版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Yk_0311/article/details/82986931
以前看过这小说,觉得写得很不错,所以觉得自己将其爬取下来
爬取的思路
1
先找到资源页:https://www.88dus.com/xiaoshuo/0/801/
然后你可以看到所有章节
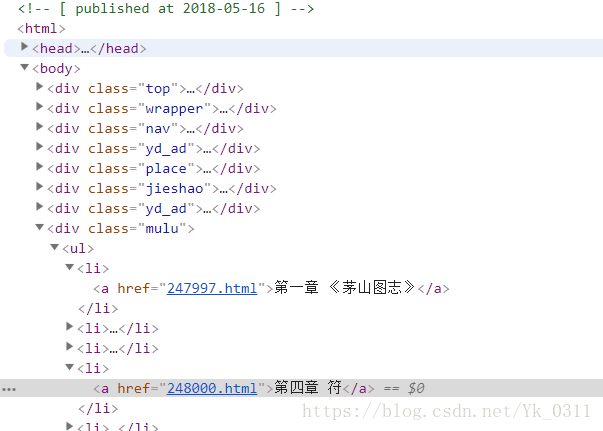
右击并选择检查项,选择Elements选项卡
你可以发现所有章节的信息都在
如图所示的标签下
我利用了CSS选择器将其选择出来,并提取章节的名称和url
2
将提取出的url加在https://www.88dus.com/xiaoshuo/0/801/后面,这样就可以访问到每一个章节,最后再将文本提取出来保存
爬取的代码
'''
爬取《茅山后裔小说》
资源页:https://www.88dus.com/xiaoshuo/0/801/
'''
import requests
from bs4 import BeautifulSoup
import time
def get_html(url):
hd = {'User-Agent': 'Mozilla/5.0'} # 模拟浏览器进行访问
r = requests.get(url, headers=hd)
r.raise_for_status() # 抛出异常
r.encoding = r.apparent_encoding
# print(r.text)
return r.text
def get_partURL(html, MList):
'''
function:从页面中获得部分url
:param html:
:param MList: 存储url和章节名称的列表
:return:
'''
soup = BeautifulSoup(html, 'html.parser')
TagList = soup.select('div.mulu ul li a') # 利用CSS选择器得到存储信息的标签
for tag in TagList:
MList.append([tag['href'], tag.string]) # 将url添加到列表当中
def get_text(item):
'''
获得文本信息
:param item:MList中的一个单元
:return:章节的文本信息
'''
url = 'https://www.88dus.com/xiaoshuo/0/801/' + item[0] # 组成完整的链接,是一个章节的链接
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
text = str(soup.select('div.yd_text2')[0]) # 找到标签然后转换为文本
text = text.replace('<div class="yd_text2">', '').replace("<br/>", "").replace('</div>', 'end') # 替换字符串
text = item[1] + '\n' + text # 将章节的名称加上
return text
def save(text):
'''
function:保存为txt文件
:param text: 文本信息
:return:
'''
path = 'D:\IDE\Pycharm\MySpider\DEMO1\\《茅山后裔》.txt'
with open(path, 'a', encoding='utf-8') as f:
f.write(text + '\n')
def main():
MList = []
url = 'https://www.88dus.com/xiaoshuo/0/801/' # 资源页
html = get_html(url) # 获得资源页的HTML
get_partURL(html, MList) # 解析页面得到url与章节的名称,并存入MList
allamount = len(MList) # 用来实现进度
num = 0
for item in MList: # 遍历其中的单元
try:
text = get_text(item) # 获得文本文件
save(text) # 保存
num = num + 1
print('进度:{}%'.format(round(num * 100 / allamount)))
time.sleep(1) # 爬取的速度限制一下,不要给网页太大的压力
except:
continue
main()
最后main()函数中的异常处理,是因为访问某些章节可能会不成功,所以except中进行了跳过异常。
爬取下的文本放在了github上
链接:https://github.com/YilK/Web-Crawler/blob/master/DEMO02-《茅山后裔》小说的爬取/《茅山后裔》.txt