Python Scrapy框架爬取BOSS直聘招聘信息
1.创建项目
库的下载:
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
cd 到想要创建爬虫的目录执行命令
scrapy startproject 项目名
成功创建项目之后,会得到如图的文件目录结构
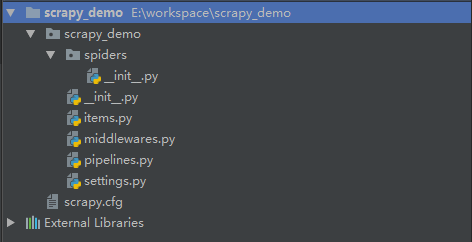

根据提示cd到scrapy 执行 scrapy genspider 爬虫名 域名
此时,项目中就新建好了一个爬虫文件 :
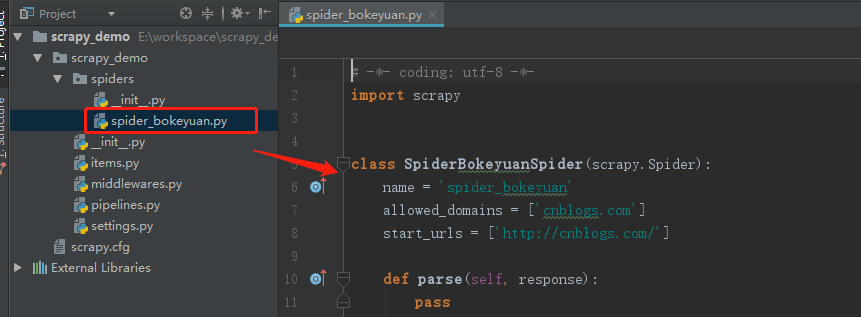
启动爬虫可以使用命令: Scrapy crawl 爬虫名
但是,真实的开发中,这样写是不方便调试的,应该使用一个文件来启动爬虫。
在项目中建立一个main.py文件,然后运行该文件即可。
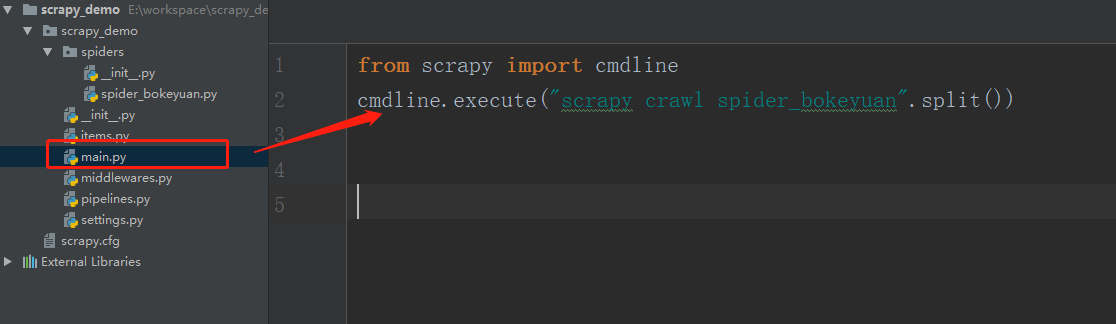
下面是相关代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl spider_bokeyuan".split())
2.项目分析
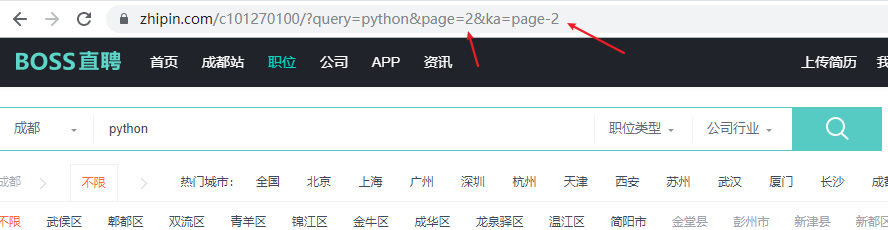
1.根据网址链接可以看到只要更改page 这两个参数就可以进行翻页
2.查看网页源代码可以看到有一长串cookie 后期我们可以直接复制(如果不传cookie是访问不到正确的页面的)
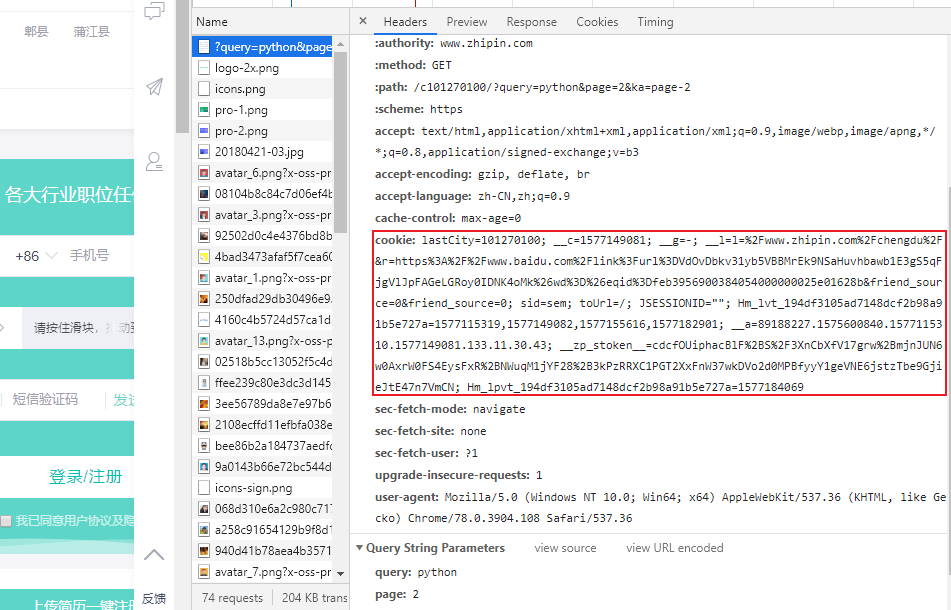
3.产看源代码看到详情页的链接所在标签

3.代码实现
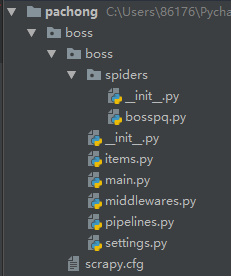
1.目录结构
2.bosspq.py
# -*- coding: utf-8 -*- import scrapy from items import BossItem import time class BossSpiderMiddleware(scrapy.Spider): name = "bosspq" # 爬虫名 allowed_domains = ["zhipin.com"] base_url = "https://www.zhipin.com/c101270100/?query=python&page=%s&ka=page-%s" # 设置一个列表存储url链接 url_list = [] # 循环遍历出url并添加到列表中 for i, n in zip(range(1, 3), range(1, 3)): url = base_url % (i, n) url_list.append(url) start_urls = url_list # 设置cookie cookie_list = "lastCity=101270100; __c=1577149081; __g=-; __l=l=%2Fwww.zhipin.com%2Fchengdu%2F&r=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DVdOvDbkv31yb5VBBMrEk9NSaHuvhbawb1E3gS5qFjgVlJpFAGeLGRoy0IDNK4oMk%26wd%3D%26eqid%3Dfeb3956900384054000000025e01628b&friend_source=0&friend_source=0; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1577115314,1577115319,1577149082,1577155616; __a=89188227.1575600840.1577115310.1577149081.127.11.24.37; __zp_stoken__=cdcfOUiphacBlF%2BS%2F3XnCbXfVxOlbboK5u4MjFQnYZqQ%2B3y3Du3Rs7ZOZLkVuqG42JoUkPzRRXC1PGT2XxFnW37wkM24kGa%2BuQg8ZN54Rh3dKsEtzTbe9GjieJtE47n7VmCN; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1577175217" custom_settings = { 'DEFAULT_REQUEST_HEADERS': { 'Cookie': cookie_list, 'Referer': 'https://www.zhipin.com/chengdu/', } } def parse(self, response): print(response.text) print("*" * 40) link = {} a = response.xpath("//div[@class='info-primary']/h3") for i in a: link["url"] = "https://www.zhipin.com/" + i.xpath('./a/@href').get() print(link) yield scrapy.Request(link['url'], callback=self.boss_list) def