前言
前面学习了request库,这一节利用request库和beautifulsoup库爬取IP地址归属地。
技术框架
requests + bs4
bs4官方介绍:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
整体思路
因为是爬虫,主要是爬取网站上的消息,这里我们常用的IP地址查询网站是ip138网站,网站链接:IP138

有了网址,主要是利用他的搜索功能,然后获取搜索后的结果解析出来,那么不妨先分析网页,看他提交搜索的时候url链接有什么变化,然后我们用代码去模拟url提交网页请求,最后再解析返回的消息。
搜索IP:211.68.69.240时如图:

URL:https://www.ip138.com/iplookup.asp?ip=211.68.69.240&action=2
OK这时候发现它提交请求是通过修改url中的IP参数。
代码解析
导入对应的库
import requests
from bs4 import BeautifulSoup
- requests库,用于http请求
- bs4库,用于解析html
定义变量
url = "https://www.ip138.com/iplookup.asp?ip="
kv = {'user-agent': 'Mozilla/5.0'}
- url就是我们用于模拟的地址,先抹去ip部分用参数待会传进去
- kv是一个字典类型,用于模拟浏览器登陆网站,就是声明user-agent变量
请求网站
r = requests.get(url + '202.204.80.112&action=2',headers = kv)
print(r.status_code)
print(r.request.headers)
- hearders参数官方定义:
param headers: (optional) Dictionary of HTTP Headers to send with the class:
Request.
它接受一个字典类型的数据,字典的键值与HTTP的hearders对应,槽值就是我们给他赋的值,比如这个例子中我hearder的user-agent定义成Mozilla/5.0,其他的默认。
- r.status_code是网页请求的返回码,正常情况是200
- r.request.headers,这个是我们向网页请求的headers,可以看到user-agent被修改了

修改编码
r.encoding = r.apparent_encoding
- r是我们网页请求传回来的response,只要修改他的编码r.encoding就可以正确的看到我们的文本。
- r.apparent_encoding是通过分析网页内容得到的网页编码,所以它一般是准确的。
解析网页
soup = BeautifulSoup(r.text , "html.parser")
print(soup.prettify())
- 这里直接用beautifulsoup解析网页,第一个参数是要解析的html文本,第二个参数告诉bs4这是html文本。
- 第二句话是用html格式打印文本

检查网页
有了html文件,我们需要看下源码我们想要的信息存放在哪个位置
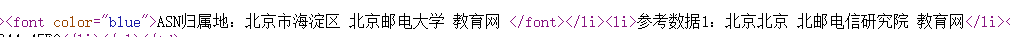
这里看到它直接归属于font标签,然后它之前也没有font标签了,那么这个解析就很简单。。。直接读取第一个font标签就行了。
读取结果
print(soup.find_all('font')[0].string)
- find_all函数会返回列表包含所有的font标签,[0]表示获取第一个font,.string表示获取标签中的文本
输出结果:
ASN归属地:北京市海淀区 北京邮电大学 教育网
完整代码
import requests
from bs4 import BeautifulSoup
url = "https://www.ip138.com/iplookup.asp?ip="
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url + '211.68.69.240&action=2',headers = kv)
print(r.status_code)
print(r.request.headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text , "html.parser")
#print(soup.prettify())
#for font in soup.find_all('font'):
# print(font.string)
print(soup.find_all('font')[0].string)