版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/baifanwudi/article/details/87639518
最近想学习scrapy爬虫,先爬小说练练手。
安装scrapy
pip install scrapy
新建novel项目
scrapy startproject novel
目录结构如下:

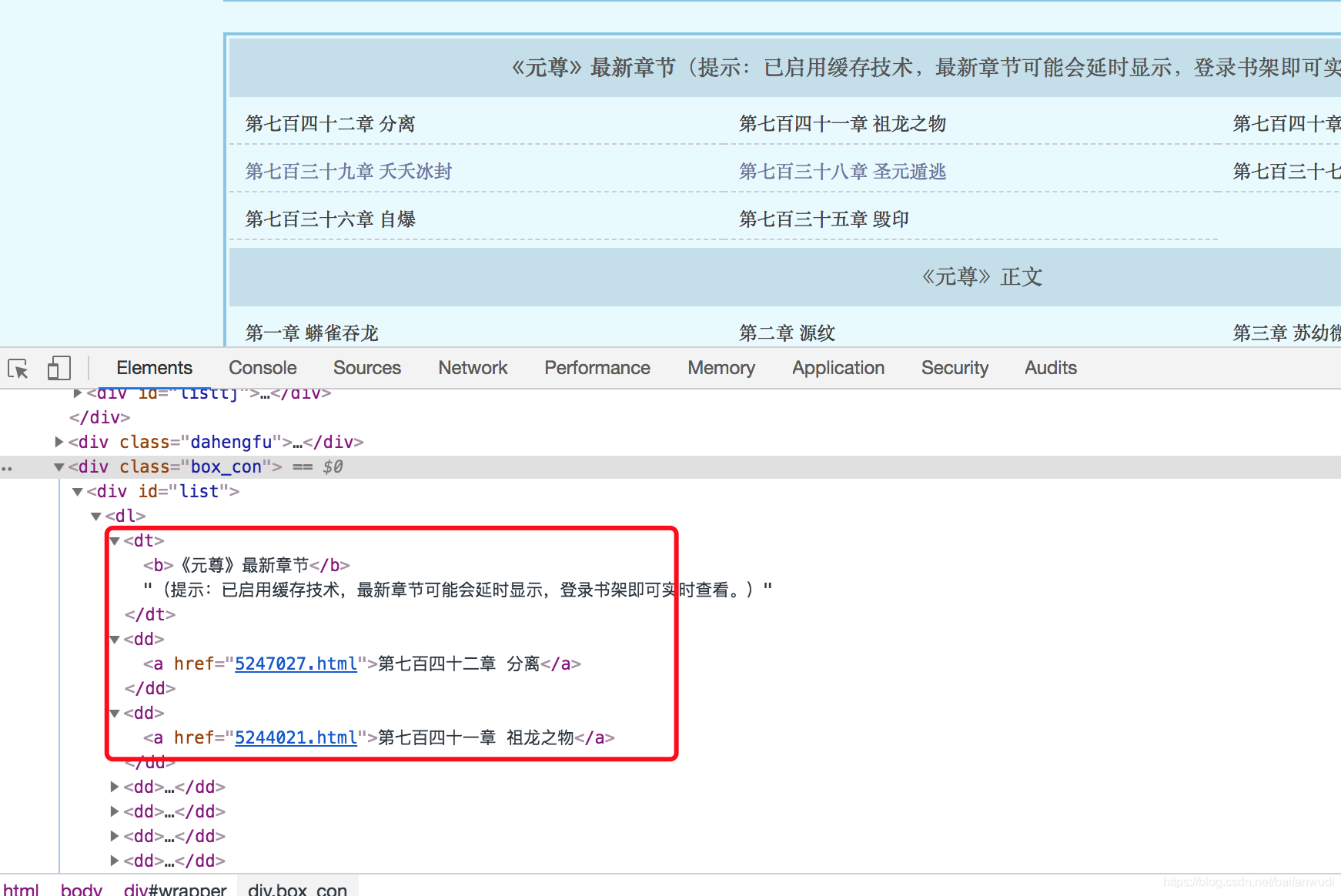
打开chrome查看网页源码https://www.booktxt.net/6_6453/
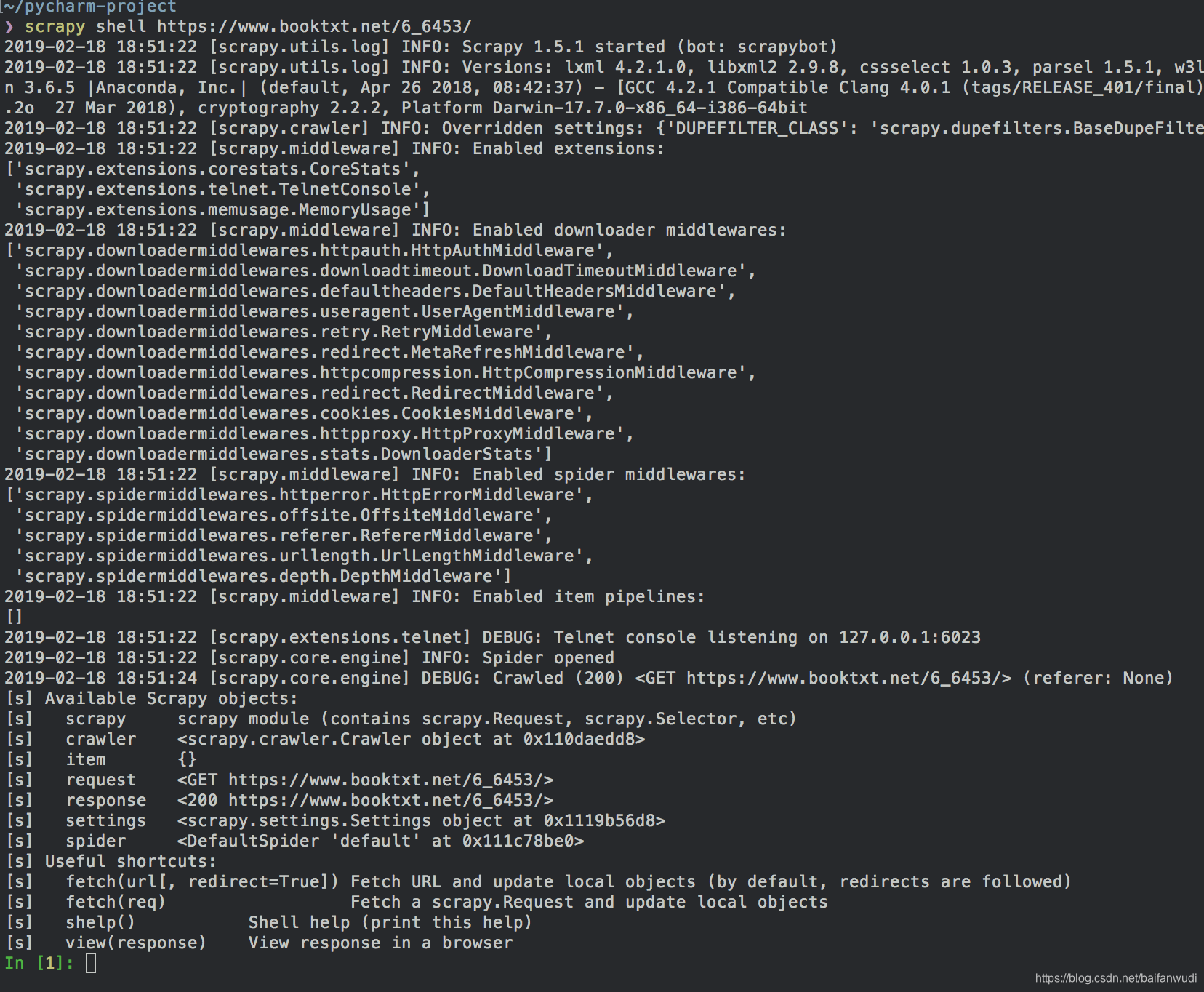
在命令端运行
scrapy shell https://www.booktxt.net/6_6453/
