分类问题是机器学习的研究重点,而后者在实践中常常碰到非均衡数据集这个难题。非均衡数据集(imbalanced data)又称为非平衡数据集,指的是针对分类问题,数据集中各个类别所占比例并不平均。
比如在网络广告行业,需要对用户是否点击网页上的广告进行建模。为了处理方便,我们记“点击广告”为类别1,“不点击广告”为类别0。因此这是一个二元分类问题。在训练模型的历史数据里有1000个数据点(1000行),其中类别1的数据点只有10个,剩下的990个数据全部为类别0。这就是一个非均衡数据集,类别之间的比例为99:1。与二元分类问题类似,多元分类问题同样会面对非均衡数据集这个难题。不过在这个问题上,多元分类的处理的方案与二元的相似,因此为了表述简洁利于理解,下面的讨论将针对二元分类问题。
非均衡数据集在现实中是十分常见的。它给模型搭建带来了困难,如果不小心处理,会导致得到的模型结果毫无意义。在讨论这个话题之前,让我们稍稍离题一下,来看看所谓的准确度悖论(accuracy paradox)。
注意:本篇文章的完整代码在*这里下载***
一、准确度悖论
对于二元分类问题,模型的预测结果按准确与否可以分为如下4类,见表1。

其中,TP和TN这两个部分都表示模型的预测结果是正确的,这两者之和的比例越高,说明模型的效果越好。由此可以定义评估模型效果的指标——准确度(accurary,ACC)。
准确度这个指标看似很合理,但面对非均衡数据集时,这个指标会严重失真,甚至变得毫无意义。来看下面这个例子:数据集里有1000个数据点,其中990个为类别0,而剩下的10个为类别1,如图1所示。
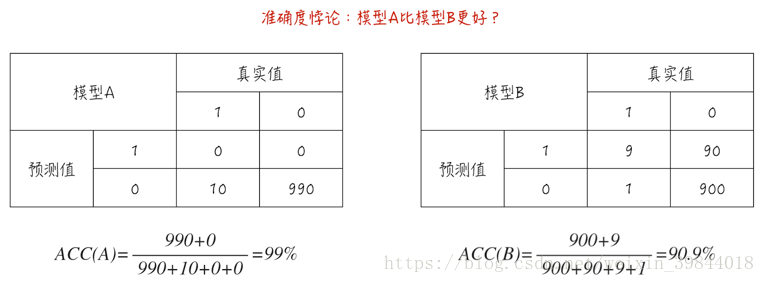
模型A对所有数据的预测都是类别0,因此这个模型其实并没有提供什么预测功能。但它的准确度却高达99%。模型B的预测效果其实很不错:对于类别1,10个数据里有9个预测正确;而对于类别0,990个数据里有900个预测正确,但它的准确度只有90.9%远低于模型A。
这就是所谓的准确度悖论:面对非均衡数据集时,准确度这个评估指标会使模型严重偏向占比更多的类别,导致模型的预测功能失效。这也是之前文章(分类模型的评估(一))讨论模型评估时,我们并没有介绍准确度这个指标的原因。事实上,分类模型的评估(二)里讨论的AUC(曲线下面积)在面对非均衡数据集时,也能保持稳定,不会发生如准确度悖论这样的失真。
二、一个例子
非均衡数据集除了会引起准确度悖论外,它对搭建模型有什么影响呢?下面通过一个简单的例子来说明这个问题。我们按公式(2)产生模型数据,其中变量 为因变量; 为自变量; 为随机扰动项,它服从逻辑分布。
由此可见,产生的模型数据完美地符合逻辑回归模型的假设。因此使用逻辑回归对数据建模,得到结果按理说应该非常好。但事实上,当数据集是均衡时,也就是说类别1所占比例大约为0.5时,模型效果是还不错。但当类别1所占比例接近0时,也就是数据集是非均衡时,模型的效果就很差了。虽然数据集里类别1的个数不变,但模型的预测结果几乎都是类别0,如图2a所示。正如上面讨论的那样,ACC这个指标在非均衡数据集里会失真,而AUC则可以保持稳定,能正确衡量模型的好坏,如图2b所示。
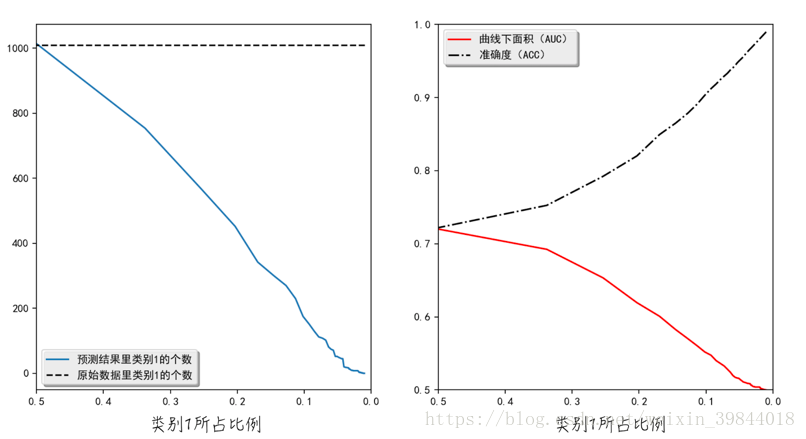