boss_list(self, response): item = BossItem() item['job'] = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/div[2]/h1/text()').get() item['wage'] = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/div[2]/span/text()').get().strip() item['name'] = response.xpath('//*[@id="main"]/div[3]/div/div[1]/div[2]/div/a[2]/text()').get().strip() item['job_xq'] = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div/text()').get().strip() # 设置爬取间隔 time.sleep(1) yield item
注意:如果要使用该程序需要在浏览器上从新复制cookie 粘贴到cookie_list
3.item.py
import scrapy class BossItem(scrapy.Item): # 职位 job = scrapy.Field() # 工资 wage = scrapy.Field() # 公司名 name = scrapy.Field() # 工作需求 job_xq = scrapy.Field()
4.main.py
from scrapy import cmdline cmdline.execute("scrapy crawl bosspq".split())
5.middlewares.py
import random # 随机请求头 class UserAgentDownloadMiddleWare(object): # 需要随机的请求头 USER_AGENTS = [ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36', 'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; pl-PL; rv:1.0.1) Gecko/20021111 Chimera/0.6', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36', 'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; en) AppleWebKit/418.8 (KHTML, like Gecko, Safari) Cheshire/1.0.UNOFFICIAL', 'Mozilla/5.0 (X11; U; Linux i686; nl; rv:1.8.1b2) Gecko/20060821 BonEcho/2.0b2 (Debian-1.99+2.0b2+dfsg-1)' ] def process_request(self, request, spider): # 随机生成一个请求头 user_agent = random.choice(self.USER_AGENTS) request.headers['User-Agent'] = user_agent
6.pipelines.py
from pymongo import MongoClient class BossPipeline(object): # mongodb的链接 def __init__(self, databaseIp='127.0.0.1', databasePort=27017, mongodbName='mydb'): # 与mongodb建立链接 client = MongoClient(databaseIp, databasePort) # 进入数据库mydb self.db = client[mongodbName] def process_item(self, item, spider): postItem = dict(item) # 把item转化成字典形式 self.db.scrapy.insert(postItem) # 向数据库中的scrapy集合插入一条记录 return item # 会在控制台输出原item数据,可以选择不写
7.settings.py
BOT_NAME = 'boss' SPIDER_MODULES = ['boss.spiders'] NEWSPIDER_MODULE = 'boss.spiders' ROBOTSTXT_OBEY = False # 表示不遵守robots协议 """cookie的设置""" COOKIES_ENABLED = False """开启中间建""" DOWNLOADER_MIDDLEWARES = { 'boss.middlewares.UserAgentDownloadMiddleWare': 543, } ITEM_PIPELINES = { 'boss.pipelines.BossPipeline': 300, }
注:具体实现流程请参考代码注释