之前的是单机版的根据ip地址计算归属地,当数据量小的时候还可以,但是在大数据实际生产中是不行的,必须将它改造成一个Spark程序,然后在Spark集群上运行
Spark程序和单机版的程序不一样,下面来仔细分析一下Spark程序的运行流程
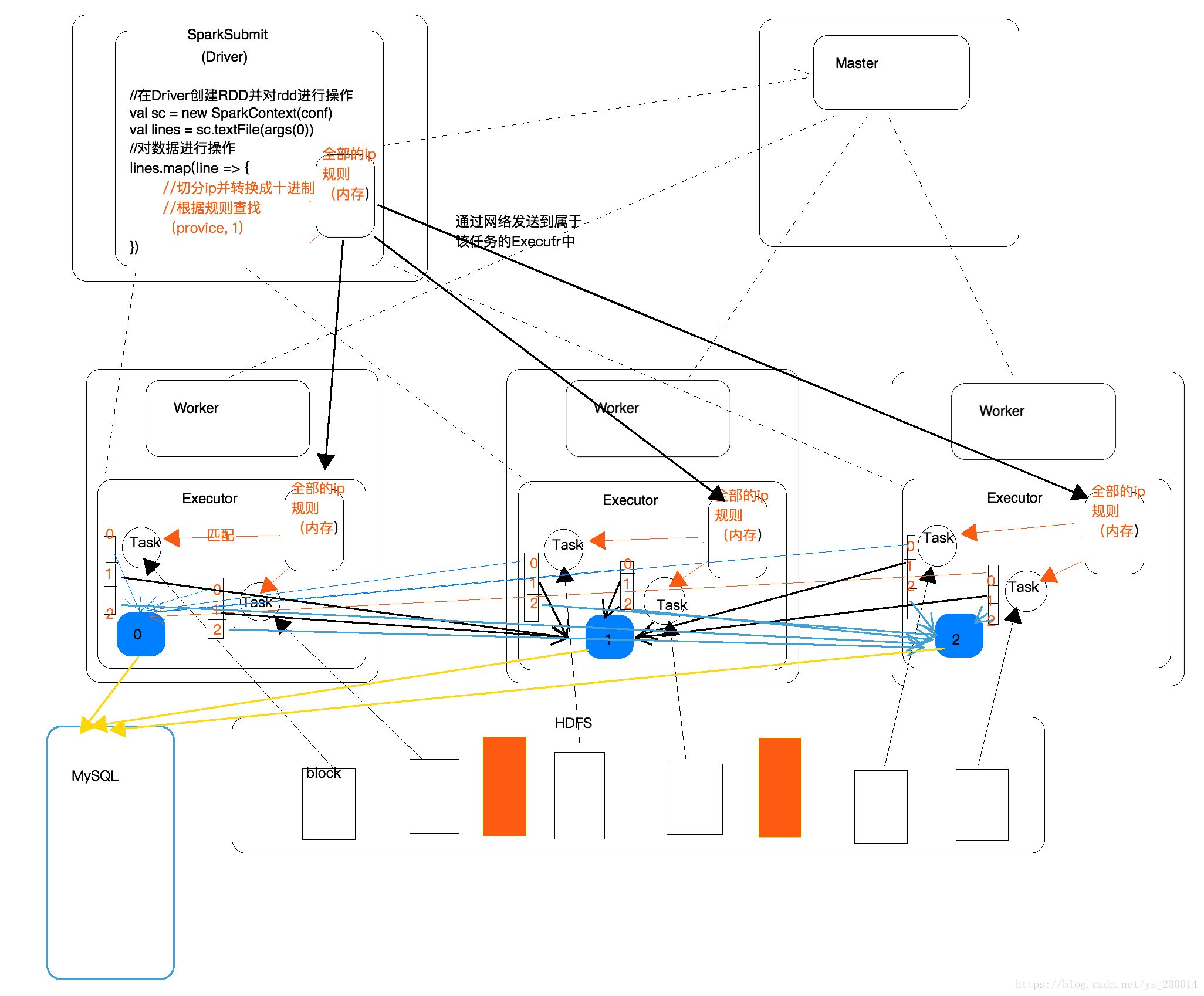
首先是一个Spark集群,集群中有Master和Worker,启动Master和Worker之后,Worker会和Master建立连接并向Master发送心跳,这时候提交一个SparkSubmit,也就是Driver给Master,然后Master会向Spark进行通信,让Worker启动Executor,然后Executor就会和Driver就行通信了, 根据ip地址计算出归属地这个Spark程序是写在Driver端的,但是执行计算是在Execoutor端,也就是说Driver端只告诉执行逻辑,并不参与任何的计算和存储,在Driver端创建了RDD之后,一旦出发执行就会创建Task,然后Driver会通过网络发送到Executor端,然后会在Executor端实现根据ip地址计算出归属地的结果,但是如果ip地址的规则文件不是放在hdfs中的,而是放在Driver端的机器上的,那么Executor端计算的时候就拿不到这个ip地址规则文件,这个时候就引出了Spark中的广播变量了,Driver通过网络将ip地址规则发送个每个Executor上,Executor上的多个Task通过这个ip地址规则来进行匹配,匹配结束之后会生成许多小文件,然后将相同分区的文件聚合到一起,最后存储到Mysql中