第一章介绍了本书所涉及基本术语和概念。
- 数据集、样本、特征(属性)、特征空间(属性空间、样本空间、输入空间)、特征向量、维数;
- 学习(训练)、训练数据、训练样本、假设、预测、标记、样例、标记空间(输出空间)、测试、测试样本;
- 分类、回归、聚类、簇、监督、无监督、泛化能力;
- 归纳、演绎、概念学习、假设空间、版本空间;
- 归纳偏好(偏好)、奥卡姆剃刀;
同时简要介绍了机器学习的发展史。
- 符号主义、连接主义、机器学习、数据挖掘、统计学;
- 泛化能力:学得模型适用于新样本的能力,具有强泛化能力的模型能很好地适用于整个样本空间。
- 假设空间:在所有假设(hypothesis)组成的空间中,例如文中西瓜的例子,假设空间形如(色泽=?)∩(根蒂=?)∩(敲声=?)的可能取值组成。若色泽、根蒂、敲声分别有3、3、3种可能的取值,则假设空间规模大小为(3+1)*(3+1)*(3+1)+1=65,其中+1是指没有好瓜这个东西,即∅。
- 版本空间:学习过程中是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合“,称之版本空间。
- 归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”
习题 1.1 若表 1.1 只包含 1 和 4 两个样例,试给出相应的样本空间。已知色泽有两种取值,根蒂和敲声分别有三种取值。
| 编号 | 色泽 | 根蒂 | 敲声 | 好瓜 |
|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 2 | 乌黑 | 蜷缩 | 浊响 | 是 |
| 3 | 青绿 | 硬挺 | 清脆 | 否 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 否 |
首先说明概念1:版本空间(version space)是概念学习中与已知数据集一致的所有假设(hypothesis)的子集集合。即是版本空间是假设空间中于样本满足一致的“假设集合”, 是基于样本决定的。
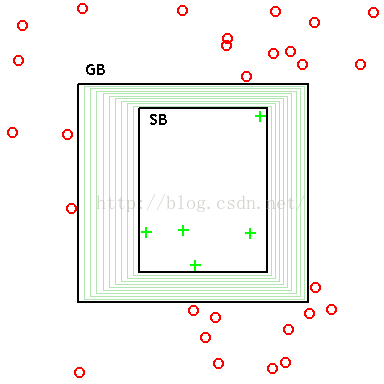
SB 是最大精确正假设边界(maximally Specific positive hypothesis Boundary)。
对于二维空间中的“矩形”假设(如图),绿色代表正例,红色代表负例。学习过程中,可以 不断删除与正例不一致的假设、和(或)与反例一致的假设。最终将会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设,即学得结果。如图 GB 与 SB 所围成的区域中的矩形即为版本空间。
解答:由于色泽有两种取值,根蒂和敲声分别有三种取值,再各自加上“通配”(即取什么值都无关紧要)这一项,一共是 (2+1)×(3+1)×(3+1)=48
种取值,另外还有一种取值是“好瓜这个概念根本不成立”即空集。故 假设空间大小为 48+1=49。现在根据已有样本 1 和 4,可以排除掉假设空间中所有“色泽 ≠青绿”或“根蒂 ≠蜷缩”或“声响 ≠浊响”的项,以及由于有样本 1 即好瓜的存在,排除空集那一项,所以得到的版本空间大小为 8,用合取式表示则是以下 8 种取值:
(色泽=青绿)∧(根蒂=∗)∧(敲声=∗)(色泽=∗)∧(根蒂=蜷缩)∧(敲声=∗)(色泽=∗)∧(根蒂=∗)∧(敲声=浊响)(色泽=青绿)∧(根蒂=蜷缩)∧(敲声=∗)(色泽=青绿)∧(根蒂=∗)∧(敲声=浊响)(色泽=∗)∧(根蒂=蜷缩)∧(敲声=浊响)(色泽=青绿)∧(根蒂=蜷缩)∧(敲声=浊响)

习题 1.2 解答:刚已经分析了有 8 种取值,故假设空间中的假设用析取范式表达形式如下:
好瓜↔∨∨∨∨∨∨((色泽=青绿)∧(根蒂=∗)∧(敲声=∗))((色泽=∗)∧(根蒂=蜷缩)∧(敲声=∗))((色泽=∗)∧(根蒂=∗)∧(敲声=浊响))((色泽=青绿)∧(根蒂=蜷缩)∧(敲声=∗))(色泽=青绿)∧(根蒂=∗)∧(敲声=浊响))((色泽=∗)∧(根蒂=蜷缩)∧(敲声=浊响))((色泽=青绿)∧(根蒂=蜷缩)∧(敲声=浊响))
其中任意一个取值可以去掉(即去掉取值的约束,从而扩大了结果的空间),比如
好瓜↔∨((色泽=青绿)∧(根蒂=∗)∧(敲声=∗))((色泽=∗)∧(根蒂=蜷缩)∧(敲声=∗))
也是一种假设。但不可将 8 个都去掉,这样对“好瓜”就毫无约束了,这样存在样本 4 是不符的。故包含以上 8 额合取式中任意非 0 个的析取范式表达式都是合理的假设,即共有 28−1=255 种假设。
首先给出相关定义,合取范式:Conjunctive normal form - Wikipedia,析合范式:Disjunctive normal form - Wikipedia。

习题 1.3 解答:由于含有噪声,故可对样本空间放宽约束。对于那些只与极少数样本不一致却与极大多数样本一致的假设,仍将其保留在版本空间中。
- 最简单的设计就是:训练样本一致特征越多越好(一致性比例越高越好)为归纳偏好。
- 另外,考虑归纳偏好应尽量与问题相匹配,这里可使归纳偏好与噪声分布相匹配。