上面的例子从直观上展示了非均衡数据集对搭建模型的影响。那么造成这种结果的原因是什么呢?从数学角度来讲,逻辑回归参数的估算公式如下:(惩罚项并不影响这里的讨论,因此我们在此省略掉惩罚项。)
在这个公式里,每个数据点的权重都是一样的,都为1。也就是说,模型对于类别1所承受的损失为: 。这个值几乎等于模型对于类别0所承受的损失: 。如果某一类别的数据特别多,不妨假定为类别0,那么在类别1某点的附件,极有可能存在大量的类别0。在这种情况下,根据公式(3),模型会选择“牺牲”类别1,从而导致预测结果几乎都为类别0。
上面的结论并不只针对逻辑回归这个分类模型,对于其他分类模型,也同样成立。
三、解决方法
针对非均衡数据集,最常见也是最方便的解决方案是修改损失函数里不同类别的权重。以逻辑回归为例,将它的损失函数改写为公式(4)。
当类别1所占比例很少时,则增加 ,也就是增加模型对于类别1所承受的损失,反之亦然。在大多数情况下,类别权重的选择原则是,类别权重等于类别所占比例的倒数,如程序清单1中**第7、8行代码所示**。经过权重调整后,训练模型的数据集相当于回到了均衡状态。权重调整的代码非常简单,如第10行代码所示,通过“class_weight”参数调整各个类别的权重。事实上,“class_weight”也可以被赋值为“balanced”,即“class_weight= ‘balanced’”,这时模型会自动调整各个类别的权重。
程序清单1 非平衡数据集
1 | from sklearn.linear_model import LogisticRegression
2 |
3 | def balanceData(X, Y):
4 | """
5 | 通过调整各个类别的比重,解决非均衡数据集的问题
6 | """
7 | positiveWeight = len(Y[Y>0]) / float(len(Y))
8 | classWeight = {1: 1. / positiveWeight, 0: 1. / (1 - positiveWeight)}
9 | # 为了消除惩罚项的干扰,将惩罚系数设为很大
10 | model = LogisticRegression(class_weight=classWeight, C=1e4)
11 | model.fit(X, Y.ravel())
12 | pred = model.predict(X)
13 | return pred
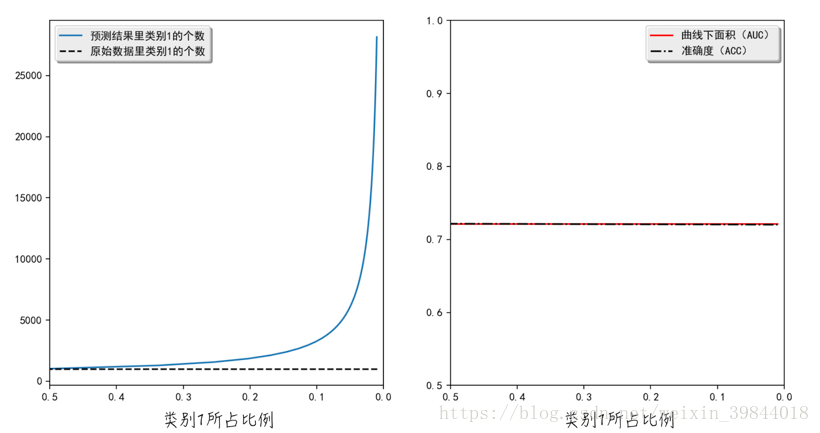
经过权重调整后,模型的结果如图3所示。在处理非均衡数据集时,调整权重后的模型会错误地将很多类别0的数据预测为类别1。这与我们之前在上一节里的分析是一致的:类别1的权重增加后,模型会因“刻意地珍惜”类别1,而选择“牺牲”类别0。尽管如此,调整之后的整体效果明显优于调整之前的(调整之后的AUC更大)。值得注意的是,ACC和AUC这两个评估指标几乎相等,所以图形上它们两者重叠在了一起。
对于非均衡数据集,还有一些其他的解决方法,比如通过重新抽样(sampling),把多的类别变少或把少的类别变多。具体的细节在此就不做展开讨论了。
四、广告时间
这篇文章的大部分内容参考自我的新书《精通数据科学:从线性回归到深度学习》。
李国杰院士和韩家炜教授在读过此书后,亲自为其作序,欢迎大家购买。
另外,与之相关的免费视频课程请关注这个链接