案例二中已经详细的通过图和介绍详细的说明了在Spark集群中根据ip地址计算归属地并将结果保存到mysql数据库中的运行流程,下面就来做具体的实现
现在的环境就如案例二中说的一样,ip地址规则是保存在Driver端的机器磁盘中,而日志文件是保存在hdfs中,所以现在需要首先在Driver端拿到ip地址规则,然后通过广播变量使Executor端能够拿到ip地址规则,然后取出hdfs中的日志文件,将日志文件进行切分整理,与ip地址规则进行匹配,最后将结果存储到mysql数据库中
1.具体代码实现
package cn.ysjh0014
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object IpLocation1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("IpLoaction1").setMaster("local[4]")
val sc = new SparkContext(conf)
//在Driver端获取到全部的IP规则数据(全部的IP规则数据跟Driver在同一台机器上)
val rules: Array[(Long, Long, String)] = TestIp.readRules(args(0))
//将Drive端的数据广播到Executor中,调用sc上的广播方法,广播变量的引用(还在Driver端)
val broadcastRef: Broadcast[Array[(Long, Long, String)]] = sc.broadcast(rules)
//创建RDD,读取访问日志
val accessLines: RDD[String] = sc.textFile(args(1))
//这个函数是在哪一端定义的?(Driver)
val func = (line: String) => {
val fields = line.split("[|]") //根据|进行切分
val ip = fields(1) //取出切分后文件中的ip
//将ip转换成十进制
val ipNum = TestIp.ip2Long(ip)
//进行二分法查找,通过Driver端的引用或取到Executor中的广播变量
//(该函数中的代码是在Executor中别调用执行的,通过广播变量的引用,就可以拿到当前Executor中的广播的规则了)
val rulesInExecutor: Array[(Long, Long, String)] = broadcastRef.value
//查找
var province = "未知"
val index = TestIp.binarySearch(rulesInExecutor, ipNum)
if (index != -1) {
province = rulesInExecutor(index)._3
}
(province, 1)
}
//整理数据
val proviceAndOne: RDD[(String, Int)] = accessLines.map(func)
//聚合
val reduced: RDD[(String, Int)] = proviceAndOne.reduceByKey(_ + _)
def data2MySQL(it: Iterator[(String, Int)]): Unit = {
//一个迭代器代表一个分区,分区中有多条数据
//先获得一个JDBC连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
//将数据通过Connection写入到数据库
val pstm: PreparedStatement = conn.prepareStatement("INSERT INTO access_log VALUES (?, ?)")
//将分区中的数据一条一条写入到MySQL中
it.foreach(tp => {
pstm.setString(1, tp._1)
pstm.setInt(2, tp._2)
pstm.executeUpdate()
})
//将分区中的数据全部写完之后,在关闭连接
if (pstm != null) {
pstm.close()
}
if (conn != null) {
conn.close()
}
}
reduced.foreachPartition(it => data2MySQL(it))
//将结果打印
// val r = reduced.collect()
// reduced.saveAsTextFile(args(2))
// println(r.toBuffer)
sc.stop()
}
}
2.在mysql数据库中创建bigdata数据库,然后创建access_log表,在表中添加两个字段
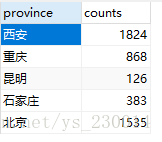
3.运行结果:
注意: 代码在运行的时候如果报连接数据库错误的话,要不就是数据库配置写错了(用户名,密码等),要不就是没有导入mysql驱动包,可以在pom文件中加入以下依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>这里的mysql驱动包的版本不能低,我的windows下的mysql是8.0.12的,之前我添加的依赖版本是5.1.38的就一直报错连接不上数据库,很坑。。。。。。。