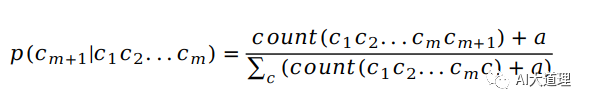
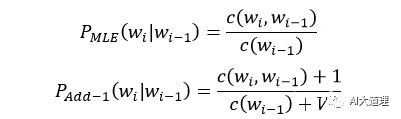
优点:算法简单,解决了概率为0的问题
缺点:Add-one给训练语料中没有出现过的 N-grams 分配了太多的概率空间,认为所有未出现的N-grams概率相等也有点不合理。
(2)古德-图灵平滑(Good-turing Smoothing)
思想:用你看见过一次的事情(Seen Once)估计你未看见的事件(Unseen Events),并依次类推,用看见过两次的事情估计看见过一次的事情等等。
对于任何一个发生r次的n-gram,都假设它发生r*次,即:

则在样本中出现r事件的概率为:

(3)回退平滑(Katz smoothing)
思想:又称为Back-off 回退,是对古德图灵模型的改进。若N阶语言模型存在,直接使用打折后的概率(常使用Good-turing算法进行打折);若高阶语言模型不存在,将打折节省出的概率量,依照N-1阶的语言模型概率进行分配,依此类推。
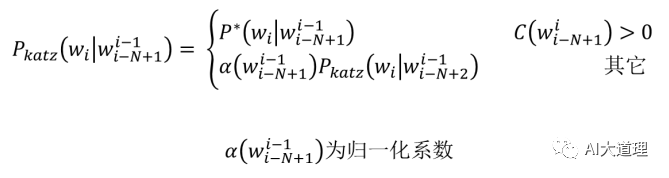
(4)插值平滑(Jelinek-Mercer smoothing)
思想:用线性差值把不同阶的 N-gram 结合起来,这里结合了 trigram,bigram 和 unigram。用 lambda 进行加权。
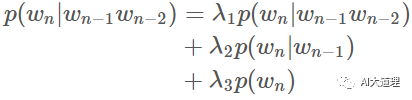
其中,

(5)Witten-Bell smoothing
思想:如果在训练语料中对应的n元文法出现次数大于1,则使用高阶模型;否则,后退到低阶模型。
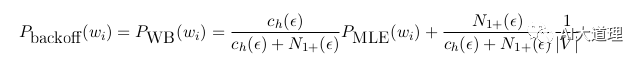
(6)Kneser-Ney Smoothing
思想:对于一个词,如果它在语料库中出现更多种不同上下文(context) 时,它可能应该有更高的概率。
为了刻画这种想法,定义接续概率(continuation probability):
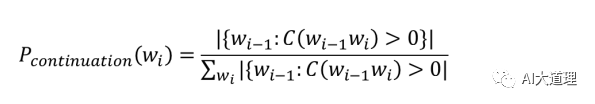
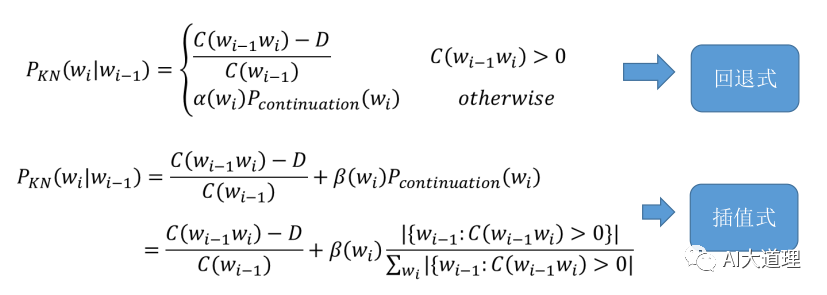
4 困惑度
PPL
N-gram语言模型与评价方法:
实用方法:通过查看该模型在实际应用(如拼写检查、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观。
理论方法:困惑度(preplexity),其基本思想是给测试集的句子赋予较高概率值的语言模型较好。
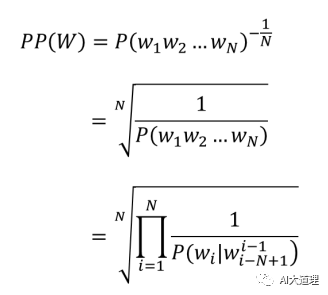
Perplexity另一种表达:
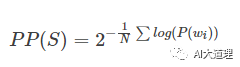
理解:句子越好(概率大),困惑度越小,也就是模型对句子越不困惑。
困惑度->困难度,求出来的困惑度值相当于一个虚拟词典大小,下一个词就从这个虚拟词典中选。值越大,选择就越多,选对就越困难,说明语言模型训练的就越差。值越小,选择就越少,选对的可能性就越大,越简单,说明语言模型训练的越好。
源头:
熵(entropy):又称自信息,描述一个随机变量的不确定性的数量,熵越大,不确定性越大,正确估计其值的可能性越小。越不确定的随机变量越需要大的信息量以确定其值。
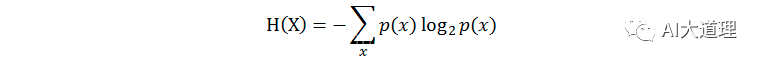
其中,p(x)表示x的分布概率。
相对熵(relativeentropy):又称KL距离,Kullback-Leibler divergence。
衡量相同事件空间里两个概率分布相对差距的测度,当p=q的时候,相对熵为0,当p和q差距变大时,交叉熵也变大。
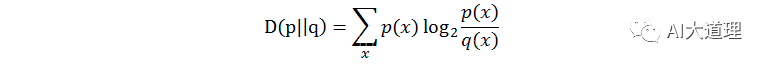
其中,p(x)和q(x)代表x的两种概率分布。
交叉熵(crossentropy):衡量估计模型和真实概率分布之间的差异。
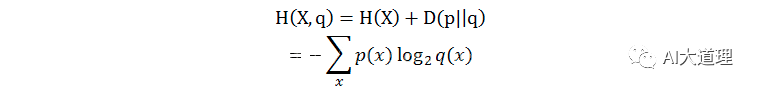
困惑度(perplexity):困惑度是交叉熵的指数形式。
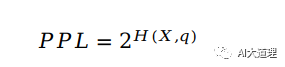
5 语言模型搭建
语言模型训练
语言模型训练流程:

系统文件:
步骤一:Witten-Bell smoothing算法与实现


步骤二:实现ngram计数
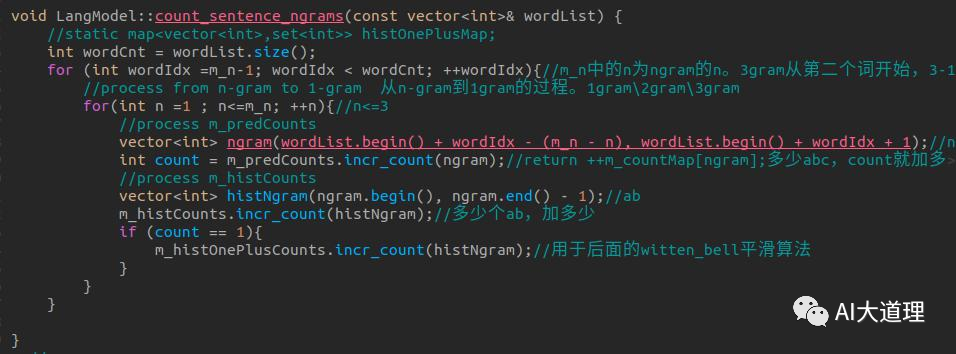
步骤三:词频统计count
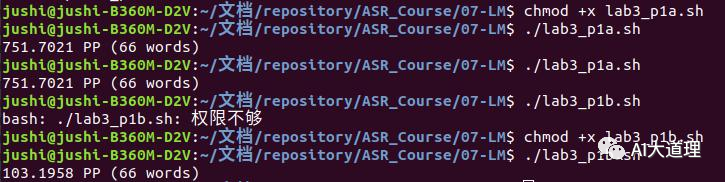

分别对minitrain2.txt和minitrain.txt文件进行count,生成p1a.counts和p1b.counts文件。其中minitrain2.txt和minitrain.txt语料大小不一样,
minitrain2.txt,语料已经分好词,共10个句子,minitrain.txt,语料已经分好词,共100个句子。
步骤四:语言模型训练与测试
平滑算法使用Witten-Bell smoothing。
测试文件使用test2.txt。
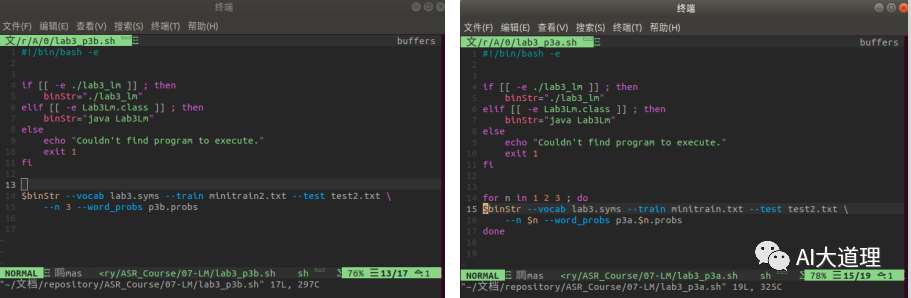
训练3-gram模型与测试结果:

6 SRILM
语言模型工具
上面搭建的系统进行了词频统计和n-gram模型训练与测试,针对相同数据使用SRILM语言模型工具包进行对比。
步骤一:词频统计
词频统计的对象是minitrain2.txt,语料已经分好词,共10个句子。
词频统计的对象是minitrain.txt,语料已经分好词,共100个句子。


其中,ngram-count是srilm的命令,词频统计的对象是minitrain2.txt和minitrain.txt,order3表示3-gram语言模型,生成train2.count文件和train.count。
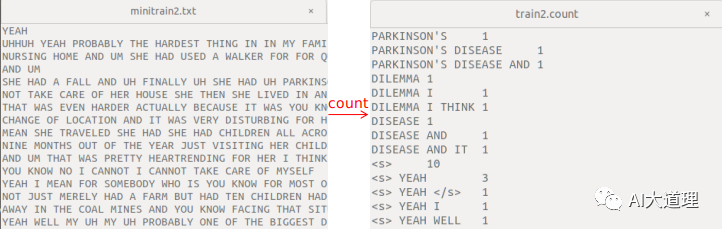
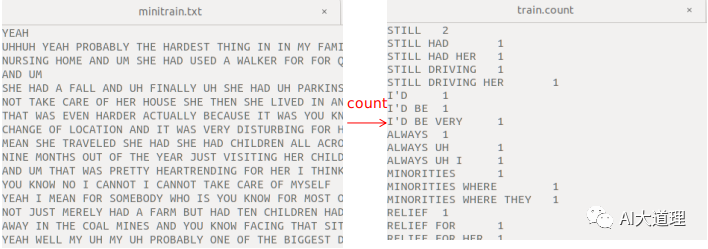
(与搭建的系统统计结果看似不一样,实际上只是排序不一样,上面的系统按照字典里面的词顺序进行排序,使用SRILM进行统计按照文本里面的词顺序进行排序。)
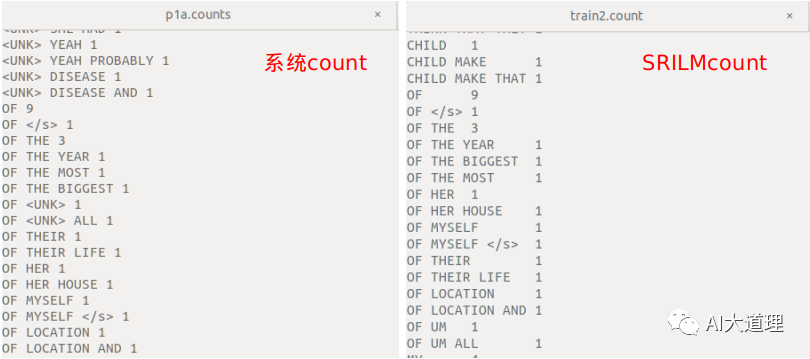
步骤二:语言模型训练
100个句子的语言模型训练。分别使用Kneser-Ney平滑算法、witten bell平滑算法、Good-Turing平滑算法进行数据平滑。

得到3个模型:
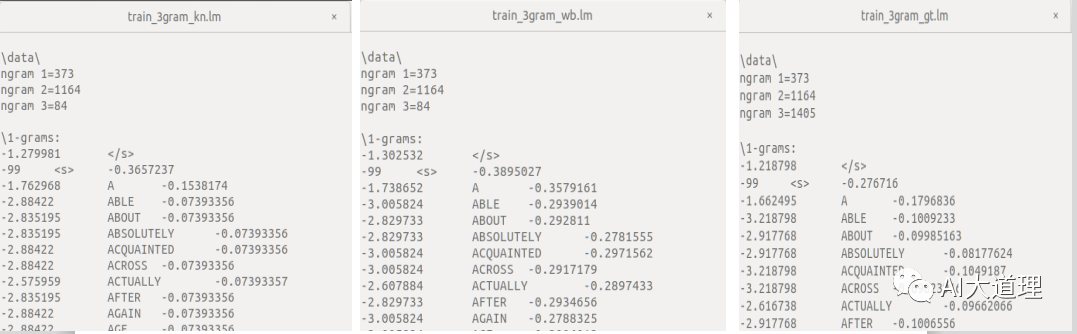
10个句子的语言模型训练,使用Kneser-Ney平滑算法进行语言模型训练命令:

问题:出现error。
原因:其中一个修改后的KneserNey折扣为负,数据集太少,发现高阶n-gram没有出现统计次数。
使用witten bell平滑算法进行语言模型训练命令:
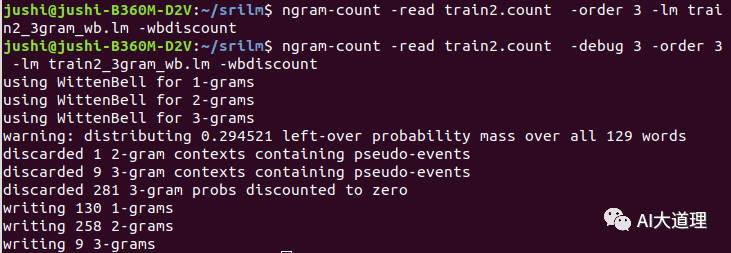
问题:3-grams只有9组数据
原因:丢弃281个3-gram,因为折扣为零。
使用Good-Turing平滑算法进行语言模型训练命令:

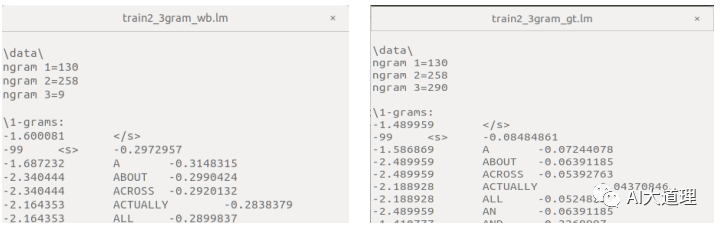
步骤三:语言模型评价(计算 PPL)
-ppl为对测试集句子进行评分(logP(T),其中P(T)为所有句子的概率乘积)和计算测试集困惑度的参数。
10个句子的语言模型,测试文件使用的是 text2.txt文件,测试模型使用witten bell平滑算法训练和Good-Turing平滑算法训练。

100个句子的语言模型,测试文件使用的是 text2.txt文件,测试模型使用Kneser-Ney平滑算法训练、witten bell平滑算法训练、Good-Turing平滑算法训练。
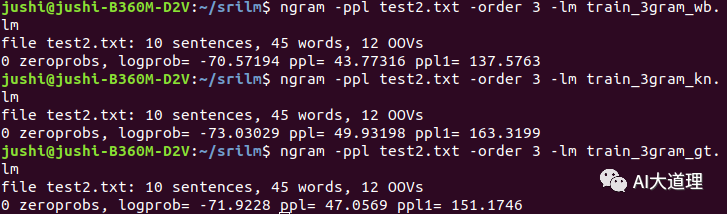
ppl与ppl1的区别:
ppl考虑词数和句子数(i.e. 考虑</s>); PPL1只考虑词数。
ppl = 10^(-logprob / (words - OOVs + sentences))
ppl1 = 10^(-logprob / (words - OOVs))
步骤四:语言模型剪枝(可选)
用于减小语言模型的大小。
-prune threshold 删除一些ngram,满足删除以后模型的ppl增加值
小于threshold,越大剪枝剪得越狠。

7 总结
(RNN语言模型很好,可以对很长的上下文关系进行建模。但是它在语音识别中不常用。因为用RNN语言模型的话,解码出每一个词都得现算语言模型分数,效率不高。它一般用在二次解码rescore中。
N-gram可以编译成加权有限状态转换器,可以看成一种有向图。这样解码就变成了在图中搜索的过程,比较高效。所以语音识别一般用的还是N-gram)
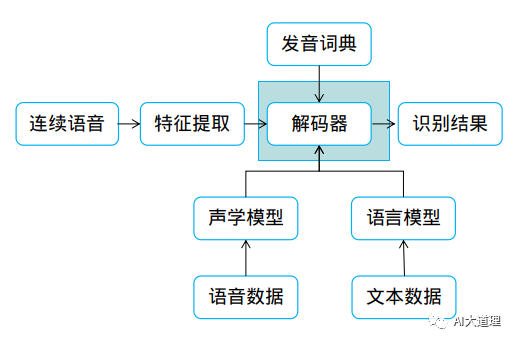
语言模型如何配合声学模型来提高整个识别结果?
这就是解码器所做的事情。
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号

欢迎加入!

▼
下期预告
▼
AI大语音(十一)——WFST解码器
▼
往期精彩回顾
▼
AI大语音(一)——语音识别基础
AI大语音(二)——语音预处理
AI大语音(三)——傅里叶变换家族
AI大语音(四)——MFCC特征提取
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(六)——混合高斯模型(GMM)
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统