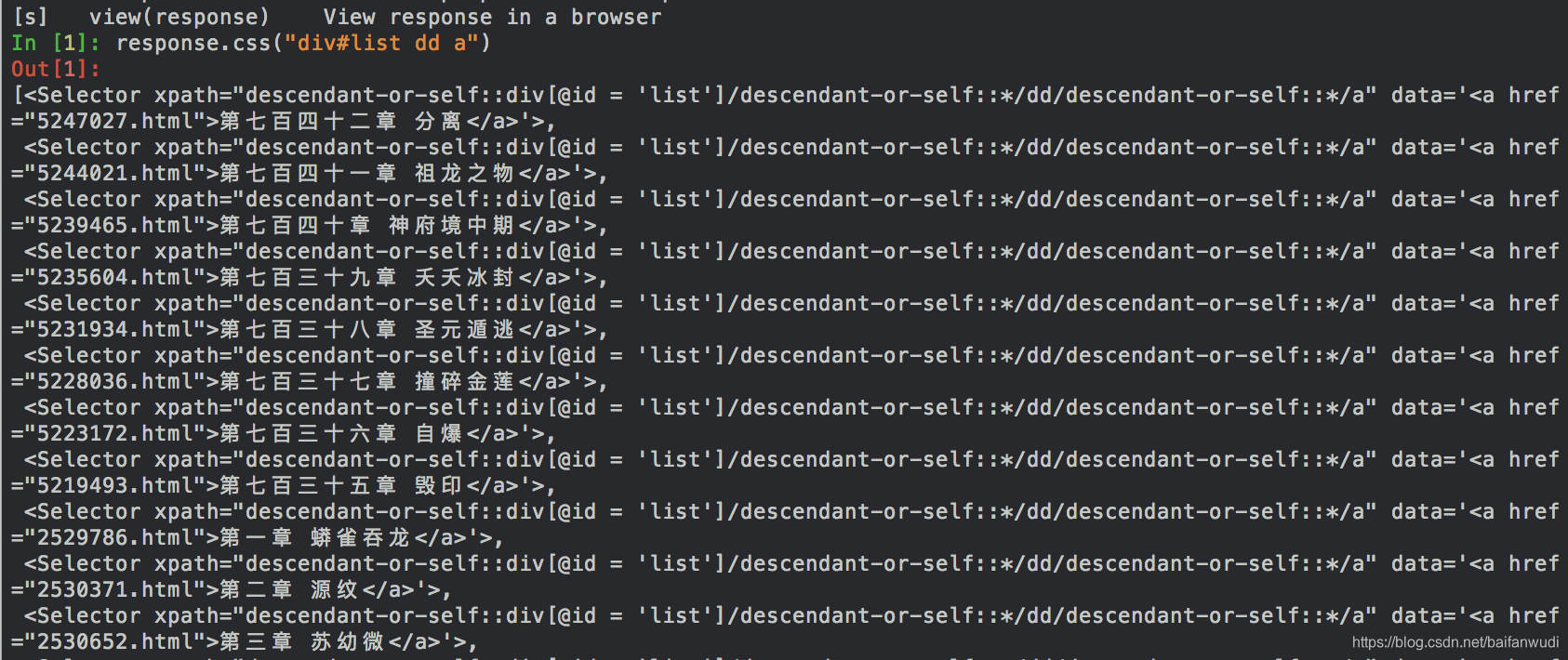
输入命令
response.css("div#list dd a")
#####说明: '#'代表'id','div#list'表示"<div id='list'>",‘ dd’空格表示下一级
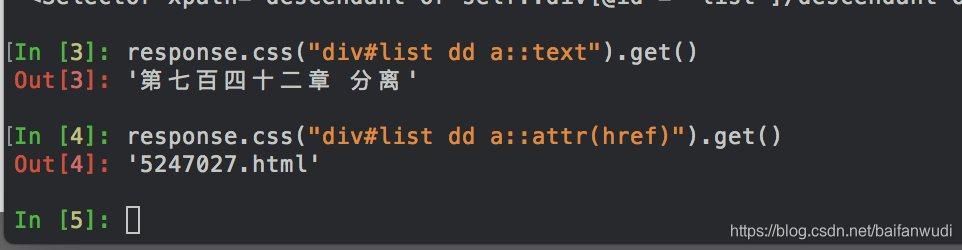
继续输入
response.css("div#list dd a::text").get()
response.css("div#list dd a::attr(href)").get()
### a::text表示取 <a href="5247027.html">第七百四十二章 分离</a>的文字
### a::attr(href)表示取href的值。
可以看到结构
一定要用scrapy shell命令和chrome去分析,自己写的解析命令对不对。
在sipders目录下新建一个yuanzun.py文件
import scrapy
class YuanZun(scrapy.Spider):
name = "yuanzun"
start_urls = ['https://www.booktxt.net/6_6453/']
def parse(self, response):
for quote in response.css("div#list dd a"):
next_page = quote.css("a::attr(href)").get()
yield {
'url:': next_page,
'name:': quote.css("a::text").get()
}
终端运行命令
scrapy crawl yuanzun -o content.json
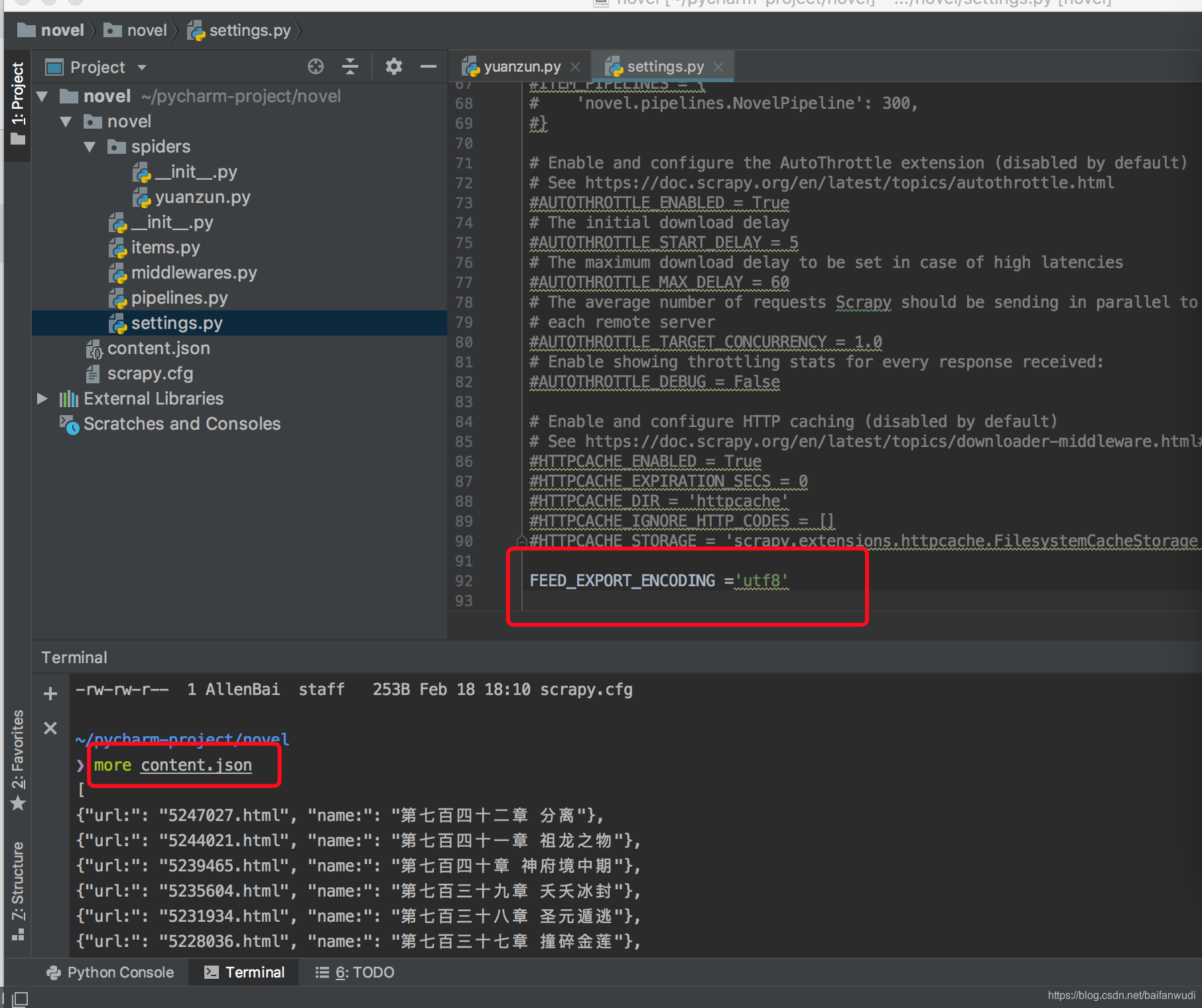
发现结果中文乱码,在settings.py里加(我的是mac,windows应该是GBK)
FEED_EXPORT_ENCODING ='utf8'
参考文档:
https://docs.scrapy.org/en/latest/intro/tutorial.html#creating-a-project
https://www.booktxt.net/6_6453/
https://blog.csdn.net/weixin_42600599/article/details/85090016
https://blog.csdn.net/dangsh_/article/details/78617178